Implementing QUIC from Scratch with Rust: Connection Migration
Before discussing connection migration, this post explains how QUIC implements connection-oriented behavior, then analyzes the design details of QUIC connection migration and compares similar ideas in other protocols, such as WebRTC Mobility. It also covers implementation scenarios in feather-quic and ends with thoughts on AI-generated code.
Connection Migration
What Is Connection Migration?
QUIC is a transport protocol built on UDP, but a QUIC connection is not tightly bound to UDP or lower protocol layers. This means that as long as the client and server state of a QUIC connection can keep running normally, the network layers underneath QUIC can change. The only requirement is that the new network path still allows the two QUIC endpoints to communicate.
In one sentence, the essence of connection migration is: QUIC decouples the connection from the network path. Changes to the UDP four-tuple do not break the QUIC connection.
How QUIC Implements Connection-Oriented Behavior
Choosing Connection Identifiers
This topic should have been discussed carefully in the earlier handshake post, but at that time I was too fascinated by the integration between QUIC and TLS and somewhat ignored it. Every transport protocol needs to solve a common problem: how to identify a connection, or what the connection identifiers are. TCP's connection identifier is the classic four-tuple formed by the IP addresses and ports of both endpoints.
Almost all UDP-based transport protocols on the market avoid using the UDP four-tuple as their own connection identifier. People probably realized that NAT devices are not very friendly to UDP. UDP mappings can easily be evicted from NAT tables, causing the UDP four-tuple to change. A transport protocol that relies only on the UDP four-tuple would disconnect because of that.
I do not think NAT devices deliberately target UDP. UDP is simply connectionless by design. Unlike TCP traffic, NAT devices can easily maintain TCP mappings by observing TCP handshakes and closes. When NAT resources are tight, prioritizing eviction of UDP mappings is a reasonable choice. We cannot expect NAT devices to understand every custom UDP-based protocol.
Going further, UDP-based transport protocols give up the UDP four-tuple as their connection identifier in exchange for a much wider design space, at the cost of a little extra bandwidth. The protocol connection is no longer tied to the underlying network path. Security can also improve, because traffic cannot be easily judged as belonging to the same connection purely through external information such as the UDP four-tuple. QUIC goes further by supporting connection migration and building a more complete design around connection identifiers. Let's look at how QUIC does it.
QUIC Connection ID Design
QUIC chooses QUIC Connection ID as its connection identifier. The Connection ID is split into two parts. Each side of a QUIC connection generates its own Connection ID. Only the pair of Connection IDs can accurately identify one unique QUIC connection, because QUIC connection state is maintained by both endpoints.
QUIC packet headers usually carry Destination Connection ID, while Long Header packets also carry Source Connection ID. One point worth clarifying is that the Connection IDs seen by the two communication sides are reversed. In other words, the Destination Connection ID carried by a QUIC packet is relative to the sender. From the receiver's perspective, it is effectively the Source Connection ID. This is similar to understanding local and remote IP addresses in normal TCP socket programming, so there is not much more to say.
Next, let's look at how the two sides negotiate Connection IDs during the QUIC handshake. This is normal protocol negotiation, and the RFC covers the details.
I missed one thing in my earlier implementation: I did not validate the Connection-ID-related Transport Parameter. The RFC explicitly requires it, so I should fix that. I still do not think this is a huge problem in my toy stack, because TLS already blocks man-in-the-middle attacks, and careful implementations should map different Connection IDs to new connections and new TLS handshakes. Still, the rule is there for a reason. A peer with sloppy Connection ID handling can create security problems.
Another important point is that, unlike many transport protocols, Connection ID is not unique throughout a QUIC connection's lifetime. More accurately, the connection identifier is not unique. I think this is a good design. It helps avoid traffic correlation, because Connection IDs cannot be encrypted. If a QUIC connection always used the same Connection ID, it would be easy for observers to identify whether traffic belongs to that connection.
QUIC maintains multiple Connection IDs through explicit sequence numbers. The Connection ID negotiated during handshake has sequence number 0 by default. If the peer sends the Preferred Address transport parameter, the Connection ID inside it has sequence number 1. Each later New Connection ID frame declares a new Connection ID and its sequence number. In the same New Connection ID frame, the peer can also retire previously declared Connection IDs through sequence numbers. The local side can also use Retire Connection ID frame to retire Connection IDs sent by the peer. Both sides can retire a Connection ID issued by one side. If the local side wants to switch to another Connection ID declared by the peer, it only needs to choose the new Connection ID when sending packets.
Connection IDs can do even more. It is natural to think about encoding extra information into them. That would enable many interesting things. However, the QUIC RFC explicitly says Connection IDs must not contain information that can be observed by external parties.
A long time ago, when I was watching an IETF online meeting recording, I saw a proposal that suggested adding extra information into QUIC Connection IDs so lower-layer network devices could make targeted path-selection or optimization decisions, improving transmission quality for high-priority QUIC traffic.
Because that draft partly broke the Connection ID requirement above, the video showed a long queue of people asking questions, mostly challenging its security and feasibility. If some standardized encoding rule inside Connection ID can improve transport quality, would everyone claim their traffic is highest priority? If all traffic is high priority, then there is no optimization. On top of that, exposing traffic priority is itself a privacy and security risk. Still, this approach might be suitable inside private data centers or internal transport networks, where everyone is expected to behave and the intended transport effect can be achieved.
Finally, the QUIC RFC also allows a Connection ID length of zero, meaning no Connection ID exists. In that case, QUIC connection identification can only rely on the UDP four-tuple. As discussed above, that makes a QUIC connection fragile and also imposes special requirements on UDP socket usage. But since the RFC mentions it, someone will probably try it, perhaps purely for learning.
Matching Packets to Connections
I am borrowing the title of QUIC RFC 5.2, because it names the problem well. The RFC mainly talks about matching QUIC packets to connections by Connection ID and handling abnormal packets. In real server engineering, this problem quickly becomes more interesting.
Matching QUIC packets to connection sessions mainly has two difficulties:
- In a cluster, how do we correctly forward QUIC packets to the machine that owns the connection session?
- In a multi-process service architecture, how do we correctly forward QUIC packets to the process that owns the connection session?
The first difficulty is more specific in normal cluster scenarios. A layer-4 load balancer forwards TCP or UDP traffic to backend machines based on the four-tuple. QUIC does not use the UDP four-tuple as its unique connection identifier. When connection migration happens and the UDP four-tuple changes, an ordinary load balancer may forward traffic for the same QUIC connection to different backend machines. That means the QUIC connection becomes unusable.
QUIC-LB provides a complete solution. It puts extra information into the Connection ID so the cluster entry load balancer can recognize QUIC packets and forward them to the correct machine. Someone may ask: didn't we just say not to put important information into Connection IDs because of security risks? Yes. But if the routing information is protected well enough that sniffers outside the cluster cannot infer the hidden rules, it does not violate the Connection ID security requirement.
One important detail: the mapping between Connection ID and backend machine should not live in a global mapping table. That would be too expensive and would create resource-attack risks. A better approach is an implicit routing rule. The load balancer reads the routing information carried by the Connection ID and computes the backend machine from that. Encrypting or otherwise protecting that routing information satisfies the QUIC RFC's security requirements.
The second difficulty is ensuring that when multiple processes all hold UDP sockets bound to the same address, the UDP datagrams carrying QUIC traffic are forwarded to the correct process, especially in special scenarios such as hot upgrade. I want to discuss this in the next post so I can cover mainstream industry solutions in more detail. One thing worth mentioning is that, while implementing connection migration this time, I deliberately removed the UDP socket connect system call. Otherwise the remote address stored in the UDP socket would be fixed, and the kernel would be unable to correctly deliver migrated UDP datagrams to the UDP socket held by feather-quic.
How to Implement Connection Migration
When Connection Migration Is Triggered
The QUIC RFC describes the trigger very clearly: connection migration happens either because one side of the QUIC connection actively switches the underlying network link, or because the existing forwarding network path changes by itself. Let's look at more concrete timing.
The first scenario is easy to understand. One side actively switches networks. A classic example: a user walks from indoors to outdoors or into an elevator. The phone can no longer maintain Wi-Fi, so the network switches from Wi-Fi to the carrier's 5G or 4G. Mature clients usually monitor network-interface changes and actively rebuild transport connectivity instead of foolishly waiting for network timeout. Because QUIC supports connection migration, the client does not need to rebuild the transport protocol from scratch. It only needs to keep sending QUIC traffic to the new address. The Connection IDs discussed above ensure that traffic whose underlying path has changed, more specifically whose UDP four-tuple has changed, can still arrive at the correct QUIC peer instance and be processed correctly.
This first scenario mostly happens on clients. Server network environments are usually stable enough that this is rare. More importantly, in most cases, clients do not have public IP addresses that provide services. If the server network environment changes and it wants to send traffic to the client again, that is basically impossible, because the client is behind NAT and trying to reach the old client address directly usually goes nowhere. Of course, if the connection originally used a NAT traversal P2P design, there may still be a chance. The endpoints could try to quickly complete NAT traversal again through an out-of-band signaling channel, but that is a difficult road.
QUIC also gives servers a preferred_address transport parameter. The server can use it to tell the client: I have another address, and I hope you migrate to it.
There is an obvious limitation: this parameter can only be sent during the handshake. If the connection has already been alive for a long time and the server later gets a new network address, QUIC has no transport-layer way to notify the client. If a product needs that, it has to add application-layer signaling. The RFC also does not say exactly when the client should begin migration to the preferred address after the handshake. That is left to implementations and product needs. Another detail: the RFC says QUIC connection migration can only happen after the handshake. My understanding is simple: after the handshake, communication is trusted enough to support migration.
The second scenario is the classic NAT rebinding case mentioned earlier. If a NAT device between the client and server updates the UDP four-tuple mapping, the server's QUIC stack usually detects it. The reason is the familiar one: normally only the server has a stable IP and port, and NAT devices are usually at the client's network exit. When NAT rebinding happens, the server sees the UDP four-tuple change, more specifically the peer IP address or port changes. After the server detects connection migration, it usually switches Connection ID and completes the required QUIC migration checklist, which we discuss next.
How QUIC Keeps Connection Migration Secure
When QUIC starts connection migration, what work needs to be done? Based on the design above, it may seem that the two endpoints do not need to do anything. The core role of Connection ID is to make QUIC connection-oriented, so traffic can reach the correct endpoints and be processed correctly. But we must not forget that security comes first in protocol design.
The core security question in connection migration is clear: after the network path changes, how do we trust the new path, and how can the whole process remain secure and efficient? Usually, risk prevention matters more for the passive side of migration, because it needs to confirm whether the new path can be trusted and whether future packets can be sent through that path. The active side chose the new path itself, so it has less to worry about.
This is similar to a question discussed earlier: what is the core purpose of a transport-layer handshake? The most important part is confirming that both communication parties are trustworthy. Without path validation, considering the old amplification-attack problem, an attacker could interfere with an active QUIC connection by forging packets and make a QUIC server forward traffic to a victim.
Someone may say: QUIC has Connection ID and TLS. The receiver can verify whether the Connection ID is valid and whether TLS decryption succeeds. AEAD can verify data integrity and authenticity through tags. Also, the QUIC RFC emphasizes that only non-probing packets with the largest packet number can trigger connection migration through UDP address changes.
Even with all this effort, security issues remain. If an on-path attacker takes packets from the current connection, maliciously changes the source address, and the modified packet arrives at the QUIC server before the original packet, the server can still be fooled into sending traffic to the victim. This creates an amplification attack and indirectly makes the real connection unusable or slower.
QUIC solves this mainly through Path Validation. QUIC defines two frames for path validation: PATH_CHALLENGE and PATH_RESPONSE. The process is simple. Either side can start validation by sending a PATH_CHALLENGE QUIC Frame carrying 8 bytes of random data. The peer returns a PATH_RESPONSE QUIC Frame carrying the same 8 bytes. Because an attacker cannot generate valid QUIC packets for the connection, this path-validation mechanism can confirm that the new path is trustworthy.
QUIC also recommends switching to a new Connection ID during migration and retiring the currently used Connection ID. If the peer notices this, it usually declares new Connection IDs again for future use. Note that this Connection ID switching mechanism is not mandatory, otherwise it could not handle migration caused by middle-path changes. In NAT rebinding, the client usually has no idea what happened, so it cannot know to switch Connection IDs. Only when it sees the server start path validation might it cooperate and switch, but even that is not required.
Work Beyond Security
After connection migration, besides path validation and Connection ID switching, what else does QUIC need to do? This is easy to infer. The network path may have changed, so RTT and congestion-window data measured on the old path are no longer valid. Path MTU may also have changed. After path validation succeeds, QUIC needs to reset RTT and congestion-control state, re-estimate them, and perform MTU discovery again. So we should be clear that connection migration has a cost and may briefly affect performance.
Similar Ideas in Other Protocols
WebRTC Mobility
QUIC is not the only protocol with a connection-migration design. WebRTC has a similar idea called Mobility. In the same trigger scenarios described above, WebRTC can also recover quickly and keep a video session running.
WebRTC video sessions are usually established through ICE. You could even say WebRTC's connection-oriented behavior is protected by the Candidate Pair negotiated by ICE. Generally, ICE negotiates three possible network connection types for WebRTC: direct client-server connection, which requires one side to have a reachable public IP address; relay through a TURN service; and P2P hole punching for client-server communication, meaning NAT traversal.
After ICE selects and builds a network path according to priority, it keeps running Connectivity Checks, so it can detect problems when migration-like scenarios appear. ICE Connectivity Checks also play a role similar to QUIC path validation: they verify that the new path is real and belongs to the peer, and they prevent forgery or hijacking. Personally, I think Connectivity Checks may react a little slowly. Judging migration directly from four-tuple changes can be faster. Of course, ICE itself does not forbid that, and I believe normal WebRTC implementations combine four-tuple changes for faster decisions.
When a network switch is detected, what should ICE do? It is simple in principle: switch to another previously negotiated Candidate Pair. But the previous candidate pair may now be unavailable. For example, a TURN-service candidate pair has a validity period. If none of them are usable, ICE Restart is needed to renegotiate a new Candidate Pair.
I do not think this proves QUIC is stronger than ICE. They are not at the same layer. QUIC does not consider as many complex network scenarios as ICE. QUIC only supports the first type of ICE Candidate Pair mentioned above: one side must provide service on a public IP address. If QUIC wants P2P hole punching, the developer must implement all NAT traversal work independently. ICE has already done that work quietly.
Several years ago, I worked on a wild implementation of WebRTC Mobility. The client only needed to send packets to an SFU (Selective Forwarding Unit) cluster we maintained. The initial ICE negotiation was almost ceremonial, because the Candidate Pair would inevitably use the public service address of the SFU cluster. If the client's network path changed, whether due to NAT rebinding or switching between Wi-Fi and 5G, the client did not need extra awareness. It just kept sending RTC traffic to the SFU cluster.
If, because of the network-address change, the RTC traffic was forwarded to a new machine in the cluster, the new machine returned a special signal. The client then replied through the private protocol we designed. After both sides confirmed the new path and obtained the real address of the original cluster machine, the new machine forwarded RTC traffic back to the original machine, keeping the video service running.
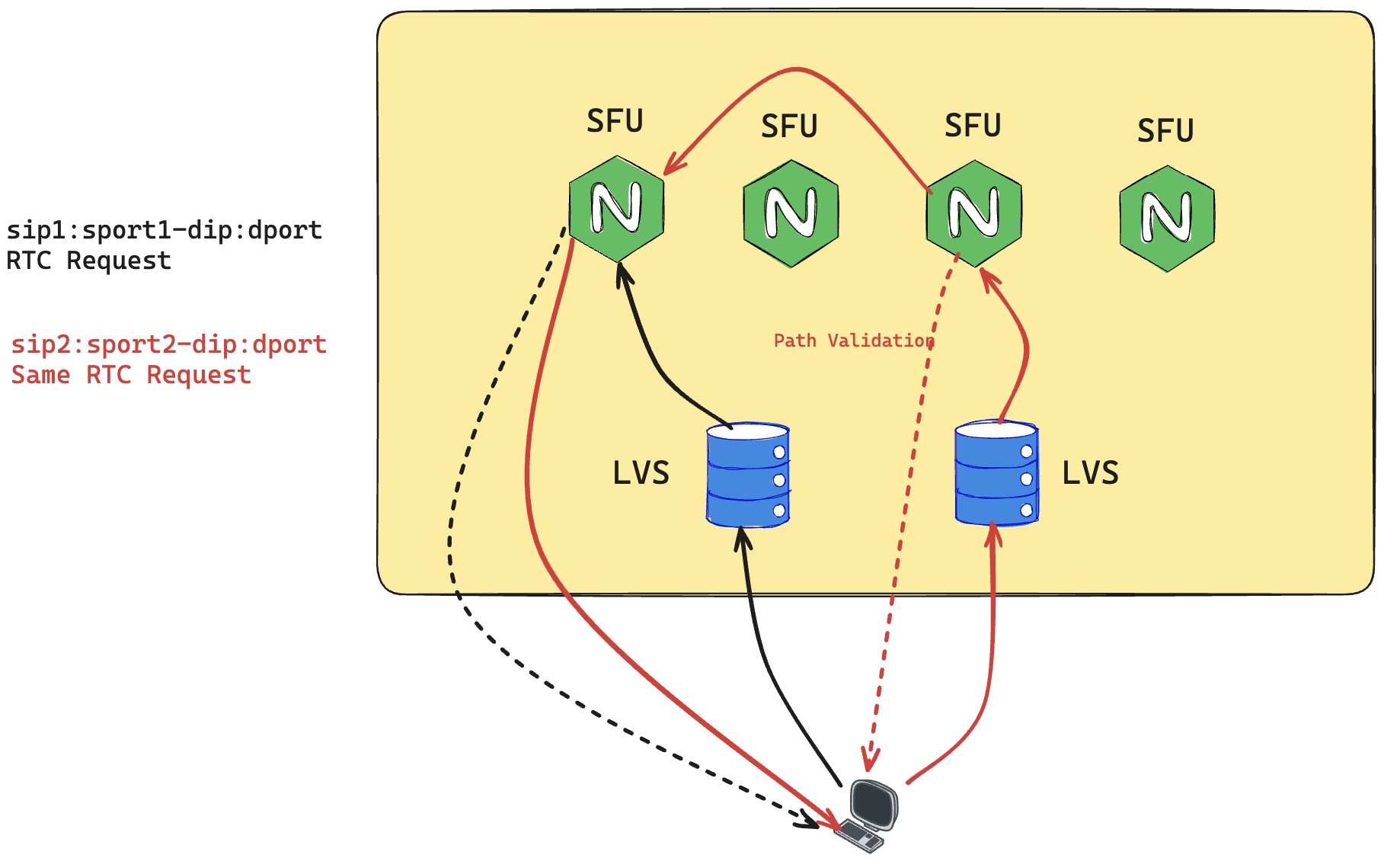
This wild design mixed in a lot of private business logic, so it is hard to explain quickly, but it was an interesting feature to design and implement. It was especially interesting because the LVS load balancer we used was configured in classic DR mode, so downstream traffic could be sent directly to the client from any machine. The efficiency was better than expected.
Another detail: if the carrier changes, for example Wi-Fi uses China Telecom while the phone's 5G uses China Unicom, but the SFU cluster is not multi-carrier and only runs in a China Telecom data center, connection migration cannot do much. The server state exists only on machines in one carrier's data center and cannot be moved to a new data center. Do not tell me to migrate server state too. That is an epic engineering pit, and the risk-reward ratio is not good. In this case, the client can only resolve DNS again, get a new SFU cluster address, and start a new RTC request.
Why TCP Connection Migration Is Hard
As mentioned above, TCP's connection-oriented behavior depends on the TCP four-tuple. Four-tuple uniqueness basically means a TCP connection is tied to the underlying network path. NAT rebinding rarely happens to TCP connections only because NAT devices support TCP better and TCP connection lifetime is easier to understand. TCP cannot implement perfect connection migration, meaning switching the underlying network path without affecting the TCP connection, unless someone heavily modifies the TCP stack. But then it probably would not be TCP anymore.
So people usually add a wrapper above TCP. When migration happens, the wrapper creates a new TCP connection while keeping the application-layer protocol unaware. Someone may ask: why bother with a wrapper? Why not directly create a new TCP connection and let the application keep using it? Because that does not work. The key point is if connection migration is not handled in the layer responsible for reliability, the upper layer has to design a small reliability mechanism again.
For example, calling send on a TCP socket and writing some application data does not mean the data reached the peer. It only means the data entered TCP's send queue. The sender can only know whether data was received by observing peer ACKs. If connection migration happens at that moment and the application switches to a new TCP socket, where should it continue sending? The sender's application layer cannot simply assume previous data was received. So an extra layer between TCP and the application must track how much data was acknowledged and maintain an unacknowledged queue. When the network switches, the new TCP connection must renegotiate what the peer has received and retransmit unacknowledged data.
After writing all that, I suddenly feel this acknowledgment problem is manageable only because the scenario is simple: two endpoints confirming state with each other. If the scenario becomes more complex, and multiple candidates need to reach consistent state, isn't that the classic distributed consensus problem? I should learn algorithms like Raft someday. The CDN systems I worked on were more like distributed clusters using partitioned, stateless load balancing. Scheduling, configuration, and other weakly consistent product state mostly depended on a centralized control plane. They were unlike database services, which have stricter requirements for node-to-node consistency.
Finally, a brief mention of MPTCP, or Multipath TCP. Strictly speaking, it goes further than connection migration. It uses multiple TCP connections to support the same application-layer session and improve quality. To some extent, it also helps decouple TCP connections from network paths. In essence, it is the approach described above: wrap a layer above TCP and maintain byte-stream reliability again. I will compare it in more detail when I implement the QUIC multipath draft, though that may be very far away.
Coding Practice Details
Connection Migration Scenarios
Server Preferred_address
The first scenario is that the server actively publishes the Preferred_address transport parameter and tells the client it can migrate. Many details need consideration when implementing this. For example: when should the client start migrating to the Preferred_address? Should the client perform path validation? When the client actively validates the path, should existing transport data be paused or continue sending on the handshake path?
Some questions have clear answers. Migration to a new address definitely requires path validation. Other questions have no clear RFC answer. For example, when the client should migrate to Preferred_address depends on user needs. My implementation starts migration immediately after the QUIC handshake succeeds. For transmission quality, data that needs to be sent is not paused before the new path is validated. It continues on the old path.
In feather-quic integration tests, I use quinn to implement the QUIC server. I ran into problems when trying to implement server-side Preferred_address with quinn. At first, I thought quinn supported multiple endpoints, each binding one socket, with all endpoints sharing the same quinn stack context. Following that idea, I created two endpoints, one bound to the original listen address and one to the Preferred_address. But packets migrated to the new path were all dropped because the Connection ID was invalid. Also, each endpoint uses accept to receive new connections. That told me each quinn endpoint must own an independent QUIC stack context, so my original idea was wrong.
I could not find an API for associating multiple sockets with one endpoint. Some people may mention rebind, but I immediately excluded it at first because I needed to add a UDP socket, not replace the existing one. Otherwise, how would the QUIC handshake complete before migration?
Sadly, I searched the quinn docs for a long time and did not find what I needed: an endpoint associated with multiple UDP sockets. Then I read quinn examples and tests, especially the PR that added Preferred_address, but still found nothing. I even searched GitHub globally for code using the quinn Preferred_address API (preferred_address_v4), and still found no examples. With no choice left, I read the quinn code. This is not the first time. Many Rust third-party libraries have complete functionality but lack docs and examples. I suddenly realized feather-quic is the same. But since it is a learning project and still early, documentation may not be too important. I will improve it later if fate allows.
After reading the code, I found that the rebind PR had enhanced the interface. Calling rebind does not immediately replace the old UDP socket. It waits until traffic arrives on the new UDP socket before really switching. That solved the problem.
Client-Initiated Migration Based on Its Own Needs
The second common scenario is that the client actively starts connection migration based on its own needs. feather-quic should give users this freedom and let them decide whether migration is needed.
The key implementation point is that feather-quic needs a new API allowing users to switch the UDP socket target address and migrate. After feather-quic completes Path Validation for the new address, all traffic is switched to the new path. Since feather-quic still uses an ugly asynchronous callback development model, I can only add a migrate_to_address API to QuicConnection, letting users call it inside their registered async callback and actively select a prepared address for migration.
Network Environment Changes
Network environment changes are usually NAT rebinding or client mobility, such as switching from wired network to Wi-Fi. But clients often cannot detect these well. In the NAT rebinding case, the client is hidden behind complex network topology. If the NAT device in front of the client rebinds, the client knows nothing.
In the second case, the feather-quic runtime can hardly discover the problem through UDP socket errors. UDP sends may encounter errors such as host unreachable, network unreachable, or connection refused. But if we are only switching networks rather than losing network access, and our UDP socket is no longer bound to a fixed four-tuple, and the local bind address is 0.0.0.0, Linux often will not deliver many abnormal ICMP messages to the application layer on the UDP socket. Users can only rely on other system mechanisms to monitor these events. On Linux, for example, they could use netlink sockets to detect network events and then call the active migration API provided by feather-quic, but that is too much trouble.
QUIC connection migration handles these complex situations well on the server side. The server implementation detects network-path changes through changes in the peer IP address and port. If the client address changes, the server actively starts connection migration so the QUIC connection is not disturbed. Since feather-quic currently only supports client capabilities, and as mentioned above, detecting peer-address changes on the client is not very meaningful. Once the server's traffic address changes, it usually cannot send to a client behind NAT unless the network environment is very clean. So the burden in this scenario is entirely on the server.
Current Problems in feather-quic
The first painful part of implementing connection migration is that feather-quic is neither a pure protocol stack without runtime, like ngtcp2, nor a modern async/await based stack, like quinn. This makes it hard to provide a non-tricky connection migration interface. I eventually compromised by exposing a specific API inside callbacks, but I also had to add an extra migration_switch_result callback to notify users of the final migration result.
I hope feather-quic can be connected to a modern async/await programming model soon. Right now it does not even provide timers to users, which is painful. Writing test cases is not easy either.
feather-quic still has many incomplete details. Every large feature PR has to fill holes left by earlier work. This time, I had to modify Connection ID related code again and reorganize error handling in the stack. Some data structures and framework flows are also poorly designed, which I think is quite serious. I only have fragmented time for the project, so I can only keep polishing it through later iterations. While coding, I always feel a mild conflict: there are too many details to handle, and I keep wondering whether I should cover them all. A good level of completeness takes a lot of energy, but my expectation for this project is mostly self-entertainment. It is painful, so I comfort myself by writing TODOs.
Epilogue
This time I changed my development mode. In the past, I wrote code first and then wrote the related blog post. As a result, after writing the blog, I often adjusted the code a lot because the writing process gave me new understanding of many design details. This time, I first completed the main body of the blog, then started coding. I split the feature points into small enough tasks and handed them to Cursor.
So most of the code this time was generated by Cursor, and it directly used up my Cursor Pro quota for the month. Here is the PR. I have to say that LLM-generated code is becoming more and more impressive. Although it may generate problems, whenever I gave modification suggestions, the model usually responded correctly.
This changed my view of LLM-generated code a bit. I have not studied large models deeply, but from what I have heard and from my own use, current code generation still has two problems. First, LLMs are great when the task is clear and there are good examples. They struggle when the library is new, the design is unclear, or the context is missing. Second, LLMs have context limits. When using them, we need to reduce their context burden. This still matches my previous view: let AI handle clear tasks, while we decompose the work and make the requirements explicit.
I recently saw an interesting V2EX thread. I strongly agree with the first point: AI puts a huge amount of information right in front of you, but what you lose is control over details. Often, learning is a slow and painful process, at least for me. But slow is fast. Knowledge gained through repeated thinking is remembered more deeply and understood better. So when I use AI to learn a new field, I need to keep reflecting on this and avoid trading real understanding for speed.
I also read a thoughtful blog post. Its point makes sense: the valuable thing is never the code itself, but the people who can maintain it. Fast code generation by LLMs only shifts the cost. Code review, testing, maintenance, and related work remain critical. We still need to stay cautious with LLM-generated code and review it carefully, especially for production code. Otherwise, as the blog says, subtle mistakes introduced by LLMs may suddenly explode one day and cost far more than writing the code ourselves. That said, LLM-generated code has made my development experience much better. Using AI to handle boring, tiring work greatly increases the joy of writing code.