Linux Server-Side UDP Network Programming: Zero-Loss Hot Upgrade
Starting from a difficult urgent requirement years ago, this post introduces the Established-over-unconnected technique. It discusses UDP network programming on Linux servers, how to implement a truly zero-loss hot upgrade, the pitfalls across different kernel versions, and how TCP and UDP packets are matched to sockets inside the kernel.
Starting from an Urgent Requirement Years Ago
What Happened
About four or five years ago, I took over a very urgent feature requirement. The task was to implement zero-loss hot upgrade for an NGINX-based streaming media server that distributed traffic using a UDP-based transport protocol. More precisely, I had only a few days to complete design, development, regression testing, and canary rollout for a complex feature.
Some readers may already be frowning. Why do something like this in such a short time? Can quality be guaranteed? The only answer is that many work projects are tied to timing. If such a project is even one day late, it may miss its opportunity and lose its original value. I am just stating a fact here, not saying I agree with it. As for why I dared to accept this challenge, the reason was simple: I had previously implemented TCP streaming hot upgrade, so I felt confident. I thought this was another chance to show off. Just go for it.
Unfortunately, after rushing through design and development, I got stuck in regression testing. On one test machine, the zero-loss hot upgrade feature behaved incorrectly. In the pre-production environment, it worked fine. I remember that more than half the time had already passed, and the last release window was the next day. Missing it would mean I failed the project.
In many cases, whether a project succeeds depends heavily on non-technical factors and later stability. It is rare for a project to fail because of implementation details. At that time, I was getting into a good rhythm as an engineer, and I could not accept that kind of failure.
After debugging the whole night with a dizzy head, I still did not have a clear conclusion. If the feature might have hidden risks, it definitely could not be launched carelessly. But the release window was tomorrow. What should I do?
Well, I have never believed in individual heroism. There were many senior engineers in the team, and I had no reason to bury my head and guess alone. I directly started an emergency meeting and pulled in several experts I knew. I also shamelessly said that we would debug the problem live in the meeting, and if there was no result, I would not end the meeting. Please be mentally prepared.
Just after I explained the feature background and the issue I was seeing, a senior engineer interrupted me and asked: what Linux kernel version is the problematic test machine using? I was confused. I said: how could this be related to kernel version? It should be my problem. Don't throw it onto the kernel. He smiled and said: it matters a lot.
Sure enough, every problematic machine used kernel 4.19, while the machines that did not reproduce the issue used kernel 3.10. He told me: go ahead and release. Production is on 3.10. The UDP zero-loss hot upgrade feature will be fine.
At this point, the details may still be unclear. What is zero-loss hot upgrade? Why would whether a UDP-based transport protocol works during hot upgrade be related to the kernel version? What does UDP network programming look like? I will answer these questions below.
This post is also meant to further explain one difficulty mentioned in the previous post: in a multi-process server architecture, how do we ensure UDP packets are matched to the process that owns the connection session? This is one of the hard parts of UDP network programming. Note that even in a multi-threaded server program, once hot upgrade creates multiple service instances as different processes, the same problem appears.
NGINX Zero-Loss Hot Upgrade
There are already many NGINX resources, and the official documentation is detailed, so I will focus on the part we need. During NGINX hot update, whether reload or upgrade, the essence is that new processes are created to serve new requests. Old processes start closing listening sockets and only continue serving old requests from before the hot update, until all old requests finish normally or the graceful-exit timeout is reached.
What limitation does this official approach have? Normally, NGINX is used as a reverse proxy. Requests are proxied to upstream origin servers, and NGINX forwards upstream responses back to the original clients. In that case, the official hot-upgrade approach has no issue. Every request hitting NGINX independently initiates an upstream request, and new and old processes coexisting does not affect those requests.
But what if NGINX itself is the origin server? Third-party NGINX modules can work this way. A famous example is nginx-rtmp. In streaming distribution, there are producers and consumers. If hot upgrade happens and the producer is in a gracefully exiting old process, later requests cannot hit the producer in that old process.
Zero-Loss Hot Upgrade in a TCP Multi-Process Architecture
The solution is intuitive: let new requests hitting the new process also access the producer in the old process. More precisely, find a way to move the producer from the old process to the new one.
We considered two approaches. The first, which we thought of earlier, was a bit tricky: pass file descriptors between processes. I will discuss that mechanism later. The idea was to pass the producer's file descriptor and core session state to the new process, then reconstruct the producer session there so it could serve new requests. The biggest problem was that version changes could make session reconstruction fragile, causing serious difficulty for later iteration and maintenance.
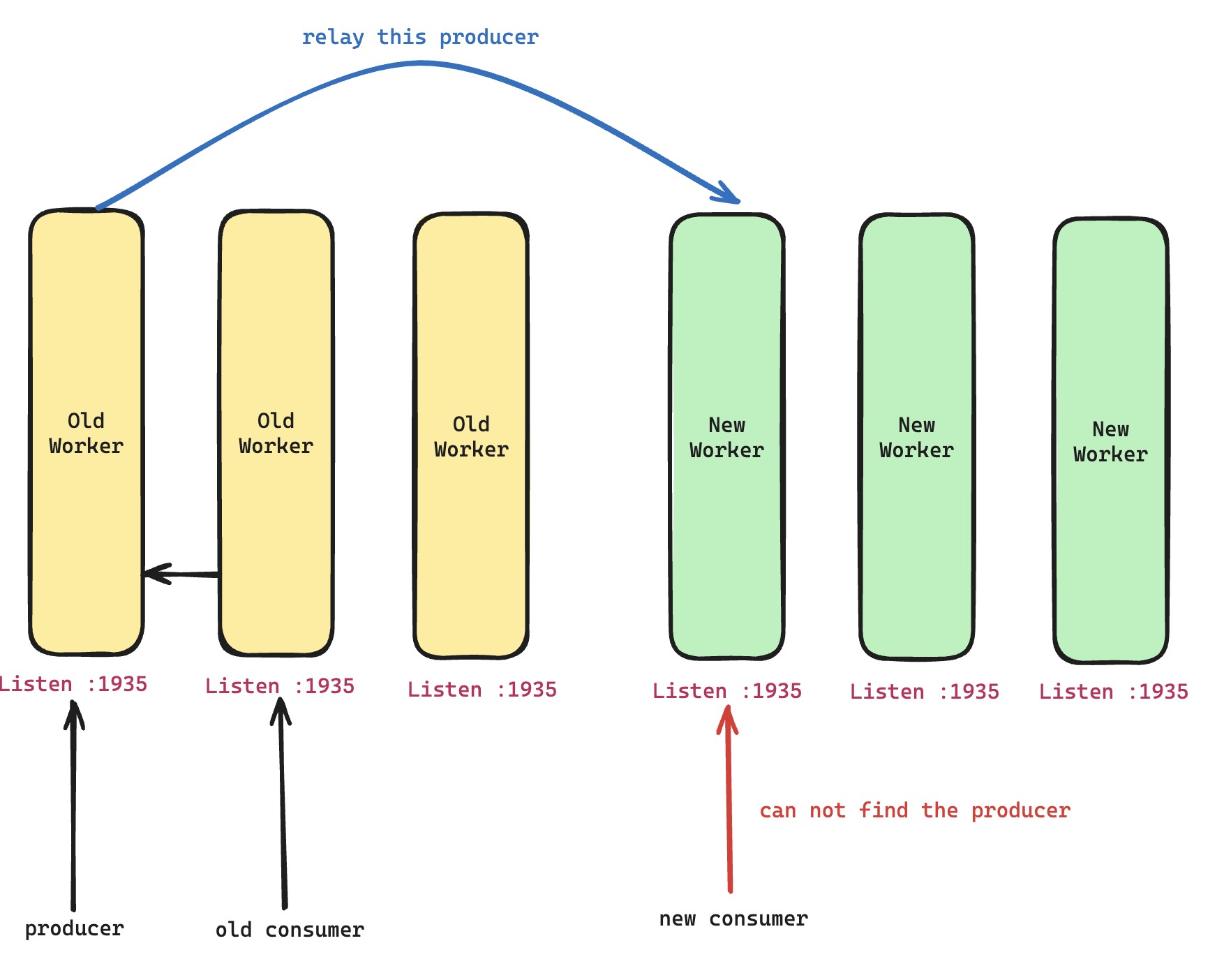
So we quickly switched to the second approach, shown in the diagram above: let the producer forward a copy of real-time data to the new process. The new process then effectively has its own producer to serve new requests. This solution looks plain, but it works very well. Sometimes plain really is best.
For TCP, as mentioned above, the old process closes its listening TCP socket, which means it no longer accepts new requests. It can then actively create a forwarding request to the new process's listening address. But for UDP, there is not even a concept of a listening UDP socket in the same sense. In many implementations, even many UDP-based transport connections may all share one UDP socket. This creates two problems.
- What should server-side UDP socket programming normally look like? Especially in a multi-process architecture, how do we ensure a connectionless UDP socket held by a process can receive packets belonging to the UDP-based transport sessions owned by that process?
- How can an old UDP server process reject new requests while not affecting old requests it is already serving? In other words, how can a UDP-based transport protocol implement normal NGINX-style hot upgrade? Only after this core function exists can we discuss a zero-loss hot upgrade scheme.
UDP Socket Network Programming
After all that background, let's look at how UDP sockets should be used to solve those problems.
What Is Behind a Socket?
Linux has a core design idea: everything is a file. A network socket exists in user space as a file descriptor, which is just an unsigned integer. But we all know that behind this simple file descriptor there must be complex transport-layer session state, especially for TCP sockets. After writing a Rust toy project like feather-quic for so long, we know how complex a real production-tested transport stack can be.
Let's take a first look at how the kernel links and manages state behind sockets. I am not a kernel developer, only someone who occasionally reads the code, so my understanding may be imperfect.
First, a file descriptor in a process's user space points to the file array held by the process. A network socket corresponds to struct socket inside the file structure. To me, this represents the kernel's socket-layer implementation. Its core member sk points to the real transport-layer session state, struct sock.
user space fd
v (task_struct->files_struct->fd_array[fd])
struct file
v (file->private_data)
struct socket -> (socket->proto_ops)
v (socket->sk)
struct sock -> (sock->proto)
The diagram sketches the kernel data structures behind a network socket. The key point is that struct socket, as the socket layer, holds the proto_ops callback table. We can clearly see familiar socket-related system calls there. TCP sockets register inet_stream_ops in proto_ops. UDP sockets register inet_dgram_ops. inet_dgram_ops registers far fewer callbacks. Operations such as listen and accept are not implemented, which makes sense because UDP sockets are not connection-oriented.
Looking deeper, many of these registered callbacks call into the core callback table held by struct sock, struct proto. My understanding is that struct socket provides an abstraction so TCP, UDP, SCTP, and other protocols can expose mostly consistent socket system calls in the kernel. The real implementation of those calls is completed by callbacks implemented independently by each transport layer, such as TCP's tcp_prot and UDP's udp_prot.
Similarly, struct sock is an abstraction of each transport-layer implementation's context data structure. The real TCP stack context is held by struct tcp_sock. This uses a common C technique: the first member of tcp_sock is actually struct sock, forming a composition relationship and making type conversion efficient.
This reminds me of a senior engineer who once told me that if I really wanted to learn kernel protocol-stack development, I could try implementing KCP inside the kernel. It has little practical value, but it is a good practice project. I was tempted several times, but never actually did it.
How TCP Implements Connection-Oriented Behavior in the Linux Kernel
Leaving aside congestion control, flow control, reliability, and other core TCP features, let's only look at how TCP implements connection-oriented behavior in the Linux kernel. We will not discuss the protocol design of TCP connection orientation here, because earlier posts covered that several times.
Simply put, everyone knows TCP relies on the four-tuple to identify a unique connection. So let's look at how the kernel, after processing data at the IP layer, delivers a TCP packet to the session state that owns the connection, meaning to the corresponding tcp_sock, and then based on TCP stack processing, whether it should wake the process holding that tcp_sock.
| Hash table | Key | Value | Matching logic |
|---|---|---|---|
established-hashtable | Local IP, local port, remote IP, remote port | Established sockets, TCP_ESTABLISHED and later | Exact four-tuple match |
bind-hashtable | Local port | All sockets bound to that port | Matching local IP and local port |
listening-hashtable | Local port, or local IP plus local port | Sockets in TCP_LISTEN | Matching local IP and local port |
Everything here is data-structure design. As shown in the table, the TCP kernel stack maintains three global hash tables. They ensure global TCP socket states do not conflict and that IP-layer data is delivered to the correct tcp_sock.
Before explaining the details, one point is worth noting: these global hash tables are all stored in inet_hashinfo, which is held by struct net. This relates to the implementation of Linux Network Namespaces. If network-layer isolation is needed, these core global data structures must be maintained separately. I will not analyze that further here.
Now let's look at which system calls use these hash tables in a traditional TCP client-server scenario.
On the server side, the server creates a listening socket, calls bind and listen, waits for readable events, calls accept for new requests, then reads and writes on the new socket. The bind system call queries bind-hashtable to ensure the local IP and port do not conflict with other TCP sockets. Many of us have seen bind fail because a port or address is already in use. That is bind-hashtable quietly doing its job. The listen operation adds the socket to listening-hashtable, so later incoming traffic can notify the process holding that listening socket.
On the client side, a TCP client usually creates a socket and directly calls connect with the server's address and port. TCP's three-way handshake is started inside connect. Only after the handshake completes does the kernel put the connected tcp_sock into established-hashtable using the unique four-tuple. But connect also determines the four-tuple before the handshake. Since the server IP and port are fixed, it performs something similar to bind: it locks a unique local IP and port combination for the TCP socket. The IP address is usually selected from the route table based on how to reach the server address. The local port is selected by using bind-hashtable to quickly check for conflicts. This is why clients usually do not need to call bind themselves. The client is the active side, the local port is not predetermined, and making users choose it manually would be painful. The kernel handles it during connect.
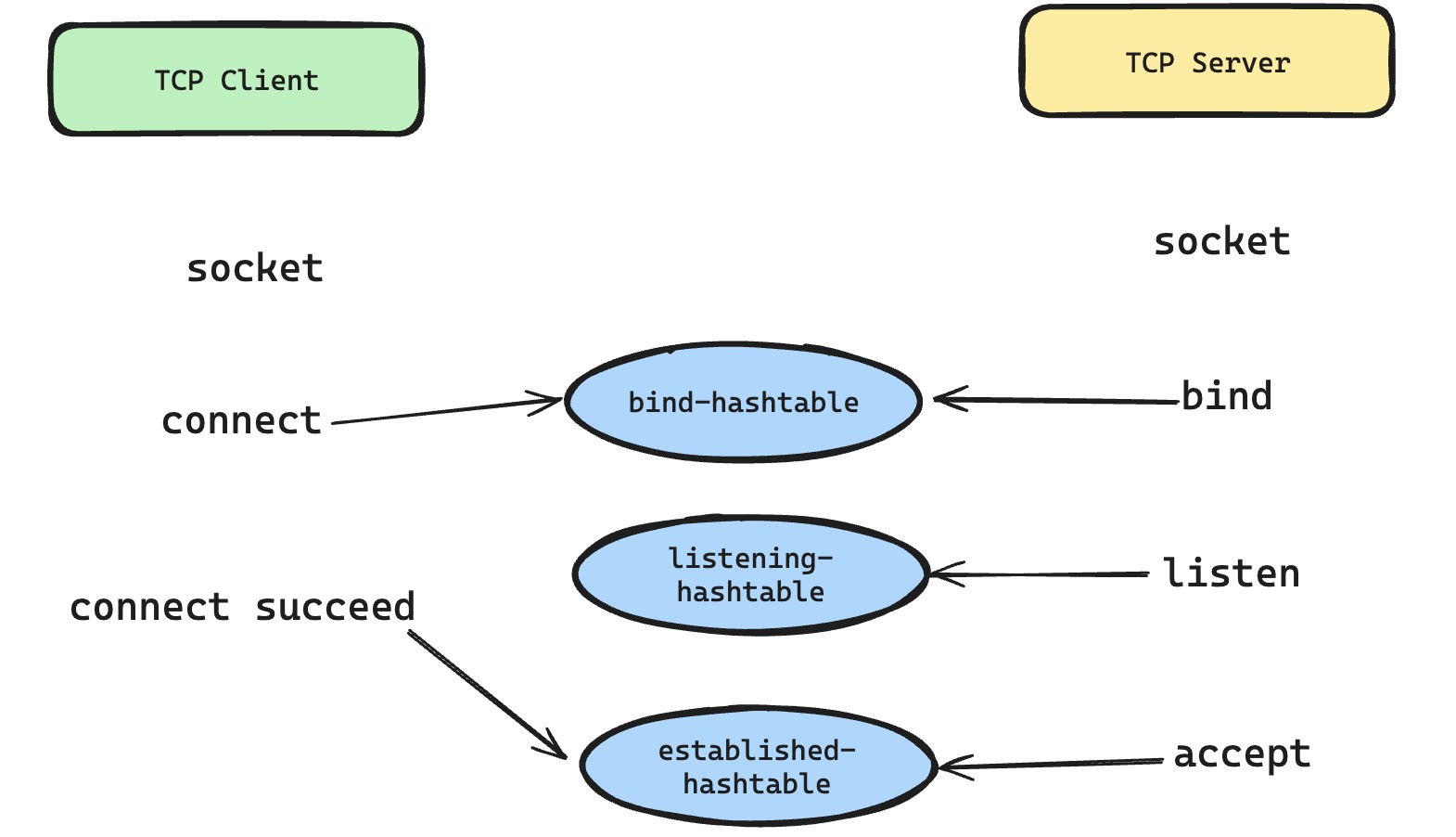
Finally, when the kernel handles a TCP packet passed up by the IP layer, the logic first queries established-hashtable to see whether the packet matches an established TCP session. If not, it continues searching listening-hashtable to determine which listening socket should handle the connection request. I wondered why it checks established-hashtable first instead of first checking whether the packet is a handshake packet and then going to listening-hashtable. My guess is that four-tuple lookup is efficient and can quickly decide whether a TCP packet belongs to an existing connection. Also, if a connection is already established, some delayed handshake packets may still arrive, and this avoids extra special-case handling.
Established-over-unconnected
After all this background, we can finally discuss how to support connection-oriented UDP-based transport protocols on top of connectionless UDP sockets, especially the hot upgrade problem above. This section title is Established-over-unconnected, a name I saw in a Cloudflare blog post. The technique itself has existed for a long time. I will not do archaeology here because I do not know who first invented it.
The essence is to simulate TCP socket operations such as listen, accept, and connect on UDP sockets. These operations respectively represent creating a UDP socket responsible for listening, the server obtaining a UDP socket for a new request connection, and the client creating a UDP socket that initiates a new request. This means we no longer use one UDP socket to receive all traffic and distinguish sessions by the UDP-based protocol's own connection identifier. Instead, we create different UDP sockets to handle different traffic.
As before, start with kernel data structures. At the struct sock layer, if the created socket is UDP, the real structure is udp_sock. udp_sock is much simpler than tcp_sock, because UDP does not provide as many features as TCP.
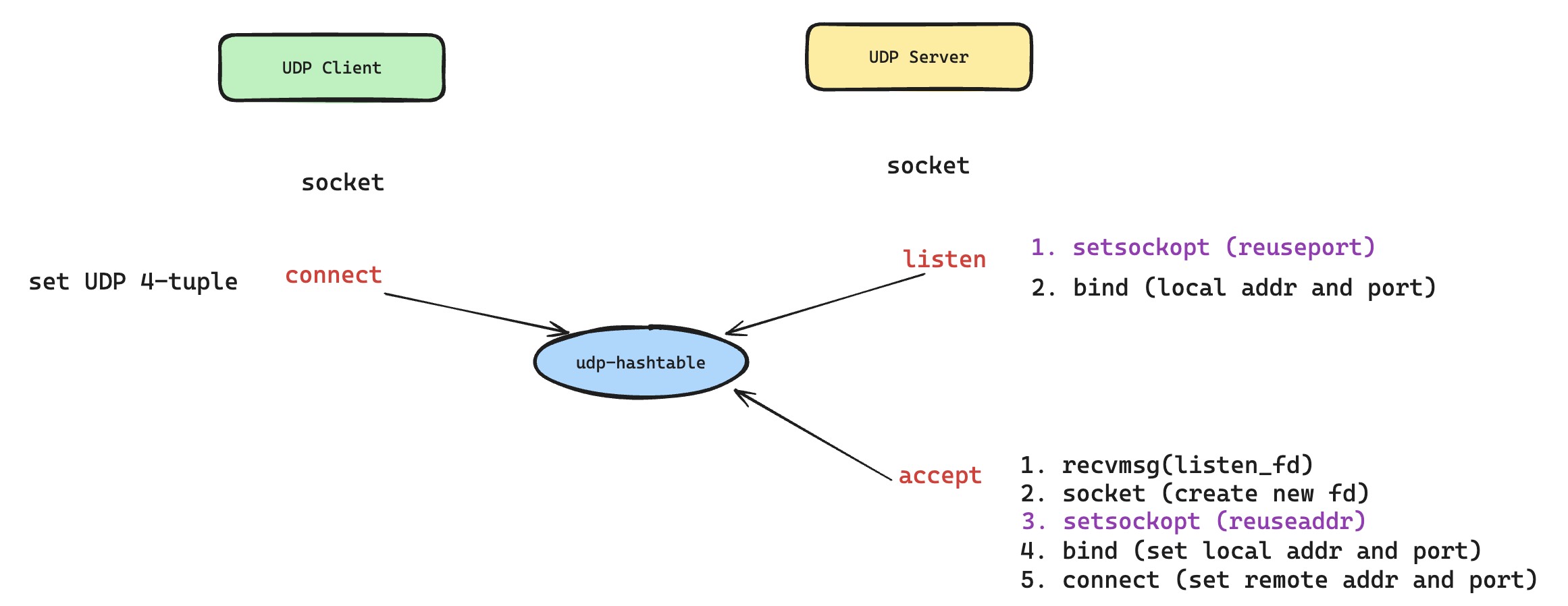
How does the kernel manage these udp_sock objects? How does it match UDP datagrams passed up by the IP layer to the process socket holding the correct udp_sock? The implementation is similar: the kernel maintains UDP hash tables. But in udp_table, there is no listening-hashtable or established-hashtable, because UDP is not connection-oriented by design. So the kernel performs udp_sock lookup based on udp_table, using the UDP datagram's four-tuple information to match the packet to the correct, or at least desired, UDP socket.
The next step is to give a newly created UDP socket a place in the UDP hash table, so it can receive the specific UDP four-tuple traffic we want. We can use UDP socket bind and connect to assign four-tuple information to the struct sock behind the UDP socket. Then the kernel's UDP packet matching logic can deliver specific UDP four-tuple packets to the new UDP socket. UDP socket connect does not trigger a TCP-style three-way handshake. It simply assigns non-conflicting four-tuple information.
To simulate a TCP listening socket, a UDP socket only needs to bind the local address and port. As long as the kernel lookup logic prioritizes four-tuple matching and falls back to local two-tuple matching, similar to TCP packet dispatch, the whole process can work. The implementation is shown below. We can clearly see how UDP sockets simulate TCP's listen, accept, and connect.

The benefit is obvious: the hot upgrade problem finally has a solution. After hot upgrade, the old process only needs to close its listening UDP socket. New requests, meaning new UDP four-tuple traffic, will be assigned to the listening UDP socket held by the new process. The new process then creates the corresponding UDP socket based on the four-tuple, which is the simulated accept, and uses that UDP socket to serve the new request. The old process can continue serving existing UDP four-tuple sockets normally. To implement further zero-loss hot upgrade, the producer in the old process only needs to initiate a request to the new process and establish a forwarding channel. Everything looks beautiful.
But things are not that smooth. This implementation meets many difficulties.
First, one obvious drawback is that the UDP-based transport protocol becomes tied to the UDP four-tuple. In reality, protocols such as QUIC do not use the UDP four-tuple as their connection identifier at all. The previous post discussed QUIC connection migration. If we implement things this way, doesn't migration completely stop working?
Actually, it is not fully tied to the UDP four-tuple. In a multi-process architecture, after the listening UDP socket receives data for a new UDP four-tuple, it can inspect the connection identifier in the UDP payload and whether the packet is a protocol handshake packet, then decide which process truly owns the session and forward the data there. If connection migration really happens, that session can create another new UDP socket, set the new UDP four-tuple on it, and ensure later traffic on the new path is received directly by that session.
You may already sense that the real challenge is not just handling these abnormal scenarios. The real challenge is that the whole mechanism fully depends on the kernel's UDP datagram matching implementation, and the Linux kernel gives no guarantee here. UDP has never had a connection-oriented design. The kernel comment also hints that this was not the intended use case. In other words, this solution is inherently tricky, and that naturally has a cost. When I implemented hot upgrade, I stepped straight into the pit.
How Multiple Processes Can Hold the Same Socket
Before digging into the kernel UDP datagram matching details, we need to discuss another question: how can multiple processes hold a socket listening on the same address? The bind-hashtable mentioned earlier blocks this. Whether TCP or UDP, it does not normally allow multiple sockets to bind the same local address and port. Why do multiple processes need to listen at the same time? Essentially, multi-process or multi-threaded servers use multiple CPU cores. That topic can easily drift into multi-threading versus multi-processing, so I will stop there.
A traditional solution is parent-child process inheritance. More specifically, the parent process creates the listening socket, then forks multiple child processes. Each child process shares that listening socket. Long ago, in UNIX Network Programming, Volume 1, I also saw another solution: use sendmsg and recvmsg with the SCM_RIGHTS control message to pass file descriptors between processes. Newer Linux kernels even provide a dedicated system call, pidfd_getfd, to make file-descriptor sharing between user-space processes easier.
These approaches look different, but their essence is basically the same. Based on the socket data structures described above, we can say it more precisely: each child process increments the reference count on the struct file, which means the kernel-side socket state behind the descriptors, such as struct sock, is fully shared by those processes.
Thundering Herd
If several processes all hold the same listening struct sock, what happens when a new request arrives? Which process should the kernel wake up? This is the old thundering herd problem. I will not repeat its disadvantages. I will only briefly describe the Linux solution when multiple processes hold a listening socket.
Linux introduced WQ_FLAG_EXCLUSIVE for accept by default in kernel 4.5. When a new TCP request arrives, not all processes blocked in accept are woken. Only the first process in the wait queue is woken, according to the relevant code.
One important point is that few server implementations still block directly in accept waiting for new requests. Most use the epoll + non-blocking I/O multiplexing model. epoll has its own solution for this herd problem. The listening socket registered in epoll must explicitly set the EPOLLEXCLUSIVE flag through epoll_ctl. Then, when epoll adds the wait queue, it sets WQ_FLAG_EXCLUSIVE, ensuring only the first process is woken to handle the new request. The UDP simulated-listening-socket scheme above can benefit from this too.
This approach has flaws. It always wakes the first process in the wait queue, basically FIFO scheduling. That does not ensure fair distribution among processes. Another more serious issue is that multiple processes all holding the same underlying struct sock for listening inevitably creates lock contention, hurting performance.
I have not even mentioned application-layer solutions, such as NGINX's old accept_mutex. It introduced lock competition so the listening socket would only be registered in one process's epoll events at a time. Each process took turns handling new requests. This solved thundering herd and also handled load balancing: if a process's load exceeded a threshold, it would give up lock competition and no longer add the listening socket to its epoll. But this was a compromise. It was not as clean or efficient as solving the problem in the kernel, and it has long been deprecated.
Reuseport
So there is a cleaner answer for sharing listening sockets: let every process hold its own independent listening socket without interfering with others. This is where Reuseport comes in. Both TCP and UDP support Reuseport in the kernel, and multi-process server implementations usually prefer it to handle new requests efficiently.
First, Reuseport allows different processes to create independent sockets that can all bind the same local address and port. That means Reuseport must bypass the bind-hashtable restriction in the bind system call path. Then the kernel's problem changes. It is no longer which process should be woken for a new request. It becomes which listening struct sock session should receive a new four-tuple packet. The kernel packet lookup logic must adapt specially for Reuseport, ensuring that all sockets with Reuseport enabled are strictly distributed according to the four-tuple hash.
One additional note: Established-over-unconnected changes slightly here. You may have wondered why a new connected UDP socket can bind the same local address and port as the listening socket. Now it is clear: listening sockets use Reuseport to share the listening address, while the newly connected UDP socket uses Reuseaddr to make bind succeed. Reuseaddr is not as complex as Reuseport, but it also helps sockets bypass bind-conflict restrictions.
Finally, four-tuple hashing looks fair, but in real production it may still cause load imbalance. The four-tuple does not include business attributes. If a hot flow refuses to leave, there is little you can do. Consistent hashing has similar flaws. In such cases, true load balancing is impossible.
TCP and UDP Packet Matching in the Linux Kernel
Now we can truly analyze packet matching at the Linux transport layer.
As mentioned earlier, TCP packet matching prioritizes established four-tuples. If that lookup fails, it checks whether any listening socket can handle a new request. In other words, TCP strictly searches established-hashtable first, then listening-hashtable. Reuseport only needs special adaptation inside listening-hashtable.
UDP packets only query their own udp-hashtable. There is no guarantee that a UDP packet will always first match a socket with a fully identical four-tuple, then fall back to a socket matching only local address and local port, the so-called UDP listening socket above. However, Established-over-unconnected depends entirely on this logic, and that logic is fragile across many kernel versions. Reuseport also made many changes to UDP lookup logic, introducing more uncertainty.
Code Analysis
Below I compare a few kernel versions. This is not a full commit history. I only care about the behavior in those versions. To know exactly when each change was introduced, we would need to find the commits one by one. I am a bit lazy and did not do that.
Kernel 2.6
Let's start from an older Linux kernel version because it is easier to understand.
For TCP, established-hashtable lookup is straightforward four-tuple hash lookup. For new requests that are not found there, the listening-hashtable lookup logic is the part we need. It clearly uses the packet's destination port as the lookup key.
UDP lookup logic is basically the same. The udp-hashtable lookup logic also uses the packet's destination port as the hash key. But in later 2.6 kernels, an optimization introduced a new hash table, udp-hashtable2, using destination port plus destination address as the key. If the chain length of a hash slot in udp-hashtable1 exceeds 10, lookup switches to udp-hashtable2 to improve efficiency.
So in kernel 2.6, UDP hash lookup has extra optimization, while TCP listening lookup does not. This is easy to understand. TCP listening lookup only happens during TCP handshake. TCP also has established-hashtable to guarantee lookup efficiency after connection establishment. But every UDP packet goes through udp-hashtable lookup, so it is easy to expose the problem of a hash table degenerating into a linked list. Yes, Established-over-unconnected has serious performance problems under high concurrency.
There are two kinds of sockets in the Established-over-unconnected technique. The simulated listening UDP sockets are few and do not hurt lookup efficiency. The sockets bound to new request four-tuples correspond one-to-one with requests, so high concurrency naturally causes performance problems. Note that the udp-hashtable2 optimization cannot solve this, because all these sockets use the same local address and port, the UDP listening address. Essentially, udp-hashtable2 does not change anything.
TCP listening-hashtable has a similar issue. Although only new handshakes query it, early Linux kernels set its size to only 32. If there are many different TCP listening sockets, listening-hashtable can also degrade into a linked list. Besides increasing hash table size, another approach is to reduce the number of listening sockets, for example listen on the wildcard address and let the application distinguish traffic itself. But this requires certain business configuration. Many blogs have described this performance issue. I will link the Cloudflare post as a reference.
Kernel 3.9
Around kernel 3.9, TCP Reuseport and UDP Reuseport were added close to each other. The core changes are in the lookup and matching logic discussed above. I will not dig into TCP bind logic changes here. Also in this version, TCP listening-hash started using local address plus local port as the lookup key, because using local port alone was too inefficient.
The TCP matching logic and UDP matching logic are basically consistent. The code is a little tricky. Four-tuple matching has the highest priority, then local port plus local address matching has the next priority, and the code traverses every node in the chain. For sockets with Reuseport enabled, the stack computes a four-tuple hash and uses the hash value to load-balance among Reuseport listening sockets, as discussed above. From the code, the premise required by Established-over-unconnected is not broken: sockets with successful four-tuple matches handle packets first.
Kernel 4.6
Here the kernel optimized Reuseport, benefiting both TCP and UDP. The optimization introduced struct sock_reuseport to improve lookup efficiency. The idea is simple: trade space for time. A new reuseport group is maintained for fast lookup, storing all sockets that enable Reuseport and listen on the same local address and port in an array.
With this, hash-table lookup no longer has to traverse the entire chain every time. Once it finds a matching Reuseport socket in the chain, it can directly enter that socket's reuseport group and select by hash. As shown below, a new request has a new four-tuple and will not match the green sk. Once it matches the first red listening sk, it can skip matching the remaining red listening sk objects and directly use the reuseport group for fast four-tuple hash matching.
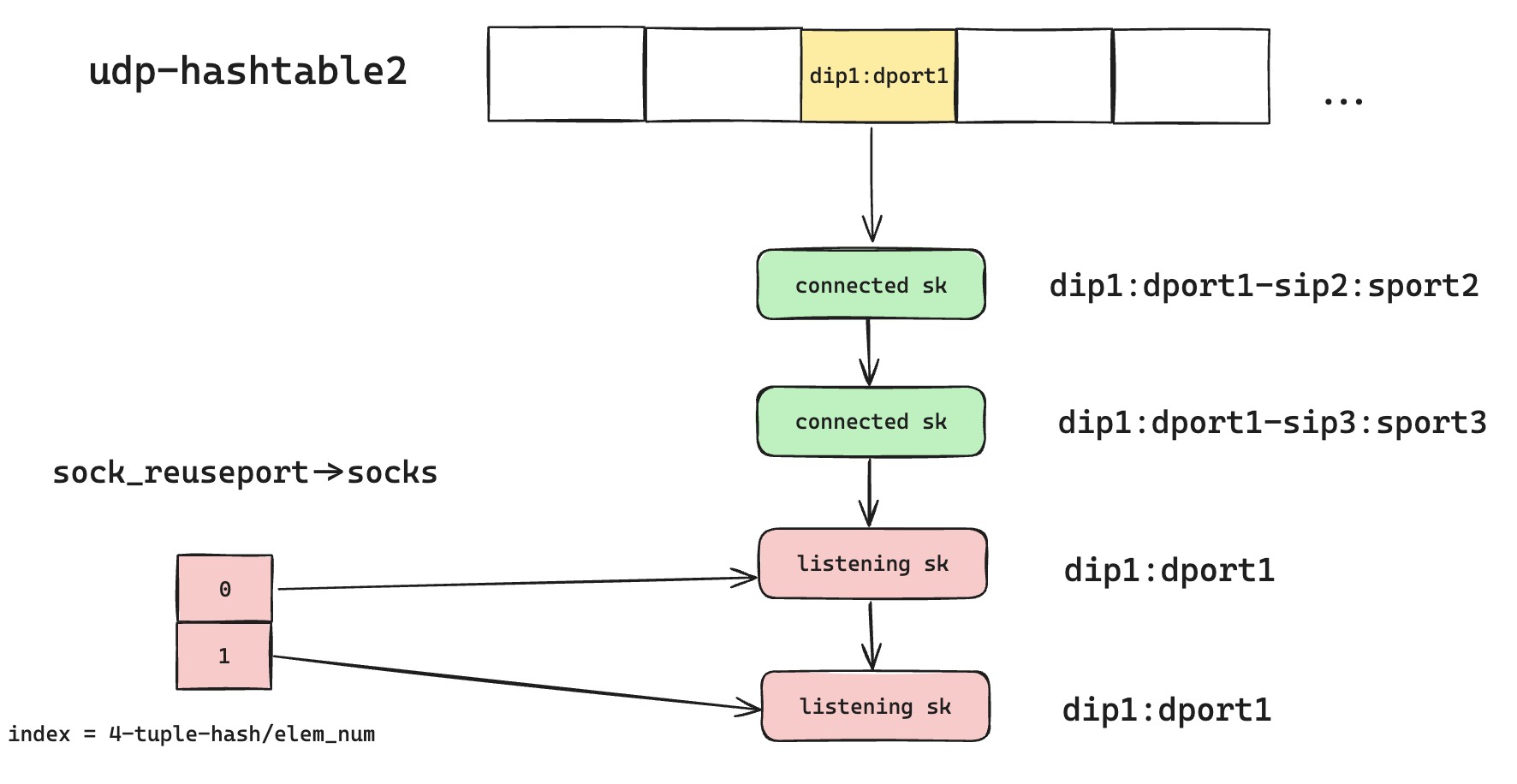
But this optimization is fatal to Established-over-unconnected. It breaks the fragile guarantee that four-tuple matching has highest priority and local two-tuple matching comes second. Looking closely, once the optimized logic meets a matching Reuseport sk, it returns immediately without continuing. In some cases, this is a fatal blow for the already connected green UDP sk.
For example, if a new Reuseport listening sk is created later, udp-hashtable2 can look like the diagram below. Under the optimized matching rule, a UDP datagram that originally belonged to the green sk partially matches the first red listening sk. Because Reuseport is enabled, the lookup returns immediately.
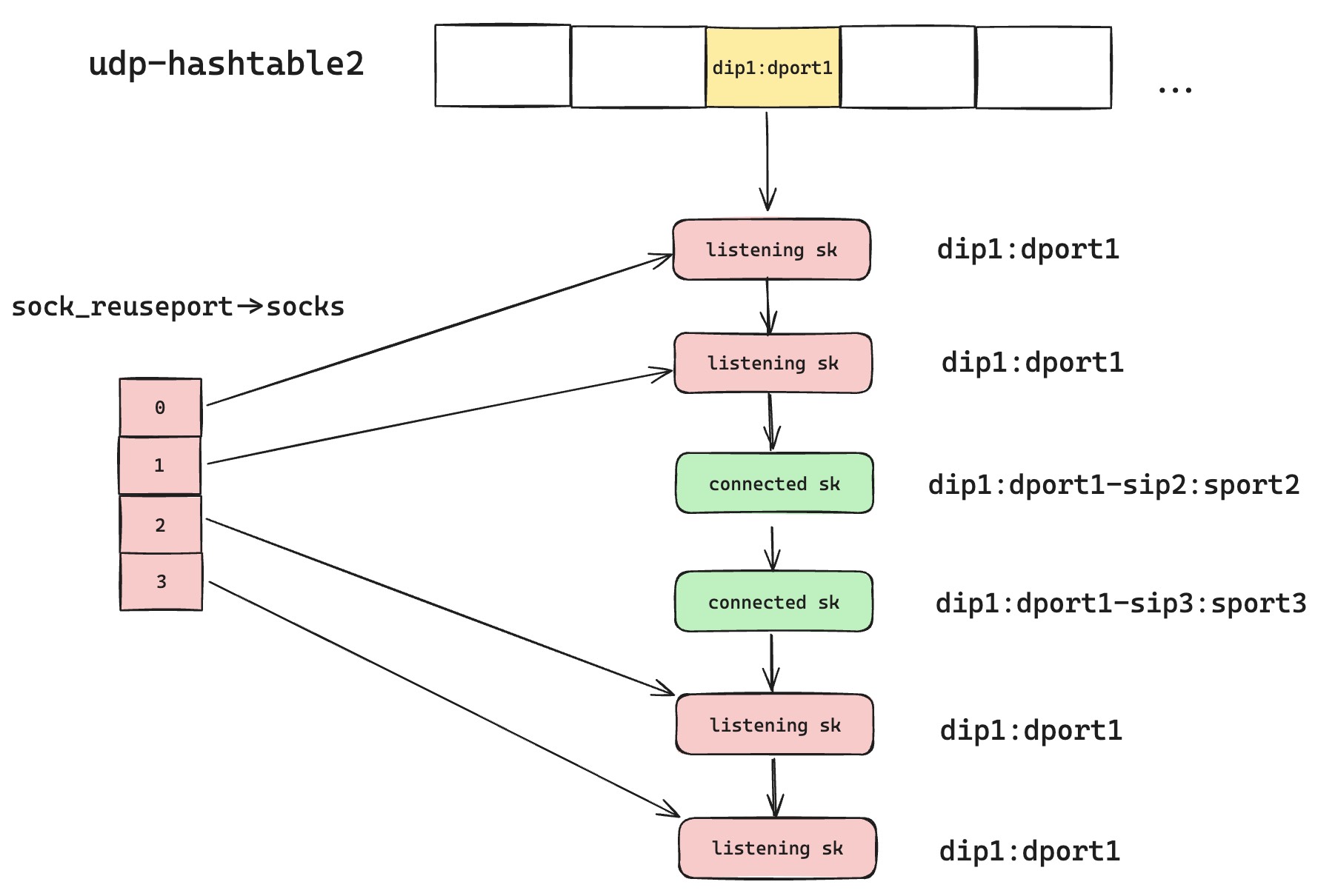
This scenario looks hard to hit, but my hot upgrade feature stepped exactly into this pit. UDP hot upgrade used both Reuseport and Established-over-unconnected. Newly started processes create listening sk objects again. Existing old requests still served by the old process can no longer receive packets. Their packets are assigned to a listening sk, possibly in the new process. This is why testing on kernel 3.10 worked, while on kernel 4.17 hot upgrade caused old requests to break.
Kernel 6.1x
So what is the solution? Essentially, udp-hashtable needs something like TCP's established-hashtable. Last year, Linux finally upgraded udp-hashtable to hash by four-tuple. The patch is here. This kills two birds with one stone: it solves lookup performance problems and avoids matching the wrong socket, because four-tuple hashing makes it hard for connected sockets and listening sockets to collide again. Established-over-unconnected finally got a new life. Back then, we solved the problem by patching the kernel.
Special Notes for Established-over-unconnected
Leaving aside the problem above, this technique still has several pitfalls.
Creating a Connected Socket Is Not Atomic
As described earlier, for newly connected UDP sockets, we use bind and connect to add four-tuple information. After both calls complete, the socket with full four-tuple information can stably receive its UDP datagrams. But bind and connect are not atomic. During the gap between the two calls, some packets may be incorrectly matched to other sockets.
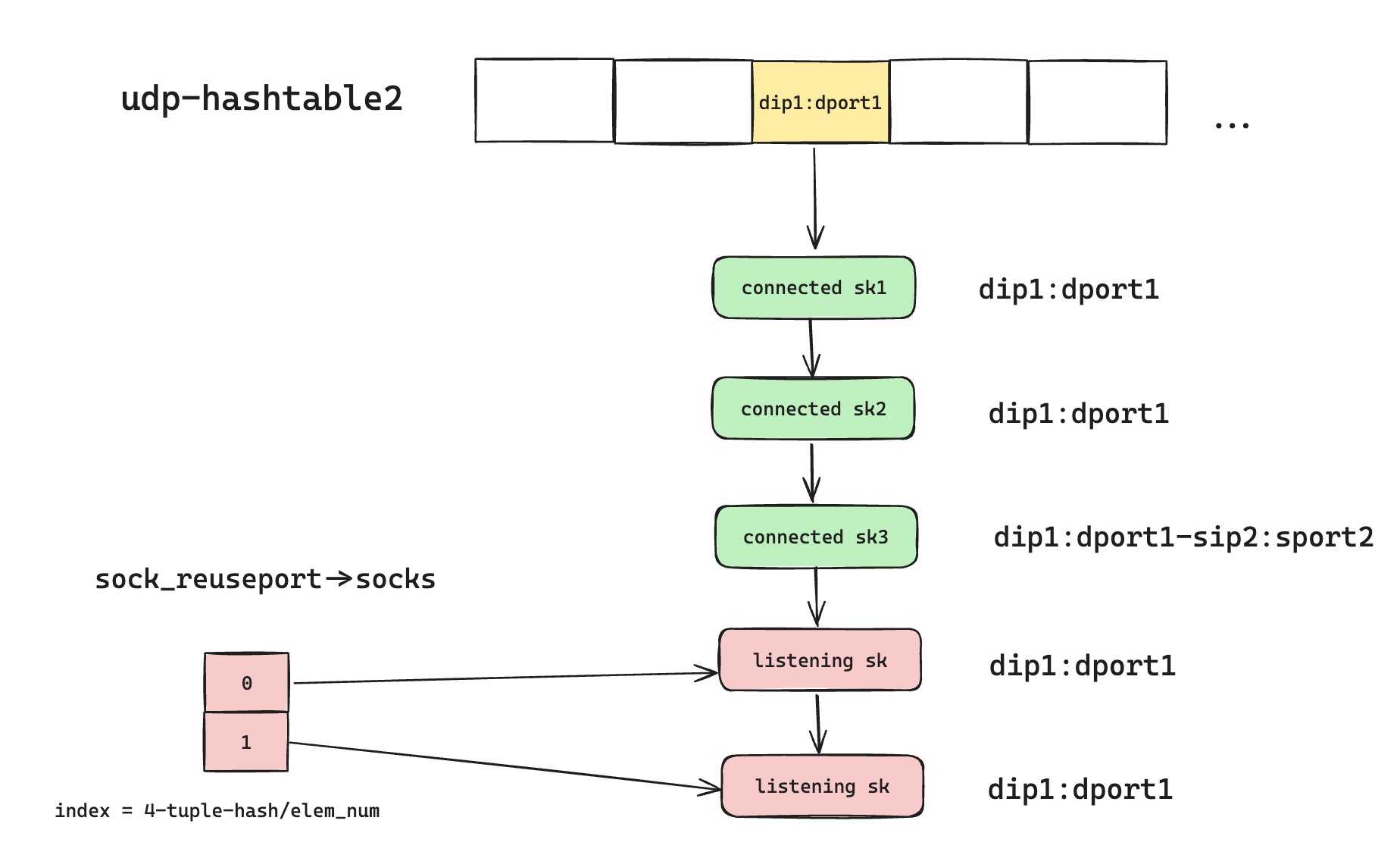
For example, if two processes are both creating new sockets and have only executed bind but not connect, udp-hashtable2 looks like the diagram. Packets belonging to sk1 and sk3 may still be assigned to listening sockets with Reuseport enabled. For this situation, the application layer needs special handling when receiving packets. A more aggressive approach would be extending kernel capability to support a system call that sets four-tuple information in one locked operation.
The Right Way to Use Reuseport
First, I want to emphasize: do not mix listening sockets where some use Reuseport and some do not. Keep them consistent. If someone does this, the matching logic becomes mind-bending. You have to read the matching code of the corresponding kernel version to know where packets end up. That means going further down the wrong road.
Another small detail: if there are multiple groups of Reuseport-array sockets, listening on different local address and port combinations, and hash collisions happen in udp-hashtable1 or udp-hashtable2, wildcard-address listening may cause more subtle behavior under the optimization introduced in 4.6.
Another core point: try not to change the size of the Reuseport socket array, even before the Reuseport Array optimization introduced in 4.6. The final Reuseport matching logic uses the four-tuple hash value to choose among all current Reuseport sockets. If the socket count changes, hash matching becomes completely different. dog250's blog gives some solutions. If the kernel already supports four-tuple lookup in udp-hashtable, simple synchronization for listening UDP sockets can avoid this problem.
Based on these notes, here is a subtle difference between NGINX and Tengine when they introduced Reuseport. Tengine's early implementation had each child process open its own Reuseport listening socket. Since Reuseport lets different processes bind the same address and port, this seems natural. During hot upgrade, old processes directly close listening sockets, and new processes create new listening sockets. This changes the Reuseport listening-socket array and scrambles hash matching.
For TCP Reuseport sockets, this may affect new requests. The listening socket maintains two queues: the SYN queue and the accept queue. If the listening socket being served is closed, its SYN queue is destroyed too, and requests inside the SYN queue fail. The client sends SYN, the server receives it, creates a req, puts it into icsk_accept_queue, and replies SYN+ACK. The icsk_accept_queue is tightly bound to the listening socket's sk. If that listening socket is destroyed, the queue is destroyed and req objects are dropped. Since the client is already in established state, it will not send SYN again.
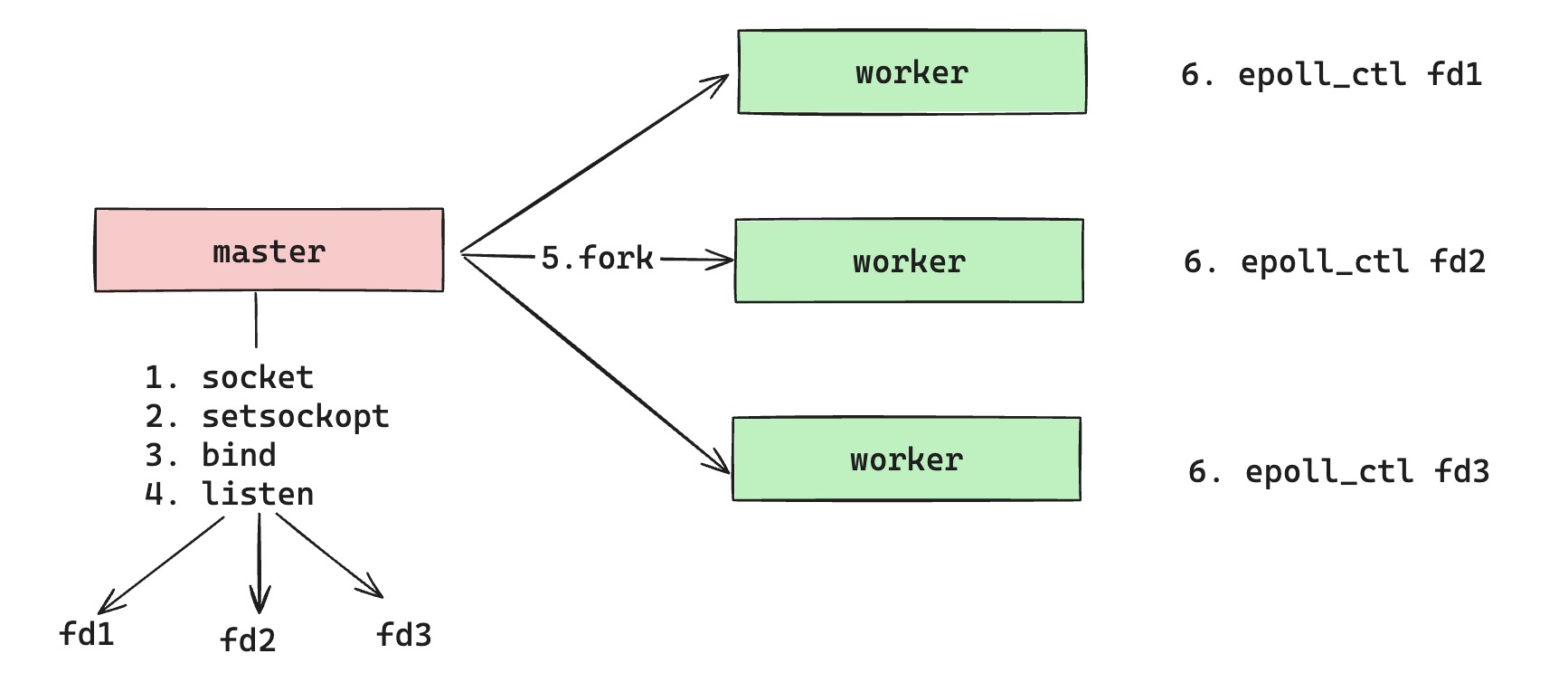
So what is NGINX's correct approach? It tries to avoid destroying listening sockets while still giving every child process its own independent listening socket. As shown above, it still uses parent-child process inheritance. The parent process uses Reuseport to create the same number of listening sockets as child processes. Each forked child process independently uses one of those listening sockets, corresponding to a unique sk in the kernel.
The key point is that during hot upgrade, the parent process spawns a new-version parent process using the original NGINX mechanism: it passes all listening sockets from the old parent to the new parent through environment variables. The new parent parses configuration and reuses those listening sockets, avoiding destruction and recreation. But this is not universal. In real production, changing the NGINX worker count can still delete listening sockets. So do not adjust the NGINX worker count in production unless necessary.
Epilogue
dog250's and Cloudflare's blogs have already described this series of issues, but I still wanted to write this post from a slightly different angle. I wrote a similar internal technical article at my previous company four or five years ago, but I think this version has a clearer story. While writing it, I wanted to give up several times because there were too many details and the thread was not always clear. It was painful to write.
Since it is so painful, should we avoid using Established-over-unconnected for UDP whenever possible? In many cases, yes. On one hand, the kernel itself gives no such guarantee, and subtle differences between kernel versions are painful. On the other hand, the previous post spent a lot of time explaining how UDP-based protocols escape the constraints of the UDP four-tuple. Now we are trying to match sk like TCP based on four-tuples again. That feels like missing the point.
Are there other solutions? Yes. There is an eBPF solution, first proposed by Facebook if I remember correctly. In short, it introduces an eBPF program into the core Reuseport lookup logic, allowing users to write eBPF code that selects the corresponding Reuseport sk based on UDP payload content. This achieves a very clean effect: all UDP-based protocol traffic can be matched to the correct socket according to the protocol's own connection identifier. In the next post, I will discuss the implementation details of this eBPF-based solution and share how I learned eBPF from scratch through it. Coincidentally, Cloudflare open-sourced a general eBPF-based UDP hot upgrade solution last month. I will study its code too, because I am curious how they implemented it.