我的第一个 Linux 内核补丁:从一个 TCP Listener 的 Bug 说起
TL;DR: 这篇博客记录了我第一次给 Linux 内核贡献 Bugfix 补丁的全过程,全文可以划分成三个部分:第一部分记录我是怎么发现这个 TCP Listener 的 Bug,第二部分详细记录了我给内核提交的补丁的完整过程和心得总结,第三部分分享了我对开源社区运作新的理解,包括和商业化组织里面工作的不同,以及如何更好的参与开源社区,如何利用开源社区让个人得到成长。
前言
首先声明,本篇博客全部由本人手敲,没有任何 LLM 参与,这倒不是我反感 LLM 生成的文章(毕竟 LLM 只是工具,作者才是赋予文章灵魂的人)。而是我觉得写这篇博客会为我带来极大的乐趣,我只是不想让 LLM 抢走我的快乐。
一般来说, 在 Linux 应用层做开发的,或多或少,都看过一些 Linux 内核实现细节的资料。这里,一直存在一个说法,就是说对于研究 Linux 内核的人,有读者和写者的两种角色定位,所谓读者,是在阅读内核源码的时候,注意力更多的是集中在用户态可能遇到的系统问题上,即怎么让用户态的系统编程实现的更合理高效。换而言之,读者了解 Linux 内核,不是为了掌握每个实现细节去做内核态开发,而是为了提升自己解决系统级别问题的能力。
而我虽然一直在 Linux 环境下相关的系统编程开发工作,但一直更多的只是半个阅读者。比如我在好多年前参加校招的时候,就一直在玩一个假装我和 Linux Epoll 源码实现细节很熟的游戏😂,由于玩的比较成功,当时百发百中,一个月不到就结束了校招。当然,也可能那时候还是程序员的黄金时代吧,毕竟现在听说最近几年校招真的是卷的飞起。
话扯远了,再简单回顾一下整个过程,大概历时一周时间,从 Bug 发现、修复、发出补丁、来回三轮邮件 review 讨论,终于我的第一个 Linux 内核 Bugfix 补丁被成功合并到 Linux-7.1-rc1。当我看到邮件,说代码会被合入主线的时候,整个人内心都是非常喜悦的,大概就像是打守望先锋,枪枪爆头,拿下五杀,还没有被奇怪的队友抢走全场最佳。这期间,哪怕切尔西联赛五连败,告别下赛季欧冠资格,也没有冲走我的喜悦(不过我这段时间会尽量不接触足球,避免受伤)。
我当然知道,给 Linux 内核贡献代码并不是一件特别稀罕的事情,更别说只是一个小小的 Bugfix。甚至有的大佬读书的时候,可能就已经是核心贡献者了。但是这件事情对于我来说,依然有着特殊的意义,毕竟我只是内核的业余读者,一直都在应用层讨饭吃。这次可以给 TCP Listener 贡献 bugfix,至少代表着以前 TCP 源码走马观花式的阅读并没有浪费,也算是有所斩获😉。
回到正题,我接下来想聊一聊,在整个过程中,我是如何发现这个尘封了五年的 Bug,以及第一次在内核纯邮件开源协作过程中的一些手忙脚乱的经历,特别是最近在参与开源社区的时候,感受到了和在商业化公司里面写代码的区别。并且得感谢好几位大佬,在整个过程中对我的帮助,让我感觉到了真正的开源精神,希望自己后面也能把这样的精神传递下去,这也是我写这篇博客的源动力。
Bug 是怎么发现的
TCP Listener 断流问题
现在,我开始正式回顾这个 bug 到底是怎么被我发现的。如果从头说起,这得回顾到好多年前的时候,我和组里大哥在出差(一次大故障之后的封闭开发)。在住的酒店到园区的上班路上,大哥突然跟我说了一句:你知道 TCP Listener 实现有一个 Bug 吗。我当时一脸黑人问号,线上稳定性问题都解决了吗,用户那边线上质量 PK 我们排名第一了吗,公司活了 102 年吗,为什么突然跟我聊这个。但我没忍住好奇心,还是开口询问,到底是啥问题。毕竟,我怎么感觉每次功能出 bug 都是我的问题,内核从来都是无懈可击。
大哥微微一笑,跟我说:TCP Listener 如果被关闭后又重新打开, 在大流量场景下,极小部分新请求会挂掉。说的更具体点,这些小部分请求就是没完成三次握手的半连接请求,以及挂在 accept queue 里面没有被应用层 accept 走的全连接请求。这些请求都会随着被关闭的 TCP Listener 销毁流程一起被干掉。
我瞬间领悟,整半天,还是我们线上业务问题。正经人家,谁会在服务过程中,把线上的 TCP Listener 关闭又打开,这不是标准的 nginx 无损热更新流程嘛。而且 nginx 都是尽量确保老进程的 Listener fd 被继承到新进程,只有我们当时自己实现的 Tengine Reuseport 功能才会干这个事情。
于是,我立刻说,这不是使用方式不对吗,而且 Tengine Reuseport 已经修复了这个问题,现在都是通过 fd 继承的方式,来确保底层的 TCP Listener 不被销毁。大哥反驳我说,问题还是存在的,市面上有很多服务端都是用 systemd 管理的,nginx 这种 fork 继承的解决方案很难直接套用的。换句话说,这种问题,就不应该让应用层来处理。
聊完这个话题,我坐到工位上,顺手翻了一翻内核 TCP Listener 销毁的源代码,满足下好奇心。这其实已经是我对技术追求的极限了😈,再摸鱼就要背绩效指标了。我当时也没想过有其他人关注这个问题吗,内核社区那边有人知道吗,我更没有闲情逸致去问大哥,为什么不去开源社区把这个 bug 给修掉。我都能预判到大哥肯定会一脸嫌弃的说:开源社区给我发钱吗,我帮他修,我还想搞钱换套大房子。
嗯,大家都在为生活拼尽全力,可以参考我的 github 主页,在我刚工作的前五年,基本上没有任何代码提交,全部时间都奉献给了我上家公司。当然,我现在 github 提交活跃,不是说我财富自由了,只是我发现没钱日子也能过,还是狗命要紧。开源写写代码,对我来说,就像是中年人的业余爱好,比如说钓鱼(没什么经济价值,全是精神满足),甚至比最近新出的红色沙漠吸引力还大一些。
内核社区的解决方案:TCP Listener Migration
直到最近,我闲来无事,正在给 aya 开源社区做 reuseport eBPF 功能支持。关于我为什么做这件事情,一方面是之前写的博客 (Learning eBPF the Hard Way: 从 nginx eBPF 的实现说起)里面提及了 sk_reuseport eBPF 实现,然后我看了 Cloudflare 开源的 udpgrm 项目,手痒想用 Rust 写一写,结果发现 aya 居然还没有支持这个功能。另外一方面,是感觉 aya 社区对代码质量要求特别高,提 PR 后会有非常严格的 review,对于提升我 Rust 和 eBPF 水平帮助很大,所以想在 aya 社区多提交些代码。
当我在做这个功能的时候,突然发现 BPF_PROG_TYPE_SK_REUSEPORT eBPF 还额外支持了 migrating_sk 能力。我当时本能的感觉,这个 eBPF 程序是不是为了解决 Listener 关闭会导致新请求断流的问题。于是翻到了对应的内核补丁以及 YouTube 方案演讲相关资料,发现果然如此。
原来内核大概在五年前已经解决了这类问题,专门针对 Reuseport Listener Group 的场景做优化。当 Group 里面的某个 TCP Listener 被关闭后,里面的半连接和没被应用层 accept 的全连接,都会转移到同一个 Reuseport Group 里面其他还活着的 Listener 上面去。另外,更方便的一点是,还和 eBPF 结合起来,允许开发者在 TCP Listener Migration 的一瞬间,编写 eBPF 程序自行选择应该发给哪个 TCP Listener。这个自主选择权,对很多业务场景都非常重要,比如说,希望让某些特定的 TCP 连接根据某些业务属性被转发到某个特定的进程上面去,变得非常轻松。
感谢一次严格的代码 review
既然这样,我就快马加鞭干完了 aya reuseport eBPF 功能开发,而且还特意为 TCP Listener Migration 专门设计了一个 e2e 测试:Listener A 和 Listener B 同时开启 Reuseport,bind 在相同的地址和端口,然后 Listener A 和 B 同时开始监听,客户端 connect 成功,eBPF Reuseport 程序强制请求命中 Listener A,但是 Listen A 没有去 accept 这个新请求,然后让 Listener A 关闭。这个时候,Listener B 可以成功 accept 到原来的 TCP 连接,同时 eBPF Migration 程序也可以成功触发。
Time ───────────────────────────────────────────────────────────────▶
Listener A SO_REUSEPORT ─ bind ─ listen ─ selected by eBPF ─ close
▲
│
Listener B SO_REUSEPORT ─ bind ─ listen ──────────────────── accept()
│ ▲
│ │
Client connect() ─ succeeds ────────-─┘
│
▼
Kernel reuseport group ─ run eBPF ─ choose A ─ A closes ─ migrate to B
一切都是那么完美,除了我在 e2e 测试里面,没有使用 Tokio,直接使用了阻塞式的 sleep(10ms) + 非阻塞 accept 轮询的方式。虽然这些代码是 LLM 写的😂,但是我也是出了大力,认真监工,反复调整了很多代码细节。唯独没反应过来阻塞式的轮询逻辑确实有点丑陋,可能我平时写 C 写多了,总是感觉测试代码用用阻塞加轮询也非可厚非,毕竟 C 里面要加这些玩意,还挺麻烦的,得网络库一通塞。忽略了 Rust 里面 Tokio 生态在写这些场景的时候,其实非常简单易用。

我代码其实已经反复打磨了很多次,但是 PR 还是得到了 29 个 comments,其中就包括上面这条,不要阻塞式的 sleep。所以,我现在还是反思自己不够 Rustacean,平时只能做开源时候搞搞 Rust,现在还都是 LLM 代劳生成代码,使用强度还是不够,得多练习多思考才行。
但当我反手切换成 Tokio 的时候,我发现测试用例执行失败了,一直 await 卡死在 Listener B accept 异步执行的过程中。这个诡异的现象引起了我的注意,我去翻了下 Tokio accept 的实现细节,发现 Tokio 是先把 Listen fd 加入事件循环中,等待可读事件触发,再去 accept(当然正经的异步非阻塞 accept 都是这么实现的)。
由于测试稳定复现失败,我就直接跑了一下 strace,就很轻松的缩小了问题排查的范围。原来是 Tokio epoll 里面 Listen B 的可读事件一直没有被触发,这个让我非常奇怪。难道是 TCP Listener Migration 的过程中,把目标 Listener 的可读事件给丢了吗。
这个时候,就只能去翻内核代码了,不过这个也比较好找,这里是半连接迁移的逻辑,考虑到半连接还没有完成三次握手,所以半连接只需要 Migration 到新的 Listener 即可,不需要考虑可读事件 notify 的问题,因为还有后续的 syn-ack 报文来触发真正的可读事件。但是在全连接迁移的逻辑里面,内核也只是 Migration 请求到给新的 Listener,没有去触发新的 Listener 可读事件。至此,已经初步判断这是内核实现 TCP Migration 的时候,遗漏了可读事件通知。
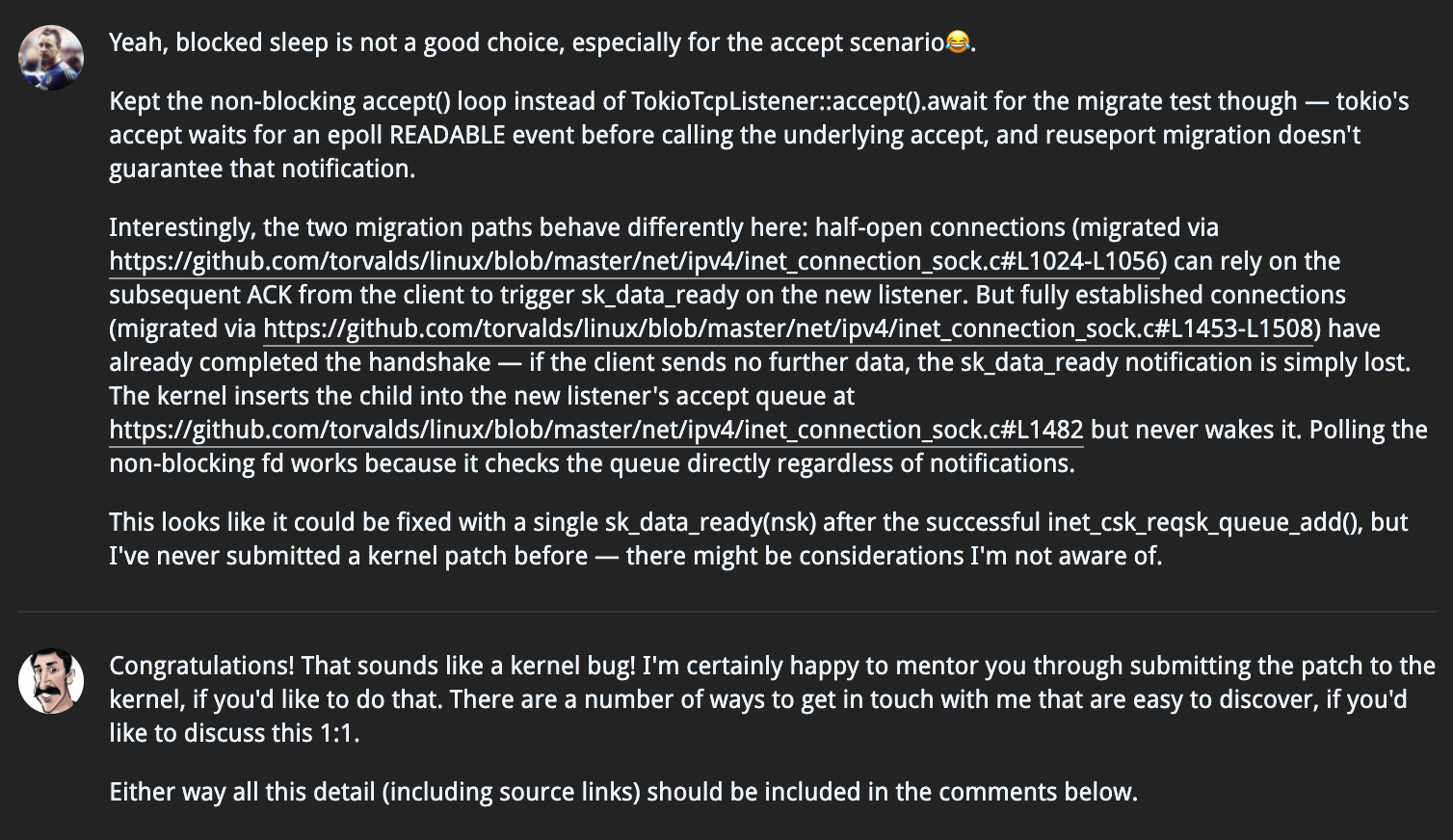
于是,在我 PR 里面写下了整个问题的来龙去脉,但是我不太确定要不要给 Linux 内核提补丁,毕竟之前没提过。这时候,aya 社区的 maintainer Tamir 回复我说,这个看起来确实是一个内核 Bug,他可以来指导我怎么给内核提补丁。我当时看到回复就很兴奋,感觉被鼓舞到了,于是就赶忙开始准备要提交给 Linux 内核的补丁。
给 Linux 提补丁的全过程
Cover Letter
首先,我得准备我人生第一个 Linux 内核补丁,先发给 Tamir,让大佬帮我先掌掌眼。但是在这之前,我还是得仔细阅读一下 Linux 贡献者指南。虽然 LLM 可以帮我代劳很多事情,但是我还是不太放心 LLM,担心被它把事情搞砸。有些事情,我睁一只眼闭一只眼让 LLM 瞎搞就算了,但是,我毕竟知道 Linux 内核是一个非常严肃的开源社区,我可不想冒着被 LLM 把事情搞砸的风险。这就像是去别人家做客一样,要先熟悉对方的规矩。
所幸,Linux 贡献者指南写的非常友好,首先我能看到的是在正式编写 Bugfix patch 之前,我们需要完成 Cover Letter 编写。所谓 Cover Letter,其实就是描述你的动机,你为什么要提交这些代码改动,场景是什么样的。这些,其实对于工作过一段时间的人,都是轻车熟路。而且内核社区还给了很友好的文档指导,我觉得 Cover Letter 是补丁系列的灵魂,如果 Cover Letter 写的有问题,比如说问题场景根本站不住脚,那后面的代码改动更是毫无价值。
有了这些帮助,我很快写好了我的 Cover Letter,当然我也从现有的 Cover Letter 里面快速学习了社区里面都是怎么写的。虽然,TCP Listener fd 可以很容易被后进来的请求给唤醒,从而拿到可读事件,这也是这么多年没有发现的原因。但这依然是一个问题,所以我们肯定是需要 fix 掉的。
然后我把 Cover Letter 发给 Tamir,大佬很快回复了我,给了我两条建议。第一条是,在 Cover Letter 里面,不要涉及 Rust 的概念,以内核社区 C 语义来描述问题里面的技术细节,另外也不要在背景里面提及外界的项目,只专注于问题本身。
我觉得这个提醒非常关键,因为我平时写 PR 内容时候,就跟写博客一样,喜欢多扯两句,特别是加点问题的背景,讲一讲我是在用什么的场景下遇到的(因为我可能觉得作者也喜欢了解一下自己的作品在什么情况下被使用的)。在平时的开源项目之类可能还行,但是在 Linux 内核这么严肃的开源社区,就不合适了,毕竟全世界都在用 Linux 内核。所以尽量只描述问题和场景,而不是讲述故事背景,不然会有一种让人觉得你在打广告的感觉。
另外一个则是大佬提醒我,从原理上看,不仅仅在非阻塞的场景下,Listener B 会丢失读事件。如果是阻塞使用 accept 的情况下,即 Listener B 一开始进行阻塞式 accept,哪怕 Migration 给 Listener B 转移了新的请求,但是 Listener B 依然会阻塞等待 accept,而不是被唤醒拿到结果,毕竟 notify ready 事件丢失了。我一经提醒,发现这个讲的非常有道理,原来我太激动还漏掉了一个场景,我快速的写代码测试了一下,果然如此。于是连忙把 Cover Letter 里面的场景描述给丰富了一下。
经过大佬的帮助,我的第一版 Cover Letter 顺利出炉,地址在这里。
正式开始编写补丁
其实我这个补丁就是经典的 One-Line Fix,所以我本来以为这里工作量会比较小。唯一让我有点担忧是,Linux 内核的开发会不会很繁琐。但让我比较惊奇的一点是 Linux 项目开发体验很好,使用 Codex 可以很丝滑的把 QEMU 环境搭建好。比我现在公司里面项目丝滑多了,毕竟是全世界都在参与的开源项目,各种流程细节都打磨的很完善。
接下来就是测试了,给开源项目提 bugfix 不加测试,就像是第一次去老丈人家里,你手里只提了雪碧和可乐,虽然可能不会被吊,但是印象分肯定下去了。这种错误,我肯定不能犯,正常来说,这种 Bugfix 的测试,应该加在老功能的测试里面。但是我翻了翻,发现 TCP Listener Migration 测试放在了 bpf 的目录下面,这让我心里有点犯嘀咕。于是干脆另起炉灶,自己在 net 的 selftest 目录下面哼次哼次搞了半天,整了两个独立的测试,分别覆盖了上文中的两个场景。
话说回来,既然不只是 One-Line Fix,毕竟写了那么多测试代码,那就得仔细研究 Linux 的代码风格要求了。以前没有 AI,我刚毕业时候研究 nginx 代码风格,一方面有文档总结,另外一方面拿不准就去翻老代码去研究类似的情况应该怎么写。现在有了 AI,但是我还是不敢全信 AI,所以还是得一点一点按老方法去扣细节,防止有漏网之鱼。
说实话,用 C 代码写这些测试覆盖,真的很容易写的又臭又长。这是我第一次完成的测试补丁,极度冗长。特别是 accept 阻塞式的场景的测试用例,写起来是真的麻烦,哪怕有 AI 也得反复推敲细节。
发出补丁前的检查事项
接下来就是发出补丁了,在发出补丁之前,Linux 内核还贴心的准备好了检查事项文档。果然,代码风格和补丁格式的要求全部都工具化了,这个我倒是一点也不意外,每个成熟的社区都会有这些。
因为这是发送给网络子系统的补丁系列,还需要参考网络子系统的额外要求文档,我觉得这个也非常重要。除了 Linux 内核社区的要求之外,每个子系统都有各自积累下来独有的要求。就比如说,网络子系统代码风格对变量的声明有着额外的要求,名字还挺有意思的:反向圣诞树。
最后就是按照内核文档的提示,使用脚本把需要发送邮件的大佬们都扫出来,然后用命令行 git send-email 来发送邮件了。说实话,我第一次发送邮件,大概磨了有半个小时,反复检测补丁内容。另外一方面,发送邮件的工具也有点不太适应,虽然我很喜欢命令行的工作流,但是 git send-email 还是过于 old-school,我还是蛮担心出问题的。我反复 dry-run 了好多次,最后才下定决心,把邮件给发出去。
老派的纯邮件代码 review
review 过程回顾
邮件发完,就等大佬们的回复就好了。我这个邮件由于是修复的 TCP Listener Migration 的一个小问题,所以邮件当天就得到了该功能作者 Kuniyuki Iwashima 本人的回复。大佬对问题本身没有提出什么意见,只是让我把测试调整一下,去复用 TCP Listener Migration 现有的测试。
果然,我当时的预感是对的,我乌七八糟写了那么多测试代码,只为了覆盖这两个边缘场景,肯定是有问题的,性价比太低了。还是得在已有的测试里面去做改动才合适。嗯,我当时也算是偷懒了,没有去仔细阅读原来测试用例细节是怎么写的。只是看到在 bpf 目录下面,就武断以为是用不上的,得自己从头写测试。
另外,关于测试的代码,Tamir 还给了我一条 Review 建议。大概是 GCC 编译器的黑魔法,可以实现 C 自定义类型的析构函数。不过,Kuniyuki Iwashima 说为了保证测试代码的一致性,不建议这次引入这个特性。我事后研究了下,发现这套黑魔法,大概是最近几年才在内核被使用的,所以 TCP Listener Migration 的测试里面没有使用,算是一个有趣的小插曲。
Use After Free
不过,话说回来,虽然这个问题其实影响面很小,毕竟新流量可以取代可读事件,让应用层服务可以正常运行下去。不过随着 Eric 的一封 Review 邮件到来,事情发生了新的变化。大佬直接指出,这段逻辑之前就存在 Use After free 的 Bug,但并不是我的新增代码逻辑改动引入的。
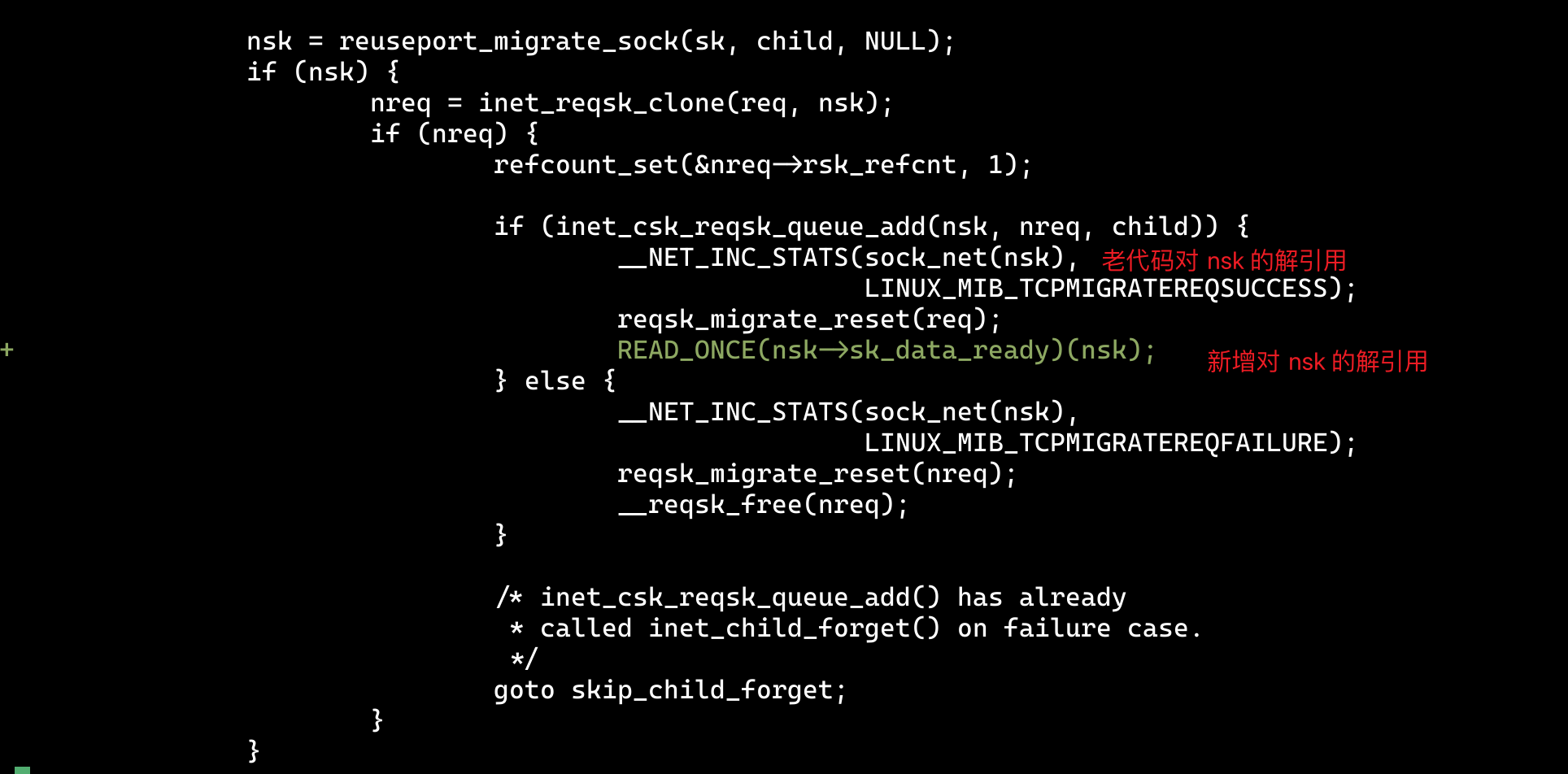
我当时就有点懵逼,我只是访问了代码里面本来就存在并且也被会访问的 nsk 变量。我本来以为代码只是漏调用了 sk_data_ready,万万没想到,对 nsk 变量的访问,居然还存在 UAF 的风险。自我反省一下,我还是把这次 Bugfix 当做一个顺手而为之的事情,并没有切换角色,去真正审视相关代码的实现细节。换句话说,我还是把自己当做是读者,没有去真正理解全盘逻辑(其实好像我也没有必要反思,我本来就不是内核开发者😂)。
sk 的生命周期和 RCU Lock
还好 Eric 非常 nice 的把他的修复代码补丁也附在了邮件里面,这样我至少不会两眼一抹黑,可以去根据修复来反推,到底哪里引入了 UAF 的风险。说实在话,这是我要从内核读者的身份,开始尝试转变偏向写者的身份了。因为从修复上来看,很明显我需要去理解 sk 的生命周期,以及内核 RCU Lock 的机制,才能把问题搞明白。在以前,我阅读内核代码的时候,对于纯粹的读者来说,这些都是对于用户态来说不重要的实现细节,我每次都是直接跳过去了。
其实我对 sk 生命周期的理解非常粗浅:大概就是内核的 sk 的生命周期是通过引用计数来管理的,比如说每个应用层的 fd 都可以代表一次引用计数加一,当应用层 fd 都被 close 完,那底层的 sk 引用计数归零,那么就要走销毁流程。至于多进程的竞态条件啊什么的,我完全没有去考虑过这些细节。
所以,我一开始看代码就认为,这个 reuseport_migrate_sock 其实是保证了 nsk 的引用计数大于 1 的,毕竟里面主动去给 nsk 引用计数加一,而没有减一的操作。讲道理,nsk 指向的内存应该是有保障的才对。但是我看到大佬给的补丁里面,在 inet_csk_reqsk_queue_add 访问 nsk 之前就加上了 RCU Lock 保护。那我理解,应该是 inet_reqsk_clone 这个调用破坏了 nsk 的生命周期保证。我仔细研究了一下 inet_reqsk_clone 的使用,这里面没有对 nsk 引用计数的任何改动,只是把 nsk 拷贝给了 nreq->rsk_listener。这有点像是 Rust 里面的 move 语义,即 nsk 这个栈变量自己不再负责维护引用计数,也就是不再对该内存负责,虽然之前是 nsk 亲手做的加一。而 nreq->rsk_listener 承接了这块 sk 内存的责任,负责对这个 sk 后续进行引用计数减一的职责。但是 C 语言还能访问 nsk 这件事情,就体现了 Rust 酷炫的地方。
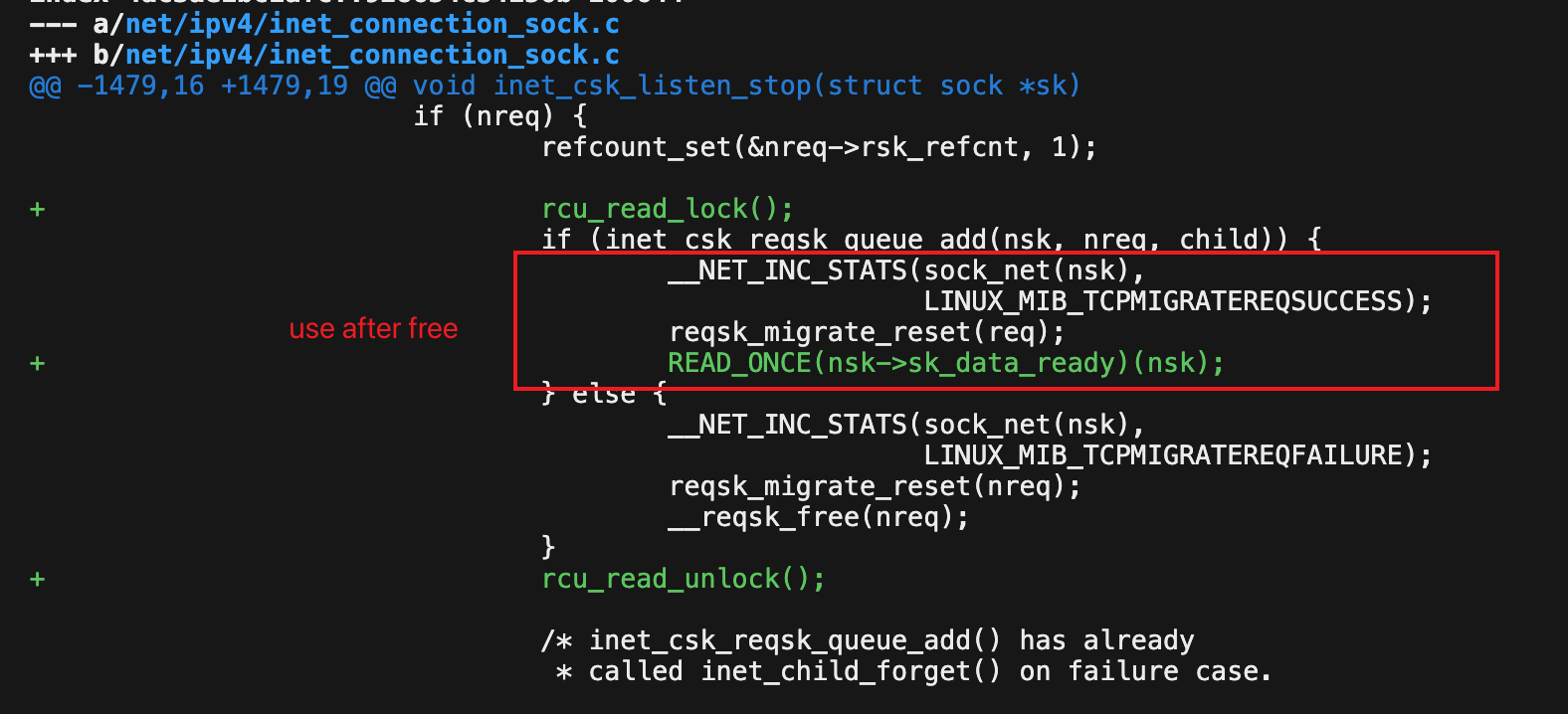
而 inet_csk_reqsk_queue_add 又亲手把 nreq 给 publish 出去,这意味着其他 CPU 有机会来消费这个已经完成三次握手的 nreq,并且可以顺手关闭对应的 Listen,让 nsk 指向被释放的内存。所以,Use After Free 的问题区间就出现了,即在上图中已经真正修复代码的红框部分。为了方便理解,我让 LLM 画了下面的流程图,这样可以看得更清晰。
Time Code path sk_refcnt nsk owner
──────────────────────────────────────────────────────────────────────────────────
T0 循环开始 N -
nsk 还没有被当前上下文持有
┌──────────────────────────────────────────────────────────────┐
│ 唯一一次对 nsk->sk_refcnt 的 inc 发生在 reuseport 选择路径里 │
└──────────────────────────────────────────────────────────────┘
T1 nsk = reuseport_migrate_sock(sk, child, NULL) N+1 local nsk
reuseport_migrate_sock()
├─ rcu_read_lock()
├─ refcount_inc_not_zero(&nsk->sk_refcnt)
├─ rcu_read_unlock()
└─ return nsk
T2 nreq = inet_reqsk_clone(req, nsk) N+1 local nsk
inet_reqsk_clone()
├─ alloc nreq
├─ memcpy(sock_common header)
├─ nreq->rsk_listener = nsk
│ 这里只是普通指针赋值,不会 inc nsk->sk_refcnt
└─ return nreq
T3 refcount_set(&nreq->rsk_refcnt, 1) N+1 rsk_listener
操作的是 nreq 自己的 rsk_refcnt,
和 nsk->sk_refcnt 没有直接关系。
T4 inet_csk_reqsk_queue_add(nsk, nreq, child) N+1 rsk_listener
inet_csk_reqsk_queue_add()
├─ spin_lock(rskq_lock)
├─ if (nsk->sk_state != TCP_LISTEN)
│ └─ forget path
├─ else
│ ├─ 链入 nsk->icsk_accept_queue
│ └─ sk_acceptq_added(nsk)
├─ spin_unlock(rskq_lock)
└─ return child
到这里,当前上下文不再额外持有 nsk;
nsk 的那次 refcount_inc_not_zero() 现在只由 nreq->rsk_listener 承担。
─────────────────────────────── UAF window ───────────────────────────────
T5 __NET_INC_STATS(sock_net(nsk), ...)
READ_ONCE(nsk->sk_data_ready)(nsk)
这两处都会裸访问 nsk。
但此时栈上的 nsk 已经没有独立引用。
如果另一颗 CPU 先走到 T6/T7,把 nreq 释放并最终 sock_put(nsk),
那么这里继续解引用 nsk 就可能踩到 UAF。
──────────────────────────── async release path ───────────────────────────
T6 另一颗 CPU 触发释放路径
Path A: 用户态 accept(nsk_fd)
├─ reqsk_queue_remove(queue)
├─ 拿到 nreq
└─ reqsk_put(nreq)
├─ refcount_dec_and_test(&nreq->rsk_refcnt): 1 -> 0
└─ __reqsk_free(nreq)
├─ sock_put(nreq->rsk_listener)
│ 这是对应 T1 的 dec
└─ kmem_cache_free(nreq)
Path B: 同一个 reuseport group 中,nsk 自己也在 listen_stop
├─ 遍历自己的 accept queue
├─ inet_child_forget()
└─ reqsk_put(nreq)
└─ 最终同样走到 sock_put(nreq->rsk_listener)
T7 如果 T6 的 sock_put() 让 nsk->sk_refcnt 归零:
__sk_free(nsk)
现在还有一个问题,就是 UAF 临界区明明在 If 判断的里面,为什么 RCU Lock 为什么放在外边,这不是错误的扩大了锁的区域吗。想要理解这个修复方案,还需要理解 RCU 的核心实现机制。RCU 本质上不是锁,而是一种延迟释放的生命周期保证,确保访问对象的内存哪怕是引用计数清零了,也可以被安全访问,当然如果有写操作,还是得自己去加锁保护之类的。
早期的实现是,当前 CPU 执行到 RCU Lock 的逻辑时,则不会主动放弃当前逻辑流的执行(比如说一次调度引发的上下文中断)。也就是 RCU Lock 到 Unlock 的区间内,CPU 会持续一直执行完毕,才会有机会被重新调度。另外一方如果是要做 RCU Free 的代码逻辑,会异步等待执行 Free 逻辑,异步等待的标准是当前所有 CPU 都完成了一次调度,再进行内存 Free。这个设计的好处是,RCU 读方和释放方,都不需要知道各自访问的内存是什么,只引入一点延迟释放的时间开销,就可以确保读方不需要引入真正的锁,就达到访问内存安全的目的。这个设计,让我有点惊为天人,感觉真的有东西。而且这套机制其实应用层也能用上,希望哪天能遇到个类似的场景,来感受下。(注:上面说的是非可被抢占式 RCU 的原理,至于现在内核应该是使用可被抢占式的 RCU 实现,考虑到我不是内核开发者,我就不继续研究了,真的学不过来了)。
紧接着,既然 RCU Lock 不是真正意义上的锁,那么它的临界区就不能像锁那么小。而是需要在被保护对象存在被释放风险之前,就得加 RCU Lock 来保护。在我们这个场景里面,就是在 inet_csk_reqsk_queue_add 把 nreq publish 之前,就得 Lock 保护起来。不然一旦 nreq 暴露给其他 CPU,那么就存在被释放的风险,在那个时候再去用 RCU 保护,就为时已晚。
这里面还存在一个小细节,就是 TCP Listener 的内存得是通过 RCU 释放的,这套保护机制才能生效,不然也是白给。而我查了下,看起来 TCP 协议栈里面为了提升性能,很早就引入了相关改动,让 TCP Listener 和 UDP socket 的 lookup 路径可以不使用 socket_hold 这种引用计数来保证访问内存安全,而是通过 RCU Lock 无锁保护来提升性能。
当我把这些整明白,已经好几个小时过去了 = =||,当然这些时间的付出,完全是值得的,虽然有些细节会忘,但是我觉得 RCU 的原理机制我一时半会是忘不掉了,这个设计真的好巧妙。于是,我赶快回复邮件,把我的理解,在邮件里面言简意赅的回复了一遍,然后大佬们都没有回复。本来按照我的理解,没有回复,就代表我理解对了😉。但是我在写博客的过程中,经过上面的仔细梳理,发现我的邮件回复里面,存在着一个表达不够清晰的地方,即没有写明白,是 inet_reqsk_clone 把 nsk 的所有权转移给了 rsk_listener,而 inet_csk_reqsk_queue_add 只是负责把 rsk_listener 暴露出去。
流程结束后的总结
说实话,这是我第一次参与全邮件代码提交的工作流,以前发邮件基本都是技术讨论,很少直接在邮件里面进行代码 Review 的。这里,我实际体验下来,感觉还挺难把握 Review 的节奏的,打个比方,Reviewer 评论了,你回复了。你是立刻提交新补丁,还是说要等一等其他 Reviewer 的建议。
这里,我把我研读内核贡献者文档的心得体会再写一下,当然不保证都对,尽量都给出处:
这里面,我觉得还有一个比较重要的事情,Review 的关键节点是什么。比如说,在 github PR 里面,有 need work 或者 approved 这样的状态,一目了然。那内核邮件 review 工作流里,有什么标志性的事件能判断 review 进展的。其实内核文档里面已经说的很清晰了,有几个标识,Reviewed-by 代表 approve 的意思,如果 maintainer 邮件回复这个,就说明已经通过了。另外还有一个特别需要注意的问题,文档也明确说了,只有 Reported-by 和 Suggested-by 才不需要对方许可,其他标记必须由对方本人邮件确认,才能添加。比如说,Eric 和 Kuniyuki 都在邮件里面给我发过代码 diff 细节,这种算是大佬给我喂饭吃了,我的理解我就可以加个 Suggested by 标签。
还剩下一些注意事项的话,我觉得就是一轮 Review 结束之后,需要重新发送完整的新版本补丁。特别需要注意的是,新版本补丁的 Cover Letter 里面需要注明修改了什么东西,方便 Reviewer 看。
内核文档写了发送补丁需要使用真名,因为需要 Signed-Off-by,不接受匿名。还有一个比较蛋疼的地方,就是除了发送完整补丁系列用 git send-email 以外。Review 讨论过程中 ,可以随便用普通的邮箱软件,不过需要注意的是,发送要用 plain text 模式,不要用富文本。另外,用 gmail 的时候,记得改一下自己的邮箱用户名。我的上勾拳网名,永远挂在了邮件列表里面,咳咳,还好没有起一些奇奇怪怪的用户名。上勾拳,相信每个安娜玩家看到都会微微一笑吧。
关于整个内核补丁提交的过程,我把我想到的细节都写了下来,有点啰里啰嗦的,可能会破坏阅读体验。但是,这是我刻意这么做的,只是想分享一下经历,希望能帮助到可能和我有相同需要的人,毕竟我这次提交的过程中,得到了大佬们的无私帮助,想把开源的精神传承下去。
关于开源社区的感悟
Linux 内核社区的 patch 文化
其实,我以前只是有所耳闻,内核社区全部都是以补丁的形式进行代码提交,可能一个很大的功能,会被拆分成很多个小补丁,甚至被分成好几个系列分批提交。我其实一开始没有感觉到这个做法的好处,而且在我这次补丁提交完成之后,我也很难有什么切身的体会。我倒也可以直面内心,不怕承认一个事实,虽然工作了八年多,但平时在公司里面搬砖,都是力大砖飞。不管有 AI 帮忙的时候还是很多年前,很多时候都是一个大功能一个 PR,里面 commit 寥寥无几,只要能稳定上线,不出故障,实现业务价值拿到 KPI,就是好代码。
但是我最近在 aya 社区进行了多次代码提交,让我对 commit 拆分的做法有了一些简单的感悟。我头两次提 PR 的时候,PR 描述里面写的比较认真,但是 commit message 就是一行话寥寥带过。Tamir 特别分享了一篇文章给我(how to write a git commit message),我才意识到 commit message 的重要性,但是还没有悟到,commit 的拆分也是核心灵魂之一。
后来,我断断续续在 aya 社区提交了一些 PR,其中有的 PR 大概有上百个 comment,持续了数个月之久。由于时间跨度长,给 Reviewer 带来了比较大的负担,这才让我认识到 commit 拆分的第一个好处:合理的 patch 拆分和提交,可以极大的降低 Reviewer 的心智负担。很多专业的 Reviewer 都是按照 commit 的维度按顺序去阅读代码的。正所谓与人方便与己方便,想要获得高质量的 Review,就得想办法降低 Reviewer 的心智负担。
紧接着的好处是,在把大功能拆分成多个独立的 patch 的过程中,可以提升对当前功能设计与实现的理解,甚至包括对整体项目的理解。除了这些理解的提升,我觉得对工程能力的提升也至关重要。因为把大功能拆接成各种独立 patch 的过程中,确保这些 patch 都可以被独立的理解,测试以及 Review,本身就在培养着自己的工程能力,逼着自己把事情想清楚,每一个 patch 都只做一件事情。特别是一些前置 patch 是重构或者抽象了某些中间层,为最后核心功能落地打下基础。
还有一个很重要的点在于,这种实现方式可以降低维护成本。想必大家都听过或者使用过 git bisect 的功能,这个其实就是在问题可以稳定重现的情况下,通过自动化脚本的方式,不断二分法切换 commit 来构建版本,测试看问题是否重现,直到找到引入 regression 的 commit 是哪一个。但是如果一个 commit 有几千行,那找到了又有什么意义呢?这几千行代码中,可能有 95% 的都是值得保留的,这个时候直接 revert 掉代码的成本就很高。需要人工来努力排查,到底是哪处改动引入了问题。更进一步的说,git bisect 要求项目历史树上,每一个 commit 都是自洽,并且可以独立运行的状态,这个要求其实绝大部分项目都很难达到。
开源社区和商业组织的区别
我觉得商业组织或者说以盈利为目的的公司,不管有着什么样的愿景来吹得天花乱坠,最关键的一件事情是保证赚到钱让自己活下去(当然最近 OpenAI 和马斯克在打官司 🤣)。而开源社区我觉得更多的是怎么保证代码被长期维护下去,而且有一个很重要的点是,开源社区里面,可能每一次贡献者都是一个陌生人,这里存在着信任关系的问题(毕竟开源社区恶意 PR 的事情也不少见),这对维护者来说,有着额外的精力耗费。
如果是一个公司内部,同事之间都会有默认信任,哪怕可能有的人准备要离职了,也基本会保持自己的专业度,毕竟江湖很小,做人留一线,日后好相见。也不用担心同事往代码里面塞后门,毕竟还有刑法来兜底。
突然又想起以前被鞭子抽的日子,每周二周四都凌晨发版本。发版前,有的同事反手掏出个几千行的 C 代码 PR 让我 review。PR 里面要么是数十个 commit 信息模糊的提交,要么是 squash 成了一个超大的 commit,那种感觉真是酸爽。我一般只能快速看一下影响面和功能正确性等问题,至于很多细节的东西,完全照顾不过来。组织运作的形式就是这样,我如果跟他们较真代码风格或者某些可维护性之类的东西,那基本是自讨苦吃,毕竟业务永远是第一位的。突然想起以前组里大哥夜里三点钟合并代码、早上六点钟发布功能,上午九点钟确定有问题,开始回滚,整个过程行云流水,一气呵成。我自己有几个出严重 Bug 的代码,每次看 commit,也都是在凌晨提交的。
另外,还有一点,就是公司里面,总是会考虑组织上人员的兜底,换句话说,一个合格的小组,应该是走了谁,都可以正常运转下去才对,实在不行还能多开几次 knowledge transfer 😂。而很多开源社区,我觉得很难做到这一点,所以开源社区需要对代码的可读性和可维护性有更高的要求,一个代码或者一个 commit,应该让一个素不相识的人,在若干年后,也能快速接手起来。
AI 真的利好开源吗
在我去年写的博客(两个月重度使用 AI Code Agent:普通一线程序员的思考和感想)里面,我认为 AI 是完全利好开源,那时候我还没有明白开源社区也是一种公开的组织形式。但现在我开始有了一点点不同的想法:大概就是 LLM 降低了代码生成和项目参与的门槛,但是项目维护者的负担开始变得越来越沉重,甚至可以说是 LLM 向 github 和开源维护者发起的 DDoS 攻击。
不过需要澄清的一点是,我不是在反对 LLM 工具的使用,相反我左手 Codex 右手 Claude Code,每天都在高强度使用,越用越开心。但是一个长久运行的开源社区强调的是代码的可维护性,能够让许多维护者顺利完成接力跑。当然有人会说 LLM 自己写代码,LLM 自己维护自己修,嗯,我觉得这个观点我不想去辩驳。但我觉得,一个长期维护的项目这么搞,以 LLM 存在的随机性和上下文限制,没有一些拥有工程品味和真正长期记忆的维护者,最后的结局肯定是:迭代变得越来越困难,修一个 Bug 牵一发动全身,维护不下去之后然后开始漫漫重写/重构之路。
我这里再次反思我使用 LLM 的方式,虽然我以前给开源社区贡献代码,虽然说没有在 Vibe Coding,还是很细致的反复思考和测试,确保了功能代码的正确性。但是我没有对代码实现细节有着更高的要求,比如上文里面那一个轮询 sleep 的操作,就不是很美观。另外,很多时候,代码写的很粗糙,特别是测试相关的代码。我觉得这些问题,我需要正视起来,特别是代码、注释以及 commit 如何具备更丰富、更精准的信息量,多去思考怎么和 LLM 进行 co-developing 把代码写得更容易维护一些。
如何参与开源以及个人成长
我之前一直在 github 上面写我自己的一人项目来自娱自乐,其实很少参加真正的开源社区协作。但是我感觉我可能开始慢慢领悟到开源社区应该怎么混了,其实关键要诀和在公司混基本是一样的,就四个字:建立信任。更具体一点,不仅要诀类似,甚至方法论都很接近。到了新公司,肯定是熟悉组织规则和价值观,用自己专业技能去解决团队目前面临的问题,先从小事做起,不断熟悉整个团队的流程和节奏,建立起初步的信任,然后再开始思考怎么更好的发挥自己的特长和价值。嗯,一个团队中的业务骨干就这么快速成长出来了。
而开源社区也是一样,不能上来就提一些大功能的 PR,先从小的 PR 开始,熟悉社区的代码风格和节奏。先为社区解决一些可能维护者没有时间处理的小痛点,再慢慢图谋大事。这个过程,感觉就是用真心换真心,维护者也是可以感受到贡献者付出的努力的。
另外,我觉得有一个特别关键的点在于,需要积极参与社区方案讨论以及代码 Review。其实这话是说给我自己听的,我还没有参与过开源社区的代码 Review,得切记不能埋头只顾着干功能,而是多参与维护性的事务,其实反而能学到更多东西。这个领悟,还是我去翻了 Kuniyuki 大佬的博客发现的,虽然是一篇日文博客,但是在 LLM 的帮助下,我还是领悟到了精髓。就是 Review 代码对于开源社区来说,比提交代码更重要。
这感觉其实也和个人成长息息相关,我在我自己的第一篇博客里面写了,我会把多动手去实践当做成为一个更好的程序员的必经之路。现在我觉得,多去参与开源社区,多去获得一些高质量的互动,也是成长之路必不可少的。虽然我已经离国内程序员 35 岁大限之日没几个年头了,并且现在 AI 来势汹汹,可能很多人觉得研究技术本身已经没有什么意义了,但是我依然觉得程序员是个挺有意思的职业,并且希望能 指挥 LLM 写代码写到退休。