Implementing QUIC from Scratch with Rust: MTU Discovery
Starting from why transport protocols need MTU discovery, this post analyzes why IP fragmentation can reduce performance and even hurt availability, then discusses common MTU discovery strategies, QUIC's approach, related Linux optimizations such as GSO, TSO, and GRO, and finally gives a few practical MTU configuration suggestions.
MTU Discovery
What Is MTU Discovery
First, we need to answer what MTU means. MTU, or maximum transmission unit, is the maximum IP datagram size that a data-link layer can carry. For example, if the link layer is Ethernet, the maximum Ethernet frame size is 1518 bytes. After subtracting the Ethernet header and trailer, 1500 bytes is the maximum IP datagram size that Ethernet can carry. That is the MTU.
We should also briefly introduce MSS, or maximum segment size. MSS is a TCP transport-layer concept. It is derived from MTU by subtracting IP and TCP header overhead. In other words, MSS is the maximum application data a single TCP segment can carry.
MTU discovery means discovering the minimum MTU across the entire network path between two devices. Some people may ask: both communication endpoints can know their own NIC MTU, and TCP even negotiates MSS during the handshake. Why do we still need discovery? The answer is in the diagram below. Between two TCP/IP endpoints, the path may be composed of multiple physical links, and the transport endpoints do not know the MTU of each link.
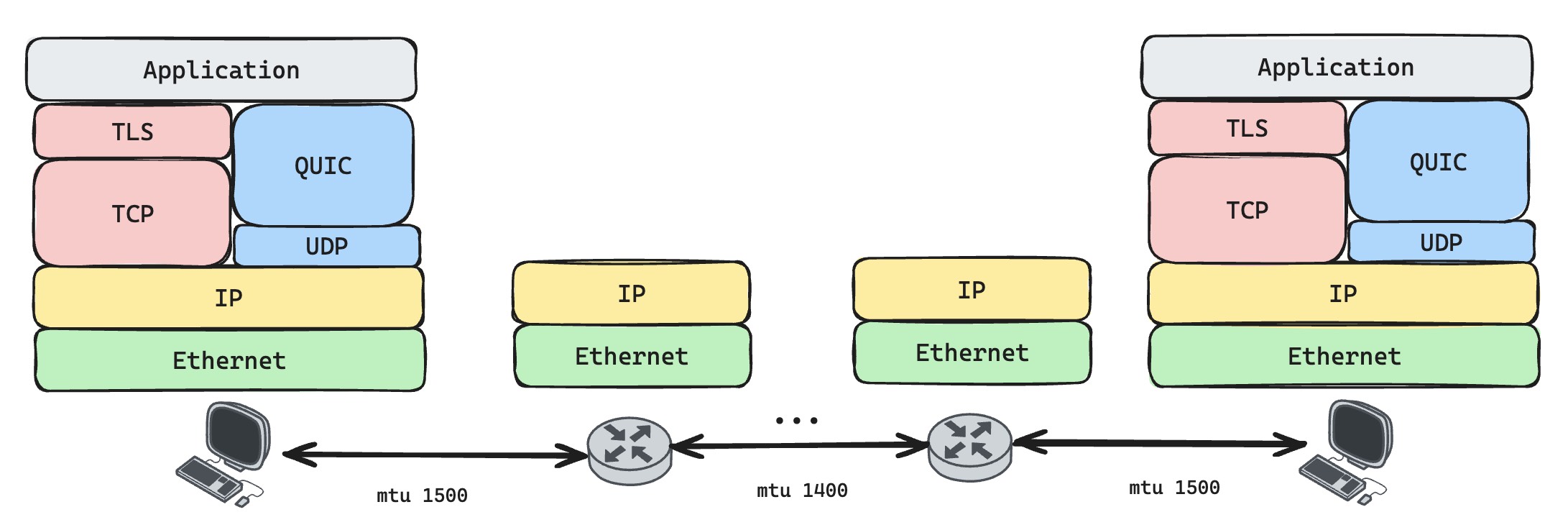
Also, a machine's configured MTU may be inaccurate. For example, a WireGuard virtual interface needs to subtract WireGuard's extra header overhead, but the TCP/IP stack running above it does not know that. WireGuard setups usually recalculate and configure MTU, but manual configuration always has the risk of being wrong. Only MTU discovery can reveal the real minimum MTU on the path.
Why We Need MTU Discovery
Now we can discuss the key question: why do we need MTU discovery, meaning discovery of the minimum MTU between two communicating devices? The standard answer is probably familiar: send data as close as possible to the path MTU, improve link utilization, and avoid IP fragmentation that hurts performance. I want to go one step deeper here and analyze why IP fragmentation hurts transport performance, and why it can sometimes even hurt availability.
A Brief Introduction to IP Fragmentation
IP fragmentation means the IP layer can split a datagram from an upper-layer protocol, or a datagram being forwarded, into multiple smaller IP packets for transmission, then reassemble them at the destination host's IP layer. The reason is that IP is the transport protocol closest to the physical link layer. To ensure data can actually be sent by the physical link, it must not exceed the MTU. If an upper-layer datagram, such as UDP or TCP, exceeds the MTU, the IP layer fragments it so the data can be transmitted normally on the physical link.
The details are described in the IP RFC. The IP header contains a more fragments flag and a fragment offset, allowing one large IP datagram to be split into smaller ones and reassembled at the destination host. One important point is the don't fragment flag. If an IP datagram carrying this flag reaches any intermediate device's IP layer, and the datagram is larger than the next-hop link MTU, the IP layer must drop it. This flag is also the foundation of MTU discovery.
Those are the common explanations. I want to go slightly deeper with Linux kernel source code. The questions are: when does IP fragmentation happen, how does the stack decide fragmentation is needed, when are fragmented datagrams reassembled, and when is a DF packet judged too large and dropped?
If Linux IP forwarding is enabled, receiving an IP packet mainly has two paths. One path confirms that the local machine is the destination, then hands the packet to the upper transport stack. The other path recognizes that the packet is not destined for the local machine, then forwards it according to the routing table.
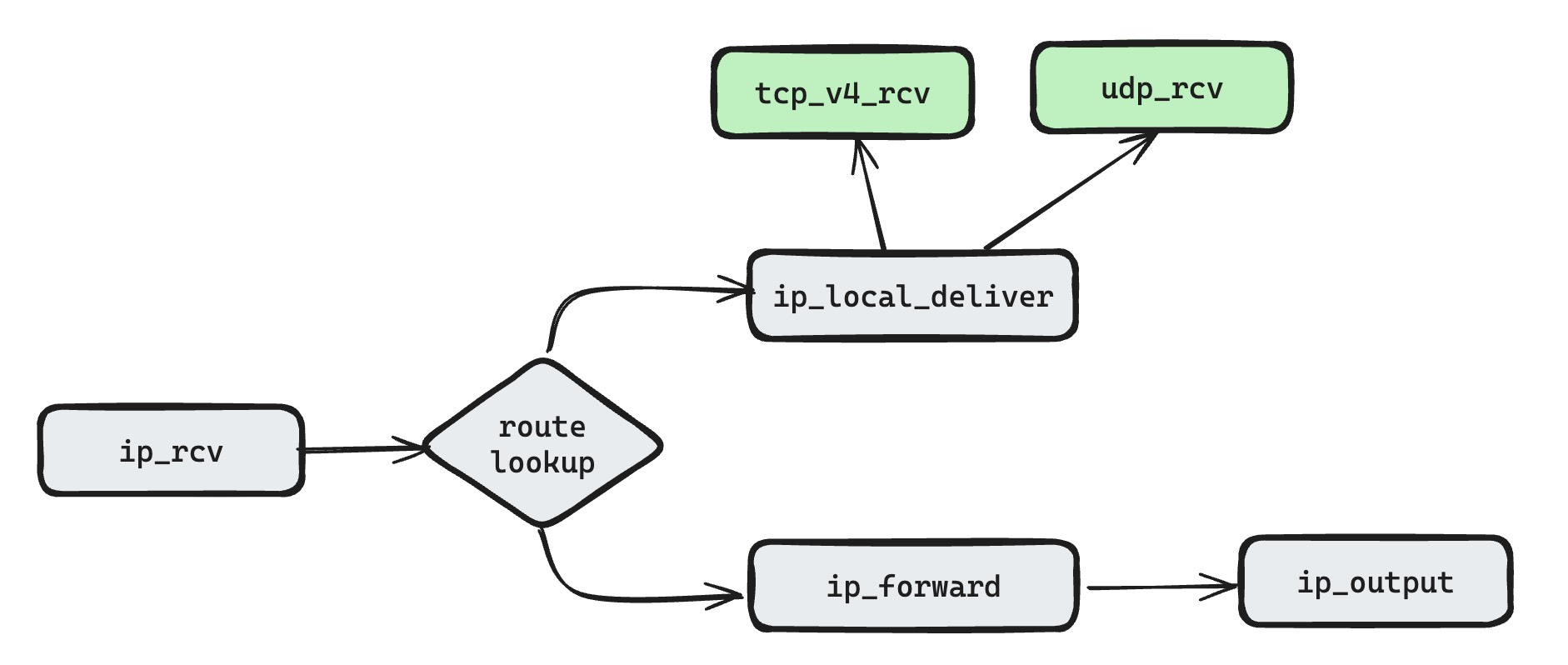
From the code perspective, Linux first handles IP packets through the ip_rcv entry point. After route lookup, if the packet has reached its destination machine, it is delivered to the upper protocol layer. In ip_local_deliver, Linux checks whether the received IP packet is fragmented and performs reassembly when needed.
If route lookup shows that the local machine is not the destination, Linux enters the forwarding path. ip_forward calls the IP output function ip_output. In that flow, Linux queries the next-hop MTU and decides whether fragmentation is needed. Also in the send path, Linux checks the DF flag and next-hop MTU to decide whether to drop the packet directly.
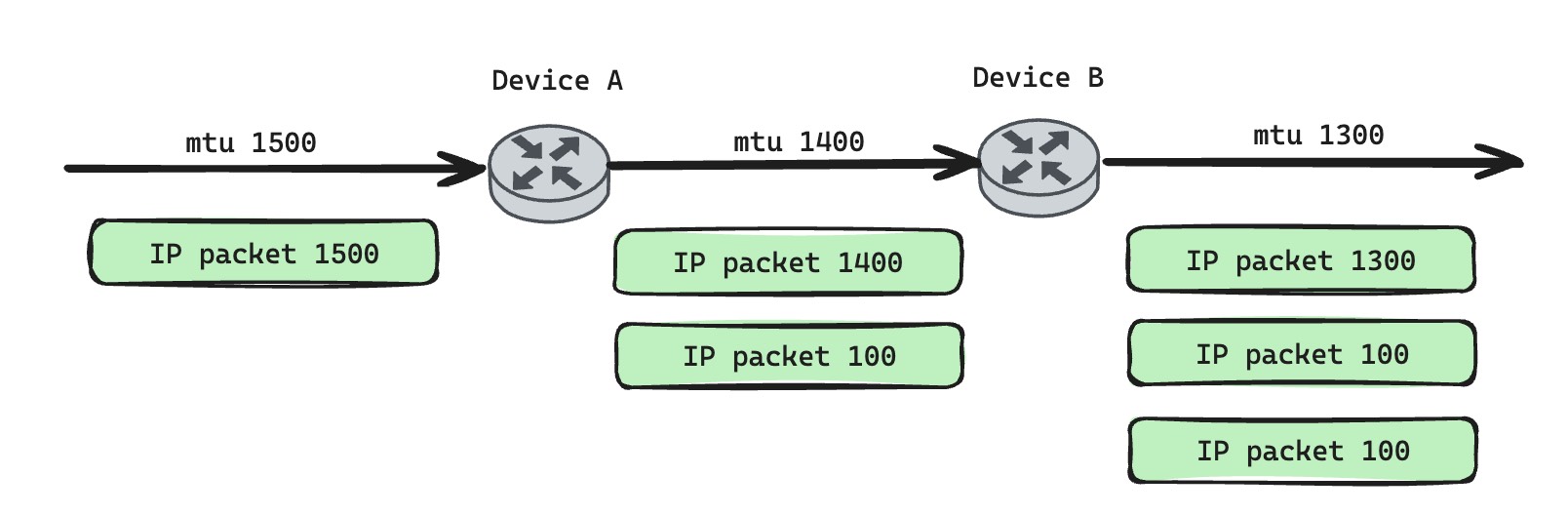
Here is an interesting edge case. If every physical link along a path has a smaller MTU than the previous one, can data be fragmented repeatedly? Or must an intermediate device reassemble fragments and then fragment again, which would violate the rule that reassembly only happens at the destination host?
For example, intermediate device A receives a 1500-byte IP packet, and the next-hop link to device B has MTU 1400. Device A fragments the 1500-byte packet into a 1400-byte packet and a 100-byte packet. Then device B receives the 1400-byte fragment and forwards it to the next hop, whose MTU is 1300. What should B do?
Normally, B can fragment the 1400-byte IP packet again. The IP packet design is simple enough that a fragment can be fragmented again. So the 1400-byte piece can become 1300 and 100 bytes, and the final three IP packets can be reassembled at the destination host. However, Linux defaults to forcing all IP datagrams carrying TCP traffic to include the DF flag, so in this scenario Linux would drop the fragment instead of fragmenting it again.
One detail: the 100-byte number above is only illustrative. Assuming no TCP options, a 1500-byte IP packet minus 40 bytes of IP and TCP headers leaves 1460 bytes of TCP payload. A 1400-byte IP packet can carry 1360 bytes of TCP data, so the remaining fragment's real size should be 1460 - 1360 + 40 = 140 bytes.
Why We Try to Send Close to the MTU Limit
Before discussing the harm of IP fragmentation, let's talk about why we want to send IP packets as close to the MTU limit as possible. The reason is simple: to improve transmission efficiency. If each IP packet can fill the MTU as much as possible, the same amount of data requires fewer IP packets. Packet headers make up a smaller percentage of the transferred data, which improves link utilization. Fewer packets also reduce protocol-stack processing, interrupts, and CPU usage. When CPU is the bottleneck, this can reduce buffer buildup caused by a saturated CPU and improve throughput. That is why high-performance data-center links may use Jumbo frames.
But is a larger MTU always better? Not necessarily. A classic counterexample is a high-loss environment such as Wi-Fi. Weak signals may cause packet loss, and transmission errors may cause packets to be dropped after CRC failure. When a larger IP packet is lost, more data must be retransmitted, which can reduce efficiency and increase latency. We are always trading one thing against another. Still, in general, using as much of the MTU as possible for IP packet transmission is a good practice. Later we will look at what the Linux TCP stack does to achieve this.
The Cost of IP Fragmentation
How It Affects Transport Performance
There is no doubt that IP fragmentation hurts transport performance. But I became curious about exactly how much it hurts and in what way.
In principle, fragmentation and reassembly increase system resource costs. Clearly, avoiding IP fragmentation has a system-performance advantage. Fragmentation also hurts transport efficiency because passive fragmentation makes it impossible to ensure each IP packet fully uses the link MTU. Finally, in weak networks, if any packet after fragmentation is lost, the IP layer has no retransmission mechanism, so the upper transport layer, such as TCP or QUIC, must retransmit. Loss of any fragment requires retransmitting the whole pre-fragmented data, which increases retransmission cost. More IP packets also increase the probability of loss. Packet loss also affects loss-based congestion control windows, further hurting transmission efficiency.
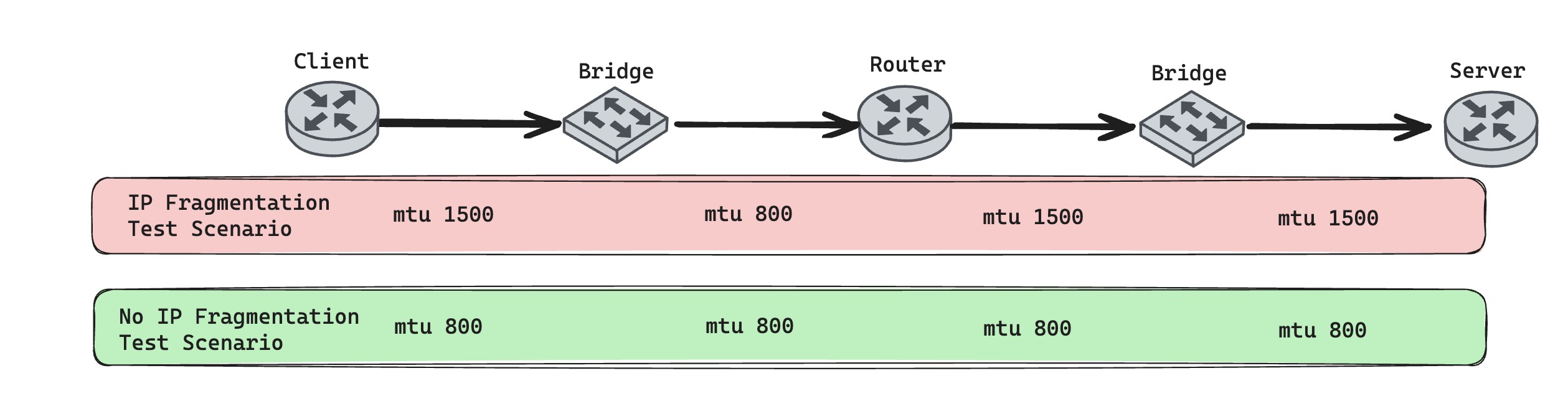
At this point I had a strange thought. If fragmented packets can still fully use the link MTU, maybe only system resource cost increases. If system resources are not the bottleneck, perhaps throughput is not affected much. I could not resist writing a script to test it.
To simulate a path with multiple links and a lower intermediate MTU, I used namespaces, veth, and bridge on a Linux host. I started an iperf3 server in the Server namespace and an iperf3 client in the Client namespace to test throughput.
| Test condition | Path MTU | IP fragmentation | Average throughput (Gbits/sec) |
|---|---|---|---|
| Intermediate router fragments 1500-byte packets into two roughly 800-byte packets | 800 | Yes | 2.04 |
| Original transmission, no IP fragmentation needed | 800 | No | 2.28 |
I chose MTU 800 because, in the fragmentation scenario, when a 1500-byte IP packet reaches the router and is split into two packets close to 800 bytes, the link MTU is still used as fully as possible. This helps compare mostly system-resource overhead. In that test, the fragmented case averaged 2.04 Gbits/sec, and the non-fragmented case averaged 2.28 Gbits/sec. The difference was small. If the intermediate MTU is changed to 1200, the fragmented packets become roughly 1200 and 300 bytes, so the link MTU is not fully used, and the throughput gap becomes more obvious.
| Test condition | IP fragmentation | Average throughput (Gbits/sec) | TCP retransmits | Client packets sent, relative |
|---|---|---|---|---|
| Server simulates 1% receive loss; intermediate router fragments 1500-byte packets into two roughly 800-byte packets | Yes | 1.47 | ~25,000 | Half |
| Server simulates 1% receive loss; no IP fragmentation needed | No | 1.72 | ~29,000 | Full |
Of course, this test is casual and only useful as a simple reference. In a healthy network, if fragmentation does not hurt link utilization, the impact on throughput may be smaller than we imagine.
I also tested a weak-network scenario. In the Server namespace, I used eBPF XDP to simulate 1% receive loss, then again used iperf3. The fragmented case averaged 1.47 Gbits/sec, while the non-fragmented case averaged 1.72 Gbits/sec. The difference did not look enormous. I also used bpftrace tcpretrans in the Client namespace to count TCP retransmissions. The fragmented case had about 25,000 retransmits, while the non-fragmented case had about 29,000. Since fragmentation happened in the Router namespace, the Client sent roughly twice as many packets in the non-fragmented case as in the fragmented case. So the fragmented case had a higher retransmission rate. From this, we can clearly feel that IP fragmentation amplifies loss probability when loss exists.
Another interesting point: on newer Linux systems, simulating IP fragmentation is not easy. My script includes many extra settings for this. First, GSO, TSO, and GRO must be disabled. I will introduce them later. Second, all MTU discovery features in Linux must be disabled so Linux does not set the DF flag for TCP-carrying IP packets. Only then can fragmentation really happen on a later link whose MTU is too small.
Security Risks of IP Fragmentation
Besides performance loss, IP fragmentation also has security issues. The most obvious risk is a flooding attack against a destination or intermediate device: send many invalid partial fragments. The target must cache incomplete fragments while waiting for reassembly. Even with reasonable cache expiration, CPU or memory can be exhausted, causing denial of service.
Since devices must cache fragments for reassembly, bugs in that logic are easy for attackers to exploit, especially in edge cases. For example, fragments in the same group may have overlapping data ranges. The well-known teardrop attack used this. Attackers may also deliberately construct illegal fragment sizes to test whether reassembly logic is robust. These attacks should mostly affect very old devices. Modern systems should not have such vulnerabilities, given that IP fragmentation is older than I am.
However, many middleboxes with firewall capabilities must reassemble fragmented packets to inspect the real traffic. Firewalls often start checking fragments before full reassembly is possible, so they can drop abnormal fragments early and defend against attackers. As a result, IP fragments may be dropped directly under strict firewall policies, which can make the transport layer unusable.
MTU Discovery Strategies
Path MTU Discovery
The old RFC 1191 defines PMTUD. The core mechanism is that the source host sets the Don't Fragment flag. If a link on the path has an MTU smaller than the IP packet length, the intermediate device drops the packet and returns a Packet Too Big ICMP message. The source host adjusts its sending MTU based on the ICMP message until it satisfies the minimum requirement of the path.
Here is an interesting observation. TCP PMTUD has been enabled by default since Linux 2.x, but in forums I often see people who misconfigure MTU, especially after using tunnels such as WireGuard, and then find that networking is almost unusable. Did PMTUD fail? I think this is because ICMP messages have security risks, so many middleboxes block ICMP. This creates the ICMP black hole problem. PMTUD depends entirely on Packet Too Big ICMP messages. If ICMP is black-holed, PMTUD cannot discover the accurate path MTU.
Before analyzing ICMP security risks, let's look at how a normal Linux system handles Packet Too Big. The Packet Too Big ICMP format carries the IP header and the beginning of the TCP header that triggered the ICMP message, so the TCP stack can validate it. When the TCP stack processes ICMP, it checks the four-tuple and TCP state. Only ICMP messages belonging to a real TCP connection are processed further. As usual, the TCP stack also validates the sequence number, requiring it to fall inside the receive window. Finally, where Packet Too Big is actually handled, the MTU is adjusted dynamically.
Based on these validation steps, we can analyze possible ICMP security risks. Although the Linux kernel does these checks, an attacker can still construct many ICMP messages and try to pass the TCP four-tuple and sequence-number validation. If successful, the attacker can provide a smaller Next-Hop MTU and reduce connection efficiency. RFC 5927 also provides countermeasures, such as minimum MTU thresholds to avoid being reduced to unreasonable values.
In addition, firewalls and middleboxes often block or limit ICMP. Tools like traceroute can use ICMP responses to probe network topology, causing information leakage. ICMP flooding is also a threat. Specific ICMP messages can affect TCP stack availability as described above. A Cloudflare blog post also records a case where ICMP packets were lost due to complex network topology. Finally, ICMP itself is not reliable and may be lost, which also hurts PMTUD efficiency. Since ICMP-based PMTUD has so many problems, what else can we use for MTU discovery?
Packetization Layer Path MTU Discovery
PLPMTUD appeared to handle ICMP black holes better. Its core idea is to use the TCP transport layer's acknowledgment mechanism to decide whether an IP packet carrying the DF flag reached the destination. This removes the dependency on Packet Too Big ICMP messages.
Of course, this introduces many questions. The first is: how do we determine that the packet used for MTU probing was lost? Network loss can happen for many reasons, most commonly congestion. So the TCP stack must combine current network conditions to decide whether the probe was likely lost due to MTU limits. Since this is a judgment, errors are inevitable.
There are also many implementation details. Today, TCP stacks can only use real application data for MTU probing, which creates data-loss risk and can hurt performance. UDP-based transport protocols such as QUIC usually implement MTU discovery based on DPLPMTUD, trying to use non-application data for probing so real business data is not affected. Those probe packets are still controlled by the congestion window. If a probe packet is lost, the implementation should also avoid shrinking the congestion window unnecessarily, because mainstream congestion control algorithms are still loss-based.
Probe Strategy
Ignoring the feedback mechanism, both PMTUD and PLPMTUD face many choices. What MTU value should be probed first? What range should later probes cover? Should we use binary search to quickly find the exact MTU, or only probe common MTU values in modern networks? What should failure and fallback look like? Should we retry after failure or fall back immediately? How often should probing happen? Can it handle dynamic MTU changes on the path? If probing is too frequent, bandwidth is wasted. If it is too infrequent, the MTU may stay too low and efficiency suffers.
These are common engineering trade-offs. I think a QUIC stack should provide flexible configuration to the application layer, so users can make final choices based on their business shape and concrete quality data, and even update these strategies dynamically when needed.
Some Interesting Details
Should the DF Flag Be Forced On?
Since IP defines the Don't Fragment flag to avoid fragmentation, should we force DF on for real traffic instead of only for probe packets? The answer is clear: yes, every IP packet should carry DF so fragmentation does not happen along the path. The premise is that the transport layer supports MTU discovery, and preferably PLPMTUD. Otherwise, an ICMP black hole alone is enough to make life painful.
Another piece of evidence is that IPv6 removed the DF flag from the protocol design. All intermediate devices are forbidden from fragmenting IPv6 packets. Only the source host can fragment IPv6 packets. In practice, even source-side fragmentation usually should not happen. If MTU is configured correctly, TCP will not foolishly hand the IP layer a segment larger than the current link can carry. Tunnels such as WireGuard can make TCP calculate MSS incorrectly, but TCP will quickly correct MSS again through MTU discovery.
Linux forces the DF flag on for TCP traffic by default. An interesting detail is that this forced DF behavior is tightly coupled with whether PMTUD is enabled in the Linux kernel. As mentioned earlier, Linux enables PMTUD by default, so TCP traffic has DF enabled by default. Linux does not force DF for UDP traffic, so applications usually need to set it according to their own needs.
What MTU Values Are Common in Modern Networks?
The IPv6 RFC requires links that support IPv6 to have an MTU of at least 1280 bytes. So we can roughly expect modern network MTUs to be above 1280 bytes. A Cloudflare blog post also gives real-world MTU distribution data, which is very useful. This is why many tunnel configurations recommend MTU 1280. I checked the Tailscale virtual interface on my machine, and its MTU is also configured to 1280 bytes by default. Very conservative, very stable.
What If MTU Changes Dynamically?
This is a low-probability scenario, but it must still be considered. It can happen when the routing path changes, causing the minimum MTU along the path to change. I have not worked for an ISP, but I guess routing paths may be adjusted for cost, quality, or failure recovery. If you use dynamic routing acceleration services, underlying path changes are also possible. Still, even if the route changes, MTU only changes if the new path has a different minimum MTU. Another more common case is turning VPN or tunnel software on or off during transmission.
MTU discovery usually starts when a TCP connection is established, while dynamic MTU changes may happen during active transmission. TCP stacks can handle this scenario. If MTU changes, the TCP stack uses the same PMTUD or PLPMTUD mechanisms as before. It watches for events such as large datagram loss or ICMP messages, judges whether loss happened because of MTU mismatch, then dynamically adjusts MTU and probes again to keep transmission stable. QUIC defines connections differently from TCP, so besides those events, QUIC also requires MTU discovery to run again after connection migration.
Engineering Practice
Network Programming Details
First, a familiar question: when writing TCP network programs, do we need to consider MTU? The answer is no. Forcing application data to be split by MSS before calling socket send on a TCP socket is a lot of work for little benefit. If tunnel VPN software is enabled, the extra header overhead alone is already hard for the application layer to calculate, and the application may not even be aware of it. Even if the business environment is stable and the application knows whether tunnels exist, TCP options can still affect the calculation. TCP options are not only present during handshake packets. Even if the application obtains the current TCP MSS, it still cannot accurately calculate the maximum TCP payload length.
More importantly, from socket send to TCP segment construction, the TCP stack applies many optimizations. The application cannot control TCP segment size simply by choosing a send length no larger than MSS. TCP does a lot for us. The application only needs to put data into the TCP stack through system calls. The TCP stack ensures packets do not trigger IP fragmentation while still using the current path close to its MTU limit. Developers normally do not need to think about whether IP fragmentation will happen or whether MSS is fully used.
One interesting TCP option is TCP_CORK. I first learned about it while investigating high production data-transfer latency. When the application enables it, the TCP stack actively aggregates data in the send queue until its length reaches the current MSS, then sends a TCP segment to the IP layer. It is usually enabled for large transfers to aggregate data and reduce IP packet count, then disabled when the application has finished sending. However, modern mainstream Linux systems support GSO and TSO, so I think TCP_CORK is less useful for large transfers than it used to be.
Now let's talk about UDP. One interesting question is: what is the maximum size of a UDP datagram? The UDP header carries a two-byte length field for the whole UDP datagram, so the theoretical limit is clearly 65535 bytes. But the UDP header follows the IPv4 or IPv6 header, so UDP maximum size is also constrained by IP header length fields. In IPv4, the header length field is two bytes and represents the full IPv4 packet length. So the maximum UDP payload under IPv4 is 65535 - 20 - 8 = 65507 bytes. In IPv6, the length field represents the IPv6 payload length, so the maximum UDP payload is 65535 - 8 = 65527 bytes. I looked into this because, while implementing QUIC MTU discovery, I wondered what the maximum probe upper bound should be.
Another issue is that UDP does not rebuild application data into transport segments the way TCP does. Each UDP send creates a new UDP datagram. If the UDP socket enables DF and sends data larger than the current NIC MTU, accounting for IP header length, send returns EMSGSIZE (Message Too Long). The application should handle this error. UDP is not as capable as TCP. TCP actively reads the next-hop MTU and calculates the correct MSS. UDP-based transport protocols should handle these errors and adjust their MTU in time instead of only waiting for probe loss or ICMP messages.
TCP MTU Discovery Implementation Details
Linux TCP MTU Configuration
The official Linux documentation lists many MTU-related settings, most of which correspond to topics above. For example, ip_no_pmtu_disc controls PMTUD. Linux enables PMTUD by default, and importantly, this setting also determines whether TCP traffic has the DF flag underneath.
There is also the PLPMTUD switch, tcp_mtu_probing. It is disabled by default. Normally, I would prefer enabling it. Another setting is tcp_base_mss, the probing lower bound when PMTUD or PLPMTUD fails. It helps defend against ICMP attacks that maliciously lower MSS. If TCP handshake does not negotiate MSS through the MSS option, the TCP stack also uses tcp_base_mss as the default MSS.
Speaking of the TCP MSS option, there is also a blunt but common solution: MSS clamping. Routers or firewalls can modify the MSS option in TCP SYN packets to limit the maximum segment size of TCP connections passing through the device, avoiding path MTU problems such as PMTUD failure due to ICMP filtering.
The documentation also includes MTU cache settings, such as mtu_expires and max/min MTU ranges in the cache. Yes, Linux maintains a global cache for MTU discovery results to improve efficiency. We can use ip route get {dip} to inspect specific cache state, and ip route flush cache to clear it.
Packet Capture Analysis of TCP PMTUD and PLPMTUD
Next, we can construct a scenario and use packet capture to show how TCP PMTUD and PLPMTUD actually behave on Linux. We reuse the previous script, but modify the MTU setup commands so the path MTU looks like the diagram below. Then we can reproduce PMTUD and PLPMTUD separately.

The following capture shows PMTUD. Since Linux enables PMTUD and disables PLPMTUD by default, no extra configuration is needed. Capturing packets in the Client namespace shows PMTUD in action. A timely Packet Too Big ICMP message lets the TCP stack quickly adjust MSS and rebuild retransmitted TCP segments that satisfy the new MSS. This does cause application data to be retransmitted, so it slightly affects performance.
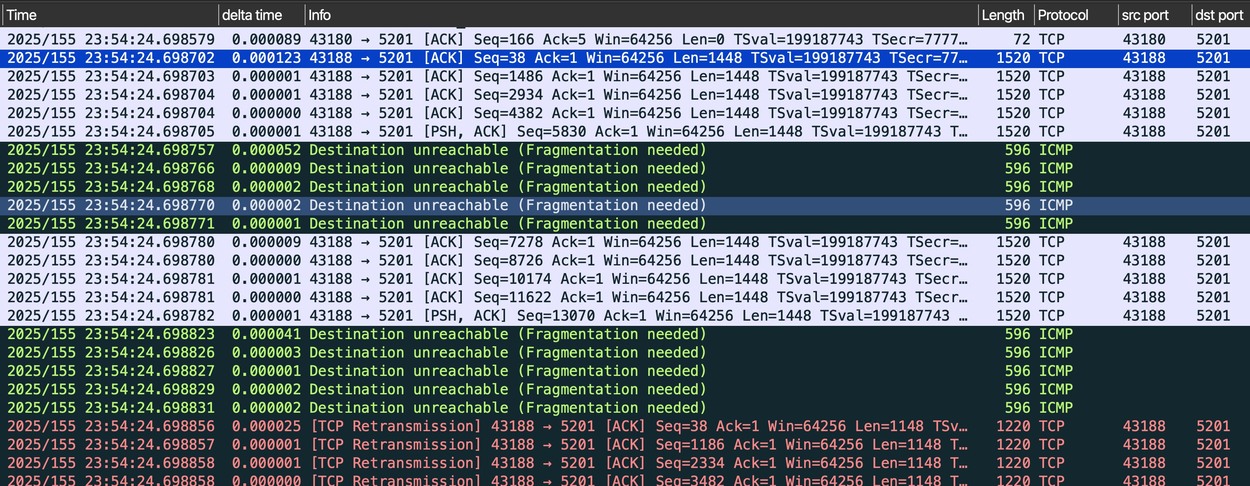
Reproducing PLPMTUD requires a few details. First, drop all ICMP traffic in the Router namespace to ensure PMTUD does not work. Also, because Linux ties PMTUD configuration to DF flag behavior, PMTUD and PLPMTUD both need to be enabled. Linux MTU cache also matters, so remember to flush the cache when repeating tests.
In the PLPMTUD capture, we can see PLPMTUD send a probe packet through the application stream that is slightly larger than other packets. Although no ICMP message arrives, PLPMTUD can quickly infer from duplicate ACKs that the data was probably dropped due to MTU limits, then retransmit only the probe packet. The process looks quite smooth.
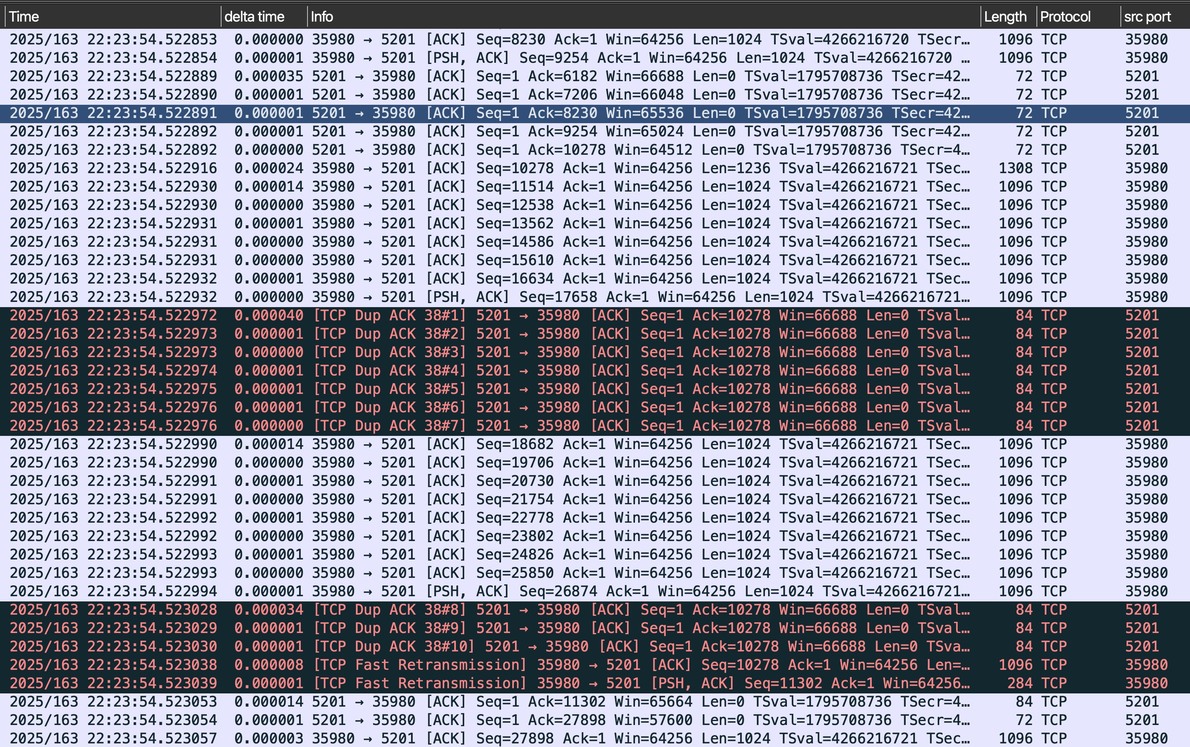
One final point: if PLPMTUD is deliberately disabled, and ICMP is blocked while the intermediate-link MTU is low, the Linux TCP stack cannot work normally. In other words, if there is an ICMP black hole and the real path MTU is smaller than the MSS negotiated by the two TCP endpoints, only enabling PLPMTUD allows Linux TCP to function correctly. So if you use tunnel protocols such as WireGuard, it is best to enable PLPMTUD.
QUIC MTU Discovery Implementation Details
You may notice that QUIC has no MSS concept. But during handshake, QUIC negotiates a related value similar to TCP's MSS option: max_udp_payload_size. It means QUIC packets should not exceed the negotiated value. Of course, max_udp_payload_size only represents the physical-link capability of each endpoint. It does not include intermediate links on the path, so MTU discovery is still required. Another interesting detail is that the QUIC RFC explicitly states that the maximum UDP payload is 65527, exactly as mentioned above for IPv6 carrying UDP with only the UDP header subtracted.
For QUIC MTU discovery, we choose the more generally applicable PLPMTUD approach. The IETF has a dedicated PLPMTUD RFC for datagram transports: DPLPMTUD. It extends PLPMTUD to connectionless datagram protocols. QUIC is a UDP-based connection-oriented transport, but it still benefits from it.
In TCP, both PLPMTUD and PMTUD use real application data for MTU probing. We discussed the trade-offs above. DPLPMTUD assumes connectionless datagram protocols may not have message acknowledgments, so it requires specially constructed probe packets. QUIC uses Ping Frame plus Padding Frame, and Ping Frame is ACK-eliciting. So QUIC avoids using real application data as probes. This prevents real data from being lost due to MTU limits, improves efficiency to some extent, and simplifies loss-detection decisions.
However, most open-source QUIC libraries do not specially handle dynamic MTU shrinkage. If a QUIC stack completes MTU discovery and then the MTU later shrinks for some reason, the stack may become unusable. feather-quic does not optimize this either.
The QUIC RFC also emphasizes how to handle ICMP messages. Some people may wonder: if we already choose PLPMTUD, why consider ICMP? My answer is simple: use both hands. The protocol layer has very little information about MTU-caused loss. It basically has two classes of signals: Packet Too Big ICMP messages, and MTU probe loss or consecutive large-packet loss. The latter requires combining multiple factors and is less accurate than ICMP. When there is no ICMP black hole, ICMP is definitely more accurate and timely.
Of course, ICMP has security issues. We already discussed how TCP validates ICMP. Now let's look at how QUIC authenticates whether an ICMP message belongs to a QUIC connection.
Receiving an ICMP message from a UDP socket does not mean the UDP socket four-tuple was validated, especially because many QUIC connections may share the same UDP socket. Also, QUIC does not identify connections by UDP four-tuples, so even validating the UDP four-tuple would not help much. QUIC also cannot directly validate a sequence number against the receive window like TCP, because QUIC packet numbers are encrypted and ICMP does not carry them. What can we do?
RFC 9000 gives a solution. ICMP messages carry the beginning of the packet that triggered them. Normally, MTU discovery happens after connection establishment, using QUIC Short Header packets to carry probe data. The raw data carried by ICMP is therefore the QUIC Short Header, which contains the DCID. We can use that DCID to judge whether the ICMP message belongs to the QUIC connection. There is still attack risk, but the attack cost is higher.
But the RFC is actually more concerned with a hidden problem. If UDP datagrams carrying QUIC are forwarded by a layer-4 load balancer, they may not be forwarded to the node that owns the service state. QUIC-LB solves this through QUIC Connection ID. For ICMP to return to the machine that sent the QUIC probe, it is best for the ICMP payload to include the probe sender's SCID. But QUIC Short Header does not carry SCID.
The QUIC RFC proposes a very cool solution: in the UDP datagram corresponding to a QUIC probe, first assemble a QUIC Long Header packet, then assemble the QUIC Short Header probe packet. This way, the raw data carried by ICMP is the QUIC Long Header, letting the ICMP message be forwarded by layer-4 infrastructure back to the true source machine. Someone may ask: the keys for QUIC Long Header were discarded long ago, is that a problem? No. The QUIC stack automatically drops QUIC packets whose keys have been discarded, then continues processing later QUIC data. The QUIC length field is not encrypted, so it does not prevent the following probe packet from being processed normally.
GSO, TSO, and GRO
A Strange Packet-Capture Observation
Many people try to observe PMTUD or PLPMTUD through packet capture. That is normally reasonable. Common capture tools such as Wireshark and Tcpdump capture at the data-link layer. On receive, capture happens before IP-layer processing, such as before IP fragment reassembly. On send, capture happens after IP-layer processing, meaning after IP fragmentation. So we should be able to see TCP segments split according to current MSS, infer the TCP stack's current MSS value, and observe whether IP fragmentation happened.
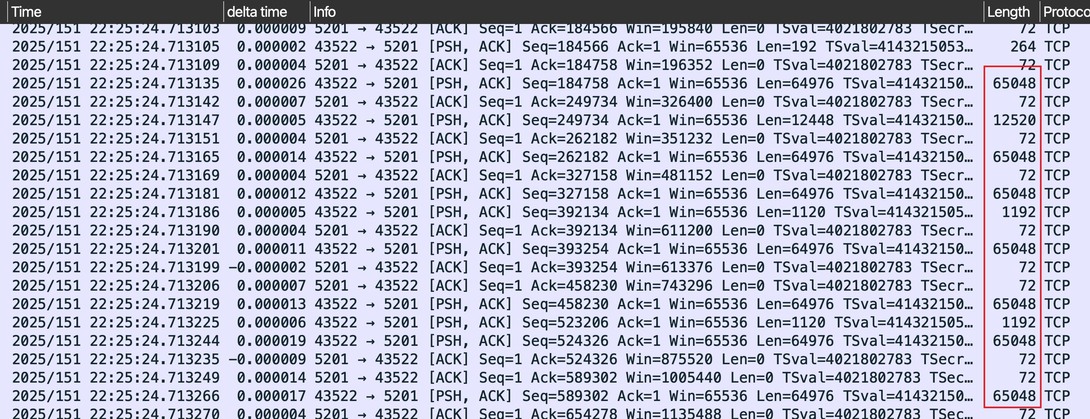
However, on newer Linux kernels, if you capture on the source host, you are likely to see IP packets far larger than the current NIC MTU. Do not doubt your eyes. The culprit is GSO or TSO.
What GSO, TSO, and GRO Are
The core idea of TSO and GSO is that when the TCP transport layer builds segments, it no longer splits strictly by MSS. Instead, it builds a giant TCP segment and gives it to the IP layer. Later, when data is actually sent by the NIC, it is split into proper TCP segments according to MSS. Now we know why observing real TCP segment length through packet capture can be so hard: the real MSS-based segmentation may happen after packet capture.
The main difference between TSO and GSO is where segmentation happens. TSO requires NIC hardware support. The NIC hardware performs segmentation. GSO is Linux's software fallback when TSO is not supported by hardware. It splits large packets into TCP segments in the driver layer. Obviously, TSO is more efficient. The reason for doing this is to reduce Linux kernel overhead and improve network throughput. TCP/IP stack execution, especially segment splitting and construction, costs CPU. Moving it to hardware or the driver reduces packet count, soft interrupts, and lock contention, so performance improves.
GRO works on receive. The Linux kernel merges multiple consecutive TCP segments or UDP datagrams with the same four-tuple into one large packet, passes it up the stack, and finally lets the TCP or UDP stack process it. The goal is similar: reduce system overhead and improve throughput.
Related Questions
When doing TCP network programming, applications do not need to be aware of GSO, TSO, or GRO. For a TCP socket, all offload effects are handled inside the TCP stack. Whether receiving or sending giant TCP segments, the TCP stack owns the full process. The application just reads and writes the TCP socket normally.
UDP applications are different. Each UDP socket send creates an independent UDP datagram, because the UDP layer is simple and barely interferes with datagram construction. If a UDP application wants to use GSO or TSO when sending data, it must explicitly use UDP_SEGMENT through sendmsg and provide the UDP max payload size. As mentioned above, UDP applications need to maintain that value themselves. Only then will the kernel use GSO or TSO for UDP traffic. The Cloudflare post on accelerating UDP packet transmission for QUIC gives detailed usage and performance comparisons.
For GRO, UDP applications do not need special handling. GRO only merges UDP datagrams with the same size and four-tuple. The UDP layer automatically splits the giant UDP packet for the application, so the application can read the original datagrams normally.
Do GSO and TSO conflict with MTU discovery? Of course not. I was curious about this at first too, because GSO and TSO work at lower layers, and I worried that the MSS dynamically maintained by TCP would be hard to apply there. After reading the code, I found that Linux passes down the live MSS, so MTU discovery results are not wasted.
For UDP-based protocols, as mentioned earlier, MTU discovery results maintained by the UDP application can also be passed to GSO and TSO through cmsg_len in sendmsg. If tunnel software such as WireGuard is involved, does it affect GSO or TSO? That depends entirely on whether the MSS or UDP max payload passed to GSO/TSO is accurate. In other words, it depends on whether MTU discovery is good enough.
Another question: does GRO affect reassembly of fragmented IP packets? This question gave me a headache, so I read the code. I found that Linux places strict restrictions on GRO, and fragmented IP packets do not enter the GRO optimization path at all.
What if GRO is applied, but after the packet reaches the IP layer, Linux finds it is not the destination host and needs to forward it? Linux has a clever solution: after GRO aggregates a large skb, it marks the skb with GSO. If the IP layer later finds the packet is not for the local host and cannot deliver it to the TCP stack, forwarding will use GSO logic to split the merged skb again, preserving correct behavior. TSO is not chosen here because GSO is purely implemented in the kernel and has no hardware dependency, while TSO may be absent.
Epilogue
Writing this post took longer than I expected, and it feels a bit wordy. The feather-quic code was finished quickly, but its completeness is not especially high, and some details mentioned above are not handled. One reason is that, although I have implemented MTU discovery before, I have not done Linux kernel protocol-stack development, so many details required extra thinking. Another reason is that I started playing EA FC 25 again. I secretly opened a new account, violating the ancestral rule. My main team Chelsea won the Conference League, and EA released a set of champion player cards. I could not resist. In my wife's words, I relapsed. Late-stage patient.
Finally, after talking this much about MTU discovery, it would be unreasonable not to give any MTU configuration advice. For people who like playing with routers, especially those who use tunnel software for intranet traversal, it is best to enable PLPMTUD. If problems still happen, just set MTU to 1280. It is small enough to survive extra tunnel overhead and avoid intermediate-link MTU limits, but not so small that transmission performance becomes terrible.