程序员的自我修养:如何用好 GDB
前言
现在已经是 2025 年的末尾了,这个世纪已经过去了四分之一,更严峻的是,距离 AI 达成统治二进制世界的终极计划,可能已经没剩多少时间了(不相信的,可以看看美股的股价,以及 OpenAI 左脚踩右脚的梯云纵绝活😂),所以,我想与时俱进,写一篇关于在 AI 时代下如何才能使用好 GDB 的博客。
我大概几年前看到过一个很棒的 Youtube 视频(Give me 15 minutes & I'll change your view of GDB),讲道理,这个视频确实没有标题党,让我立刻意识到一个残酷的事实:每天都在高强度的搬砖,我居然对我一直都在使用的工具还有那么多细节不清楚。那一瞬间,我立刻陷入了焦虑的情绪,我心里暗暗发誓,我一定要深度研究下 GDB,把它玩的很溜才行。
当我雄心壮志的打开了 GDB 的官方文档和社区资料,在“仔细翻阅”之后,我心里充满了卧槽,这么多内容,哪怕是 GDB 的维护者,也不太可能熟悉每一个命令和实现的细节吧。嗯,可能我这辈子也无法精通 GDB 了,也许,我应该把时间花在刀刃上,酒馆战棋,启动。
在此之后,我一直在思考一件事,如果我对 GDB 的底层原理理解的比较到位,是不是 GDB 的很多使用细节,或者说一些冷门绝活,对我来说,只是一个 know unknowns 的问题。所谓的 know unknowns,主要是说我们比较清晰的知道还有哪些事情我们还不知道,某种程度上,我觉得这是一切尽在掌握的低配版。换到 GDB 这件事情上,举个最简单的例子,我知道 GDB 有能力根据去中断正在运行时程序的某处指令上,获取某个变量值,并且做一些自定义的处理判断,但我并不知道具体如何使用 GDB 去做到这件事情。
而现在 AI 工具的流行,某种程度上是极大的降低了搞清楚 know unknowns 问题的成本,同时又让我们对底层原理的理解变得更加重要。毕竟,只有知道自己手头 GDB 运行机制和局限性,才能在 AI 降智、不靠谱的时候,正确的反驳 AI 的结论,让手头的 GDB 真正成为自己武器库里面的一大利器,换个说法,也就是不被 AI 牵着鼻子走。话说,我已经很久没有自己从头开始分析进程 crash 之后生成的 Coredump 文件了,都是 AI Agent 在分析,哪怕在一些信息缺失的情况下,都能快速找到 crash 发生的位置,并且结合源码给出相对靠谱的分析结果。但 AI 肯定不是万能的,总有一些蛋疼的 case,如果我们对这些原理和细节的理解有误差,那么也很容易被 AI 带到死胡同里面。
进一步来举一反三的话,我觉得应该是现在绝大部分技术领域,这样的场景会越来越常见:清楚底层细节,更好的提出问题,才能在 AI 工具的助力下更快速的解决现实中的实际问题。换而言之,这可能也是道与术的区别,道是我们对底层规则原理的理解,术是细节以及实际操作,也就是 know unknowns,当然我们不能重道而轻术,毕竟术的实践结果是可以反向修正我们对道的理解,正所谓以道摄术、由术证道(我可能最近网络小说看的走火入魔了😓)。
我大概是前年的时候,闲得蛋疼,自己动手用 Rust 写了一个极简版的仿 GDB 调试工具,由于写的过于丑陋了(功能和代码实现层面上都是),所以我完全没有把代码开源出来的想法。但比较幸运的是,那个时候 AI 代码工具还不够流行,所以我不得不完全手搓,踩了不少坑,学到了不少东西。另外,我最近在写我的个人项目 ghostscope 的时候,也在疯狂研究 GDB 的实现细节。这些操作,某种程度上,让我有了一些想法和冲动,来写这篇文章,聊一聊我对 GDB 背后的细节理解,以及这些细节是如何帮助我更好的理解和使用 GDB 的。当然,如果我有错误或者理解不到位的地方,也欢迎随时通过邮件向我指出。
二进制的战争迷雾
我觉得应该会有不少读者坚持到这里,可能主要是想看看我究竟在卖什么关子,GDB 底层原理不就是通过诸如 ptrace 系统调用来控制、甚至改变进程的运行,同时获取我们需要的变量或者调用栈信息嘛。我其实想在这里表达的观点是,GDB 的核心是把冷冰冰的机器状态映射回我们熟悉的源码世界,所以 GDB 真正实现核心是 DWARF,也就是大家平时经常听闻的调试信息,而不是 ptrace,后者只是 GDB 控制进程以及获取甚至修改进程里面内存数据的一种手段。
关于调试信息 DWARF
我在刚学编程的时候,其实就和绝大部分人一样知道了调试信息的存在,但我实际上并没有很好的理解什么是调试信息,对调试信息最主要的认知非常局限,只有以下两点:
- 我可以通过
readelf -S {}去查看可执行文件或者动态库里面信息构造,debug_ 开头的那一大堆不知道干什么的 section 就是调试信息- 想使用 GDB 调试器用的舒服,那么我们必须要有这些调试信息,换句话说得使用 Debug 版本二进制,所以编译时候记得加 -g 选项
除此之外,我对于关于 DWARF 是怎么生成的,DWARF 是跨平台的吗,GDB 是怎么使用 DWARF 的,这些核心概念一无所知。这些知识的缺乏,也注定让我很难最大程度的发挥 GDB 的能力。打个比方,如果调试信息缺失,那我还可以用 GDB 获取到哪些有用的信息,类似的问题,可以瞬间难倒当时的我。
而我最早真正意识到 DWARF 的存在,是我当年在线观看了这个 OpenResty 技术分享,里面的一句精灵和矮人瞬间点醒了我。虽然不知道是当年哪位大佬玩梗,但是 DWARF 矮人能够和 ELF 精灵坐一桌吃饭,这让我对 DWARF 开始真正感兴趣起来。要知道 ELF 毕竟是 Linux 下文件信息内容的组织格式,不说编译器、链接器以及装载器都围绕这个标准工作,光是这里面延伸出来的面试题,也让我们这些打工人不得不慎重对待和认真理解这里面的技术细节 😴。这句话,我只是开玩笑,我更愿意相信,底层细节的理解对我们工程能力甚至是品味的提升有着至关重要的影响。
源码 -> 可执行文件 -> 进程
正常来说,我应该开始介绍 DWARF 的技术细节,以及 DWARF 是如何发挥作用的了,但是我想在这之前,还是掰扯一些可能大家已经耳熟能详的东西,考虑到 AI 输出的会比我说的又详细又好,那我就快速直奔重点:
刚才已经提到了,GDB 或者说调试器的作用,都是将进程某一刻的运行状态映射回源码世界。更进一步的说,调试器的诸多能力,比如说符号查找,变量查看以及调用栈回溯,都是仰仗 DWARF 来完成的。所以,我们需要了解这里面源码到可执行文件再到进程运行时的转换细节,才能更好的理解 DWARF 是如何保留这些信息的,以及保留了哪些信息。
源码 -> 可执行文件
想必大家都听过 C 语言编译的过程:预处理、编译、汇编和链接,也都听过 JAVA 是一次编译,到处运行。而这里,我想展示一张来自 《Crafting Interpreters》中的图片,基本上每个语言都可以在这张图片里面找到对应的路径,而我每次遇到各种编译相关的问题时,自己脑海中首先会浮现出这张图。
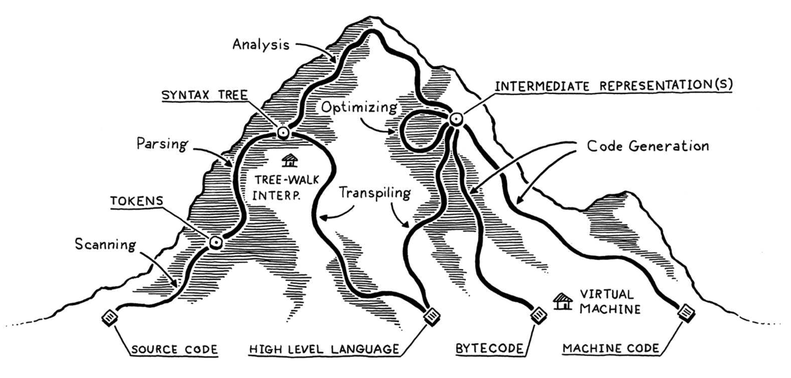
结合着 -g 编译选项可以生成调试信息,并且 ELF 格式中包含着 DWARF 相关的 section,所以 DWARF 是编译器在编译过程中生成的。并且我们可以进一步理解,不管是什么样的编译型编程语言,最终在这个过程中,source code 都会被转换为 machine code。这意味着源码中大量的信息会被剥离优化掉,所以 DWARF 是怎么帮助 GDB 把机器码映射回源码的答案在这里变得会稍微清晰一些:这些被剥离的信息以 DWARF 的形式被编译器记录了下来。
另外,可能大家还会有疑问的是,GDB 还能支持 C/C++ 以外编译型编程语言的调试吗,更蛋疼的一点的问题,GDB 还能支持 Lua 或者 Python 这种脚本型语言的调试吗,这些问题,都会在后面进行讨论。
可执行文件 -> 进程
我们都知道在 Linux 上面,可执行文件是被 execve 系统调用启动的,而这里面涉及到操作系统里面加载器和运行时动态链接器大量工作。《Loader & Linker》和《程序员的自我修养:链接,装载和库》这些书中已经描述了大量细节,我这里就不再赘述(大家可能会注意到后者也是这篇博客主标题的由来,向这本书致敬)。
《程序员的自我修养:链接,装载和库》这本书里面有一句话让我印象深刻,大概意思是:了不起的程序员能够理解自己编写的可执行文件中的每一个字节。我以前就笑一笑,把这句话当做鸡汤一口干掉,但是现在在 AI 时代,这个难度已经降低了很多,很多时候只是看我们有没有这个需求罢了。
下面这张图就是可执行文件或者动态库被编译生成之后,之前提到的 DWARF 信息存放的位置,红框里面 debug 开头的几个 section。这里,我想先说明一个可能的错误认知,也就是符号表和调试信息的区别。一般来说,.symtab 就是我们日常说的符号表,这个表项是否存在,一般是看可执行文件或者动态库有没有暴露出的全局符号甚至是局部符号,但这个符号表和调试信息是两回事。最大的区别在于,符号表携带的信息量比调试信息少得多,因为符号表只是为了链接和重定向使用,而调试信息则是为了运行时的源码级别还原。
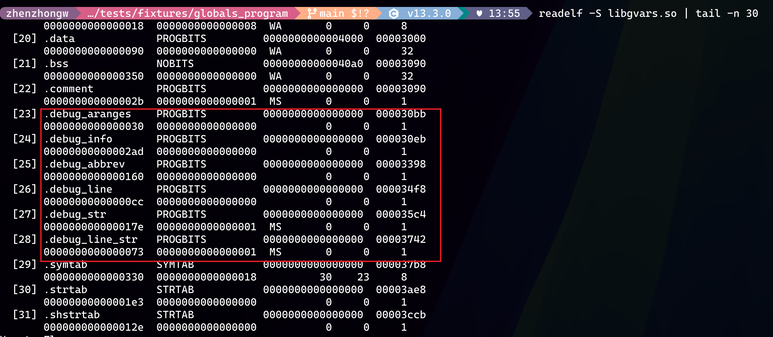
接着,在说可执行文件如何被映射到进程之前,我想重点说一下,两个比较重要的概念,也是每次大家使用 readelf -S {binary} 命令去查看 section 细节的时候,经常会看到的两个属性,分别是下图中的 Address 和 Offset。首先是 Offset 属性,这个很好理解,就是 section 在文件中的真实偏移,毕竟这些 section 都是真实的二进制数据(当然除了 .bss 这种),所以肯定是存放在可执行文件内容里面的。接着就是 Address 属性,这个其实指的是 section 会被加载的虚拟地址,所以有的时候会被直接叫做 VMA(Virtual Memory Address)。当然大家第一时间会反应出来,平时我们进程里面指针都是非常大的数字,为什么这里 Address 这么小。
这个问题其实也很好解释,因为可执行文件还没有被加载到真实的进程虚拟地址空间中去,所以在可执行文件里面记录的 Address 只能是相对偏移,我们可以叫它是 Link-time Address,而我们平时调试和打印的指针地址数值是 Runtime Address,因为加载器会重新申请虚拟地址,再把可执行文件中的数据映射到进程对应的虚拟地址空间上。所以它们的关系是:Runtime Address = 基地址(Load-Base) + Link-time Address。当然,这里要求可执行文件必须是 PIE 类型的(一般来说 Linux 大部分发行版默认都会启用 PIE),如果是非 PIE 类型,那就都不需要基地址来换算了。至于基地址怎么获取到,一般来说的话,调试器都是从 /proc/<pid>/maps 获取到可执行文件或者动态库被加载的基地址的,当然还有一些其他的方式,这里就不再赘述(LLM 可以轻松回答这些问题😉)。
顺嘴提一句,有人说,自己每次启动进程,看到的一些固定全局变量的指针地址都是不一样的,这里得感谢 Linux 中的 ALSR(Address Space Layout Randomization) 安全机制,每次进程的基地址都是随机的。为了调试方便,我们可以考虑在我们的测试机上关闭 ALSR 功能,正所谓做大事者不拘小节。
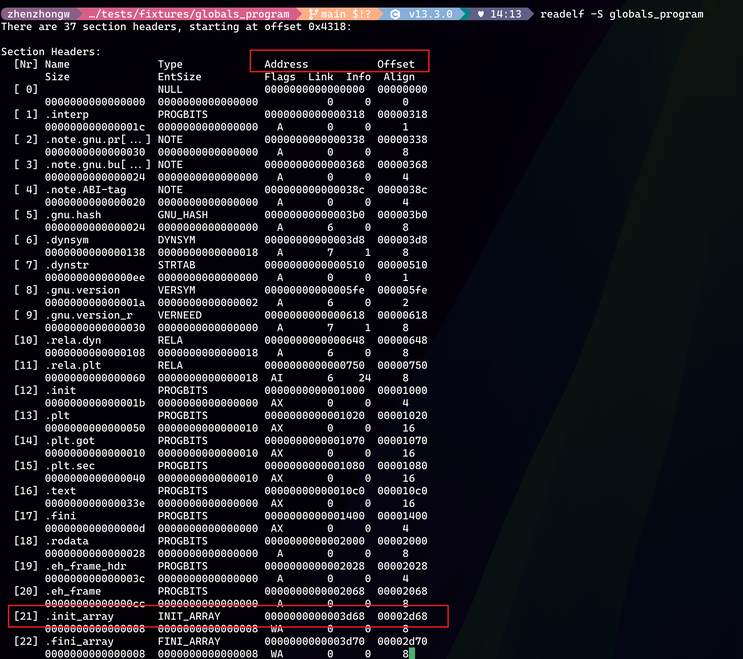
另外,这里还有一个问题:很多时候,大部分 section 的 Address 和 Offset 是一致的,但是也有的时候会不一致,比如上面图片中的第二个红框,.init_array 对应的 Address 和 Offset 就是不一致的,这是为什么。我可以理解 .bss 之后的 section 对应的 Address 和 Offset 肯定是不一致的,考虑到 .bss 是节约了可执行文件的大小,但是在被加载的时候,肯定是要把对应的变量长度给算在虚拟地址空间的(也许这就是经常看到 .bss 被安排 section 中的最后一个,我瞎猜的)。但 .init_array 的 Address 和 Offset 为什么不一致呢。
下图中是 readelf -l 这个命令的输出,我觉得可以帮助我们更好的理解这个问题,红框里面 LOAD 对应的就是 ELF 文件格式中要被加载的各种 section。第四个 LOAD VirtAddr 也就是 Link-time Address 正好也是 .init_array 的 Address 0x3d68,所以我们关注的 .init_array 是位于第四个 LOAD 中,这个 LOAD 的权限是 RW 可读可写,而前一个 LOAD 是 R 仅可读。这些 LOAD 实际是会被加载到 Loader 使用 mmap 来创建的虚拟地址空间,而 mmap 是创建的空间是页对齐,并且想要不同的权限,那么必须多次调用 mmap。所以,.init_array 的 Address 顺理成章的偏移了一页,方便 mmap 来创建新的地址。
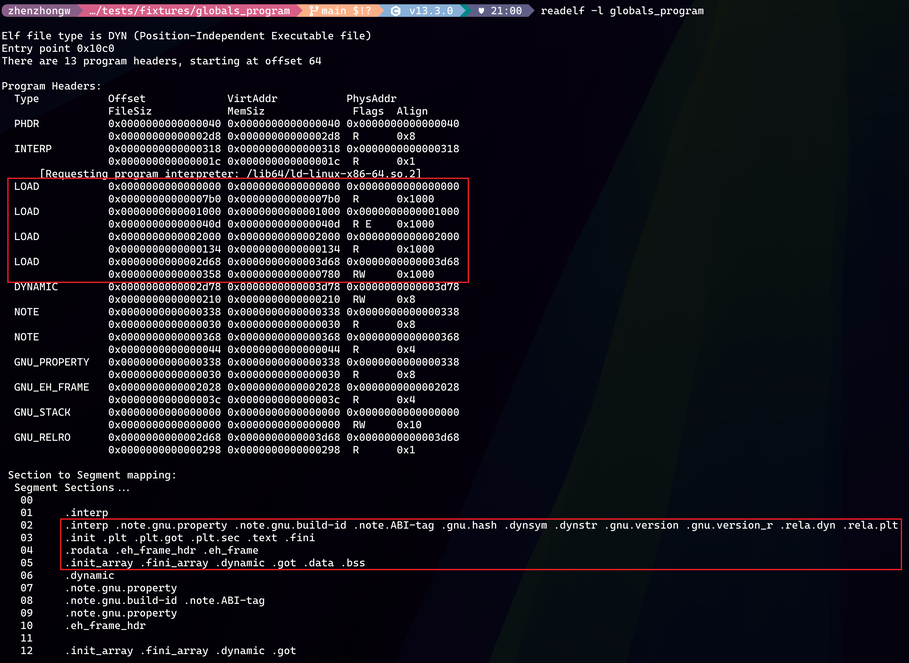
但是,有人会说,为什么不直接偏移到下一页 0x3000 的开始,而非要把 .init_array 的 Address 算成 0x3d68 呢。我觉得这也是一个有趣的问题,这是因为 ELF 装载时通常用 mmap 做 file-backed 映射。由于页表映射是以虚拟页为单位建立的,每个虚拟页对应文件中的某个页(offset 向下对齐),并且页内偏移必须保持一致:这意味着,文件页内第 k 个字节只能映射到虚拟页内第 k 个字节,无法把文件页内偏移 0xd68 的字节“挪到”虚拟页内偏移 0 起点。 因此必须满足 Address % page_size == Offset % page_size,这样段起点 Address 才能精确对应文件偏移 Offset。至于 Address 0x3000 到 0x3d68 这段会不会浪费掉,要知道这是虚拟地址,其实无关紧要,反正又不会浪费物理内存。
最后,想补充一点,就是怎么验证我上面说的内容是否准确,感兴趣的可以让 AI 带着走一遍,让 AI 生成一个测试程序,然后程序运行起来之后,用 xxd 这样的命令查看可执行文件的内容,再用 gdb 去看正在运行的进程虚拟地址空间对应的地址内容,看看两边数据内容是否一致,是否按照这样的方式被正确的加载。这也是我上面提及的以术证道,即动手实践来验证自己对理论的理解,特别是能找到一些自己理解有误差或者不够深入的地方,而 AI 也大大降低了这个过程的成本。
一些问题的答案水落石出
-
DWARF 是不会影响程序运行,因为我们可以看到 DWARF 相关的 section 只有
Offset的数值,对应Address数值都是 0,这意味着 DWARF 相关的 section 都不会被真正加载,自然不会影响进程运行。 -
更进一步,我们可以比较清晰的理解广义上 Release 和 Debug 版本的区别,有人可能存在一个误区,会说只有 Debug 版本才能被调试,但其实这是错误的。广义上,Release 和 Debug 版本的区别,只是一些编译选项的不同,比如 Release 会开一些高优化,可能不会使用 -g 编译选项来生成 DWARF,又或者可能会把符号表和调试信息 DWARF 给 strip 掉。这并不代表 Release 版本不支持调试信息或者说无法调试。当然,更具体 Release 和 Debug 版本的差异,还是得看实际项目的情况,很多项目可能会通过一些宏来控制 Release 和 Debug 版本的行为,这种就不展开讨论了。
-
addr2line工具的原理已经揭开了一半,这个工具其实就是根据 DWARF 信息来将指令的地址转换成源码的。考虑到addr2line都是对着可执行文件使用的,所以这里的指令地址必然是Link-time Address而不是Runtime Address,注意也不是指令在对应文件的file offset,虽然很多时候这两者是一样的,感兴趣的可以跑一下非 PIE 程序,可以明显看出区别。 -
很多时候,大家遇到进程 crash,都喜欢去看看系统命令 dmesg 的输出,经常能看到如下的输出:
a.out[4101063]: segfault at e9 ip 00005b76a99ad13d sp 00007ffef3417330 error 6 in a.out[5b76a99ad000+1000] likely on CPU 0 (core 0, socket 0)。这里 ip 和 sp 分别是指令寄存器和栈顶寄存器,考虑到进程已经异常结束,如果没有 Coredump 文件,我们完全不知道 a.out 可执行文件在这个进程虚拟地址空间的基地址,那么指令寄存器的数值0x00005b76a99ad13d只是一个Runtime Address,对我们分析问题没有太多帮助。这个时候,我们可以看最后a.out[5b76a99ad000+1000]这里的信息,对应内核代码在这里,是打印了对应指令寄存器所在的 VMA 的起始虚拟地址和长度。但这里需要注意,简单的将指令寄存器减去其 VMA 起始地址,还是得不到我们需要的Link-time Address,因为我们需要基地址。这里有一个窍门:就是从对应的可执行文件里面,根据readelf -l的输出,也就是 program headers 之间的偏移,来算出第一个 LOAD 的 program headers 是多少,也就是我们的基地址。毕竟其中一个 LOAD 的Runtime Address已经知道了,那么其他 LOAD program headers 的也很容易算出来。当拿到Link-time Address,剩下就是通过 addr2line 去获取指令对应的源码行号,或者直接 objdump 直接查看对应指令的汇编,都是看我们具体需求了。 -
为什么这里要花这么笔墨描述可执行文件加载到进程中地址转换的这些细节,因为这些工作也是调试器自己需要做的,如果我们比较清楚的知道地址是如何转换的,我们需要哪些信息才能确定这些地址,我们才能更好的使用调试器,也为下面讨论 ptrace 做好了铺垫。特别是在某些场景下,信息有缺失的时候,调试器开始“罢工”,清楚这些细节,才能确认我们在受限的情况下,能拿到多少靠谱的信息,这些对我们解决问题至关重要。哦对了,这里没有去提及运行时的动态链接,以及 plt got 这些概念,我觉得对于调试器来说是不太需要关心的,大家如果感兴趣的,可以看上面提及的两本书。
GDB 依赖的后端能力
什么是 GDB 的后端能力,这倒不是我们熟悉的 Web 开发那种前后端概念,其实这个划分,我是从这篇博客 Linux tracing systems & how they fit together 学来的,博客里面将动态追踪技术划分成前端、数据源和后端三部分,我觉得非常有层次。而 GDB 作为调试器,虽然相比其他动态追踪技术 (eBPF,Systemtap) 这些有着很大的差异,但是好歹也算是动态追踪技术的一员。那 GDB 依赖的底层能力,在 Linux 平台上,即是上文提到的 ptrace ,这里也可以更进一步,用以下三点更具体的描述 ptrace 的核心能力:
- 提供了对被追踪进程进行拦截关键事件能力,比如说系统调用,信号
- 暂停执行和恢复执行以及要求被追踪进程单指令执行的能力
- 暂停被追踪进程之后,可以读写其寄存器和内存的能力
所以,我们平时熟悉的 GDB 打断点,其实就是依赖了上面提及的 ptrace 能力 2 和 能力 3,让我们跟踪的进程暂停在某一个指令,然后对于这个进程来说,它的世界就相当于被暂停住了,这个时候 GDB 根据使用者的命令,去读取关键信息进行展示。这里,我觉得还需要简单说一下,暂停执行大概是怎么回事,这其实是内核提供的能力,GDB 利用 ptrace 去修改想要打断点的指令,把指令第一个字节改成 Trap 指令(x64 上面是 int3),然后 CPU 执行到这个指令的时候,会产生异常,然后内核负责使用 SIGTRAP 信号来通知 GDB。
这个方式有点让人熟悉,我们都知道系统调用也是特定的机器指令来进行用户态到内核态切换的,那 GDB 是怎么实现监控系统调用的呢,会不会有冲突。这里实现其实是依赖内核在执行系统调用的通用路径里面做通知,而不是直接去修改被监控进程的系统调用代码指令,也就是上面 ptrace 能力 1。大家平时熟悉的 strace 也正是这样基于 ptrace 的基础上实现的。
接下来又有新的问题:ptrace 指令修改是什么层面的,会影响这个二进制的其他进程吗?首先 ptrace 需要的指令地址是我们上文一直在提及的 Runtime Address(即该进程的用户态虚拟地址),而这个写入,指的是内核会通过这个进程的 mm_struct 去找到该地址所在的 VMA,然后再进行指令修改。这里,由于我们都知道多线程是共享同一个虚拟地址空间的,所以这个指令修改会影响这个进程中所有线程。对于可执行文件/共享库的 .text 映射,通常是 MAP_PRIVATE 的 file-backed 页面,因此写入会触发 copy-on-write:只在当前进程内复制出私有页并更新页表映射,既不会修改磁盘上的二进制文件,也通常不会影响加载同一文件的其他进程。哦对了,我们都知道 .text section 被加载的时候是不可写的,但是要知道 ptrace 写入是在内核态生效的,这里不可写防的是用户态,所以也没有问题。
简单聊完 ptrace 这个大家耳熟能详的 GDB 的后端能力之后,我想趁热打铁再聊一聊 GDB watch 命令的实现细节。首先,GDB watch 是一个非常好用的命令,可以监控一段内存地址是否发生了读写操作,相当于给了我们一个区别于 ptrace(断点、信号或者系统调用)之外的新的触发事件。
我其实一开始接触到 watch 的时候,我很好奇是怎么实现的,如果基于 ptrace 的话,那只能依赖 ptrace 的单步指令执行的能力,比如说执行一个指令,检查下内存有没有被改动,但是这个性能肯定是逆天的差。后来,我研究了下资料,发现 GDB watch 实现依赖的是 CPU 硬件能力,当 GDB 注册了对某块内存的读或写监控,CPU 在执行指令的时候,会关注这块内存是否满足监控条件。某种意义上,GDB watch 实现核心并不依赖 ptrace,所以也算是 GDB 新的一种后端能力。
在这一小节最后,我想举个例子,来介绍下 watch 的妙用。GCC 编译器支持 -fstack-protector 编译选项,作用的话是可以看到有没有代码逻辑导致越界写破坏了函数栈。大概原理是在函数序言的时候,在栈上存放一个随机数,紧挨着 RBP 和返回地址。如果函数局部变量发生了越界写,又因为栈是高地址向低地址增长的,所以有比较大的概率会破坏这个随机数。这样就可以直接报错,把问题给直接暴露出来,而不是等哪一天暴雷。
至于 watch 怎么使用,其实就是在函数序言位置打上断点,触发之后,先 disassemble 看一下函数序言对应的汇编,确认随机数也就是金丝雀在栈上的位置,然后核心操作就是直接 watch 这个内存地址,然后让程序恢复执行,等待好消息即可(看看究竟是谁破坏了金丝雀值)。有人可能会问,问题都在同一个函数里面,难道还肉眼看不出到底是谁破坏了栈?但如果这个函数本身足够复杂或者里面调用了其他复杂的逻辑呢。又或者说,我有百分百抓住问题的方法,为什么还需要看代码呢,watch 一下多简单(当然这里不考虑 watch 的性能问题)。
调试信息 DWARF
关于那么多 debug_ 开头 section,如果直接问 AI,AI 可以给每个 section 的作用都来一段很好的解释,但我想通过 GDB 怎么使用 DWARF 信息实现自己的核心功能,来把这些 section 给串起来,更好的说明这些 section 的用途。
断点打在哪里
我们已经知道了 ptrace 的基本原理,那我们接着来看看 GDB 在一开始利用 ptrace 打断点的时候,还需要做哪些事情。首先,断点的形式一般是函数名或者源码文件名称和行号,而我们知道 ptrace 其实是最后对着 Runtime Address 来修改指令的,所以 GDB 第一件要做的事情就是把函数名称或者源码行号转换成 Runtime Address,当然了使用者也可以自己算,然后直接用 GDB 对着地址直接打断点,比如说 break *0x00005555555553cd,把断点打在这个地址对应的机器指令上面。
好了,GDB 是怎么找到源码对应的 Runtime Address 的呢,这里的答案简单又不简单,DWARF 中的 debug_line section 里面维护了源码行号和机器指令地址的映射关系(也就是官方所说的 Line Number Information),所以调试器只需要去查询 Line Number Information 就可以了。有人可能会说,自己没有调试信息,还是可以用 GDB 去断住函数,那是因为这个函数在可执行文件的符号表中 .symtab 可以查询到,但想享受源码文件行号级别的断点,我们依然需要调试信息。
但是 debug_line section 是如何记录这个映射关系的,值得说一说,如果我们只是通过 readelf --debug-dump=decodedline {debuginfo-file} 去查看 Line Number Information,那结果都是被 readelf 解析完毕处理好的,没什么意思。所以,我们继续研究 Line Number Information 信息是如何被管理存储的,这里 DWARF 没有选择简单的映射表来存储,而是设计了一套高效的状态机指令来记录这些信息,最直接的原因就是在复杂的程序中 Line Number Information 信息量会非常多,DWARF 必须实现高效的压缩,才能确保调试信息大小不爆炸。DWARF 考虑到机器码的指令地址正常都是连续增长的,所以源码行号也是随之顺序递增,所以这里的状态机在一开始记录了源码文件和行号以及对应指令地址之后,后续记录都是只记录偏移,比如说行号增加了多少,指令增加了多少,这样可以最大限度的复用重复的信息,确保记录的高效。
另外我们可以关注一下 Line Number Information 中记录的信息,首先需要注意的是这里面记录的指令地址,正是我们上面扯了好久的东西,机器指令在可执行文件中的 Address,而不是 Offset。所以,在我们查询到了源码行号对应的 Address 之后,我们还需要将其换算成进程中的 Runtime address。
而 Line Number Information 中还存在一些比较有意思的信息,比如说除了行号之外,还保留了列号。因为不管是有人写代码的不够讲究,多条程序代码都放在同一行,还是说使用了函数调用链,列号都能帮我们更精准的定位到指令是对应源码的哪个位置。还有一个比较有意思的信息是 is_stmt,代表着这个指令是不是这一行源码的逻辑起点。因为我们知道,正常来说一行高级语言的源代码可能会对应多条指令,比如说 a = b + 3 这行伪代码,编译器可能会生成多条指令:加载 b 的数值到寄存器,执行加法,把结果存入 a 的位置。如果我们只是随意的把断点打在某一条指令上,用户肯定会疑惑,因为这条指令可能是源码执行的中间态,用户去查看具体变量内容时候,会和预期的不符合。另外编译器如果开了高优化选项,搞些指令重拍这种正经人很难理解的操作,那么如果没有 is_stmt 标志,真的很难断到合理的位置,会影响调试器的效果。
哦,对了,像 GDB 的 step 命令也是非常依赖 is_stmt 标志,毕竟 ptrace 只是提供了指令级别的单步执行能力,而 GDB step 则是提供了源码级别的单步执行,所以 GDB 得非常小心的判断,一次 step 究竟要执行几条指令。另外 GDB 也不能直接简单粗暴的把这行源码行号对应的指令都执行完,毕竟一行源码可能有多个源码语句,哪怕没人会这么写,也有可能出现经典的 for 循环语句,类似这种 for (int i = 0; i < 100; i++),相信调试的时候,大家肯定不希望一个 step 命令就导致这句代码完全执行了😁。
最后,我们还剩下一个问题,就是如果使用了状态机来保存 Line Number Information,那么有什么办法,可以快速查询定位我关注的源码行号对应的地址呢。毕竟线性存储的数据,查询的时间复杂度得是 O(n),而我们肯定想要的是 O(1) 的查询效率。难道我们只能自己维护一个查询表,把所有的 Line Number Information 内容都解析完毕,然后再开始查询。这个操作无疑是有一些浪费的,特别是大部分使用场景下,断点可能只是零星的几处,有点得不偿失。
DWARF 给的解法也很简单,根据文件名称在 .debug_names section 中快速查询到对应的 Compile Unit 的位置,然后去从 Compile Unit 里面对应的 DW_AT_stmt_list 属性中,找到这个 Compile Unit 对应 Line Number Information 在 debug_line section 中的偏移,然后单独解析这个 Compile Unit 对应的行号表,就可以快速查询到对应的地址了。嗯,这里又得引入几个概念,编译单元(Compile Unit) 是 DWARF 中最高层的结构,一般存放在 debug_info 这个 section 里面,更具体的说,C/C++ 语言中,一个源码 c 或者 cpp 源码文件就对应一个编译单元。而 .debug_names 是帮助我们快速查找到对应的编译单元在 debug_info section 中的偏移。
讲到这里,相信上面提及的 addr2line 工具相关的使用原理中剩下的拼图也被我们找到了,addr2line 拿到 Address 之后,根据类似于 .debug_names 的 section .debug_aranges 去快速定位编译单元在 debug_info section 中什么位置,然后找到 debug_line section 中对应的行号指令偏移,开始解析,获取出该指令对应的源码文件和行号。
变量在哪里
现在我们要面对 GDB 需要解决的第二个问题,那就是断点被触发之后,在那一瞬间,被打断点的那行源码所对应的可见的变量和参数都在进程虚拟地址的哪些位置上面,只有知道这些变量的地址,GDB 才能用 ptrace 去把地址对应的数据给读出来,又或者去按照用户的意愿来改写它。当然,我们知道,这里的关键,还是 DWARF,DWARF 就像是地图,在黑暗中指引着我们前进的道路。
有人会说 bpftrace 也可以看参数内容,提供了 arg0 到 argN 的变量来方便追踪,也不需要可执行文件有调试信息啊,比如下面这行脚本,就可以轻松捕捉 bash 在执行到 readline 函数入口的第一个参数内容。
sudo bpftrace -e 'uprobe:/bin/bash:readline { printf("readline called, arg0: %s\n", str(arg0)); }'
bpftrace 能够做到这些,其实得感谢 ABI (Application Binary Interface) ,这里面规定了各个平台的 Calling Convention,不管是系统调用还是普通的函数调用,函数入口的参数存放都是遵循一定的规则,比如在 AMD64 平台上,函数调用的第一个参数一定是放在 RDI 寄存器上。然后函数的地址也可以通过符号表查询到,那么确实可以在没有调试信息的情况下,通过 bpftrace 去捕获这样的参数内容,你用 GDB 也一样可以做到。
但这些只是最简单的调试追踪使用场景,如果 GDB 需要断在源码的某一行,而不是函数入口呢,并且是想看某个局部变量的内容,而不是全局变量或者参数呢。并且我们知道随着代码的执行,函数执行一半的时候,参数很大可能已经不再遵循原来的 Calling Convention 约定,还傻傻的呆在某个特定的寄存器里面了。而在这个时候,我们就需要调试信息出场救驾了。
DWARF 做了什么,一句话概括的话就是:记录了每个指令被执行时,所有变量和参数所处的内存位置信息。我们都知道,这里需要被记录的信息量多的吓人,老老实实的一一记录肯定是不行的,那么 DWARF 的解法是什么呢。DWARF 的选择很酷,直接设计了一个基于栈的微型虚拟机语言,用这个虚拟机语言来描述某个变量在特定的指令范围内对应的具体地址位置,极大的节约了空间。当然这也增加了调试器的解析负担,不过我觉得是值得的,毕竟 DWARF 解析并不是一个高频操作,调试的时候需要看的信息其实是有限的。
至于具体怎么做的,我们又要引入一些概念,首先我们需要再次认识 .debug_info section,这也是 DWARF 中最核心的 section,里面基本是一个树状结构,每个树节点或者说基本单位是 DIE(Debugging Information Entry),刚才我们提到过编译单元也算是一个 DIE(类型是 DW_TAG_compile_unit),代表某个源码文件,那源码文件里面定义的函数,也算是编译单元下面的一个子节点,而函数对应的参数和局部变量,就是对应的孙子节点,正如下图(dwarfdump 工具直接解析出的 DWARF 输出)所示,calculate_something 函数和对应变量都被记录在 debug_info 中。
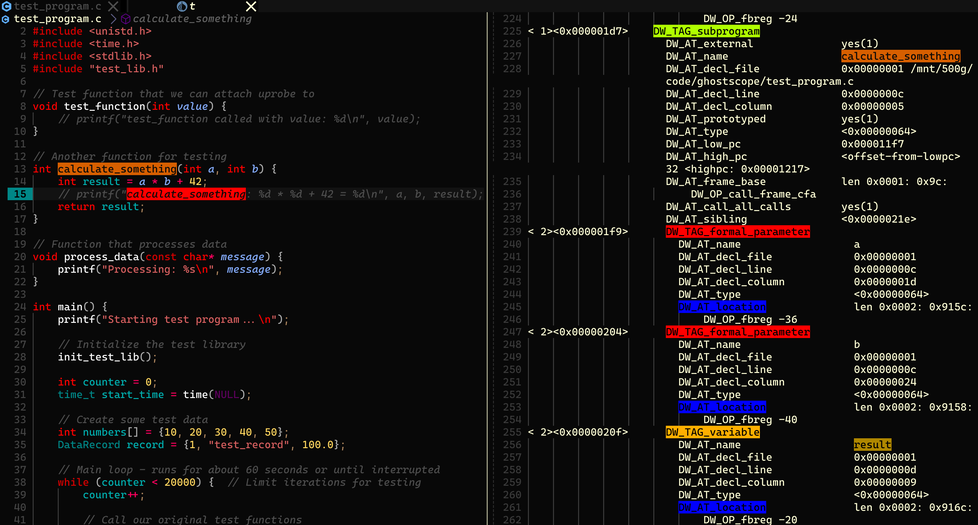
当我们根据函数名称快速找到在编译单元中的对应函数的 DIE 节点,其类型也就是 DW_TAG_subprogram,该函数有对应的 pc 范围,也就是指令地址的范围。然后,每个变量对应的 DIE 节点里面,清晰的记录着变量的名称,以及最关键的信息 DW_AT_location,用来描述变量的位置。由于 calculate_something 函数比较简单,所以 result 变量的描述是 DW_OP_fbreg -20,也就是虚拟机语言字节码,在栈帧基址(frame base)减去 20 的位置,也就是 result 变量的数值在这个函数中,一直被存放在栈上。至于栈帧基址是多少,大家会说直接看一下当前的 RBP 寄存器就知道了,当然,这么做的前提是 RBP 寄存器没有被编译器优化掉,如果 RBP 寄存器被优化了,我们怎么获得栈帧基址呢,这个问题,会在下面栈回溯的小节中进行简单的讨论。
再看所谓 Release 版本或者更准确的说,开了编译器高优化选项的情况,因为这才是比较复杂的情况。也是很多人疑惑的地方,DWARF 在高优化选项下,还能提供源码级别的地图能力吗?答案是肯定的。从图中,我们可以看到这时候,result 变量对应的 location 一共有三段字节码,分别对应三段不同的指令地址范围。DW_OP_breg5 RDI+0, DW_OP_breg4 RSI+0, DW_OP_mul, DW_OP_plus_uconst 0x2a, DW_OP_stack_value 这段字节码很清晰描述了 result 实际上没有存放在任何虚拟地址上面,而是可以通过 result = $RDI * $RSI + 42 这个计算公式来计算出来,也就是源码里面的 result = a * b + 42。第二段虚拟机字节码则有一点点小改动,RDI 对应的指令从 DW_OP_breg5 换成了 DW_OP_entry_value(DW_OP_reg5 RDI),这也是蛮有意思的,因为在这个指令范围,RDI 寄存器被破坏了,我们可以从下图左边的汇编中看到原因。imul %esi,%edi 指令会导致 RDI 寄存器被修改,所以 DW_OP_entry_value(DW_OP_reg5 RDI) 代表的是函数起始位置,或者说函数序言阶段,RDI 对应的数值。当然,对于 GDB 来说,想找到那一刻的数值有点困难,特别是高优化的情况下,这些变量甚至都没有被放到栈上。
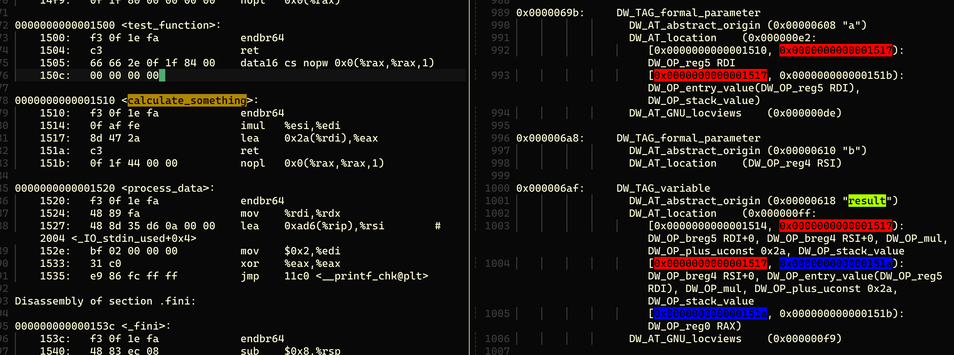
这也是为什么高优化的情况下,很多变量在 GDB 里面都是 optimized out,这是因为编译器直接把变量给优化掉了,那调试信息里面自然不会有相关位置记录,毕竟你不能记录一个不存在的东西,或者跟上面这个例子一样,RDI 寄存器被覆盖,DWARF 字节码提示我们使用入口时候的数值,但是我们已经找不回那个数值了。至于为什么这个没有影响,因为只有没有用的东西才会被优化(这句话读起来好奇怪,也许有一天我也会被优化掉🤡)。换个友善一点的说法,如果被优化,不一定是没有用,更说明是存在替代品的,所以我们可以从替代品身上找到想看的信息。
那么如果是静态变量或者全局变量呢,其实也是大同小异,因为这些变量都不是在栈上,或者寄存器里面,而是在 .data 或者 .bss 这些 section 里面,换个说法,这些变量的生命周期是全局的。所以查找这些变量地址的难度会大大降低,至少很少会用上面那么复杂的虚拟机语言来描述。一般来说,我们通过符号表或者 .debug_info 里面记录的地址偏移,就能够轻松找到这些变量地址,再按照上文说的进行基地址转换,就能定位到进程的虚拟地址位置。如果还想讨论 TLS 这种特殊变量,我已经有点疲惫了,就先装作它不存在吧。
内存布局
当我们找到了想查看变量的地址,还有一个问题需要我们去解决:如果变量不是 int,char 这样的基础类型,而是一个编程语言自定义的复杂结构体呢,我们怎么知道到底有哪些成员变量,成员变量的类型是什么,更甚至是这些成员变量的具体内存布局是什么。如果不知道这些信息,那么我们哪怕有了地址,也无法把变量源码级别的含义原汁原味的呈现出来。
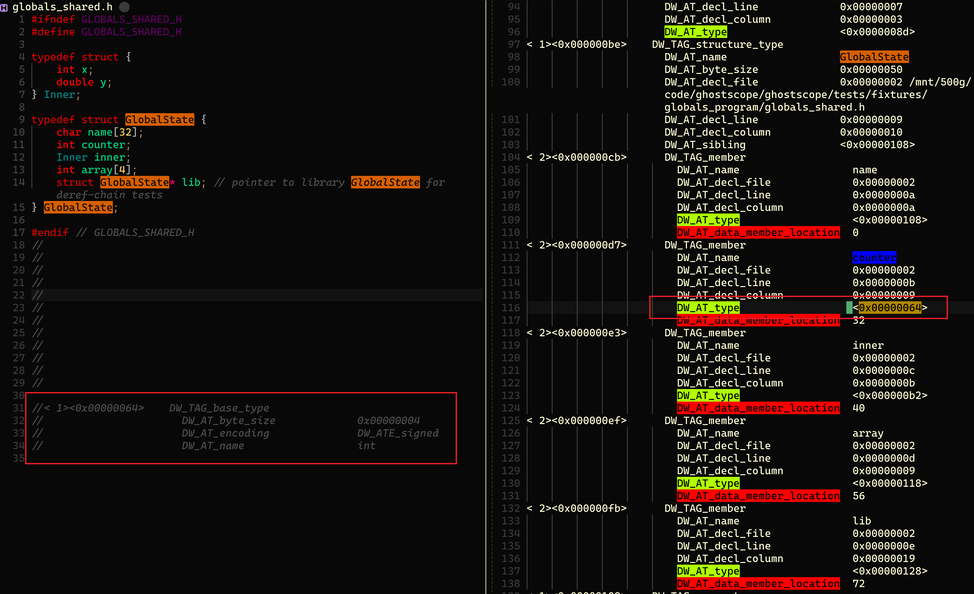
其实变量类型的内存布局依然是存放在 .debug_info section 里面的,由 DIE 中的属性来表示。如图所示,DW_TAG_structure_type 代表着自定义的数据结构,DIE 类型是 DW_TAG_member 的则是里面的成员变量,DW_AT_data_member_location 属性指的是该成员变量在数据结构中的偏移位置。而 DW_AT_type 属性则更关键,表达的是成员变量的类型在 DWARF 中的位置,图中左边红框位置是按图索骥把第一个成员变量 counter 对应的类型信息的内容。可以清晰看出 counter 成员变量对应是一个四字节大小的有符号数。按照这个思路,所有变量我们都可以根据 DWARF 里面的内存布局描述,把变量的实际内容精准的展示出来。
有了这样内存布局的概念认知,指针的定义变得清晰起来。即便在调试信息缺失的情况下,我们也可以凭借对数据结构内存对齐和偏移量的底层直觉,完全可以手动对指针进行强制类型转换,在 GDB 的帮助下看到我们想看到的变量内容。
栈回溯
还有一件非常重要的事情,就是调用栈回溯,毕竟很多时候,排查问题的时候,看看调用栈,就八九不离十了,而且大家喜欢看的火焰图其实也是基于调用栈。不过栈回溯其实是一件非常复杂的事情,我这篇博客完全没有讨论这些的意愿,相反,我想在这里推荐几篇我读过的博客,在这些博客里面,栈回溯被讲解的非常清晰,虽然我还有不少细节还没有理解到位。
The Return of the Frame Pointers 这篇大佬写的博客介绍了最通用也是最方便的栈回溯方式,即借助栈指针进行栈回溯,并且回顾了当初编译器为了性能优化而停止生成栈指针的来龙去脉,同时还展望了未来
Unwinding the stack the hard way 介绍了除了使用栈指针进行栈回溯之外,我们还可以依赖
.eh_framesection 来进行栈回溯,里面描述了大量实现细节。顺嘴提一句,这个 section 里面核心数据call frame information还是 DWARF。所以这里介绍的技术本质上还是如何基于 DWARF 来进行栈回溯。DWARF-based Stack Walking Using eBPF 这篇博客依然是聚焦在如何基于 DWARF 来进行栈回溯,但是这次是使用 eBPF 来实现这个技术,考虑到 eBPF 的一些限制,实现起来非常有挑战性。现在 parce 已经把这套技术方案实现了,并且在实现一些虚拟机语言的栈回溯,非常酷炫。
DWARF 多语言支持
现在可以尝试回答之前遗留的一些问题了,首先 GDB 会支持 C/C++ 之外的编译型语言吗,答案是肯定的,不管是 Go 还是 Rust,其实都可以用 GDB 来调试。这是因为 DWARF 在设计上本身就是通用,不拘泥于某种特定的编程语言。更具体的说,DWARF 的设计理念是在描述代码的逻辑结构和内存布局,至于这些数据信息如何被解释,则是全看编程语言自己。
举个简单的例子,比如 32 位有符号数在 C 语言里面是 int,而在 Rust 中的类型则是 i32,而 DWARF 没有死板的将类型写死,它只负责描述这个类型的属性和大小。所以,不管是 C 的 int 还是 Rust 的 i32,最后 DWARF 类型描述只是 4 个字节大小以及类型属性是 DW_ATE_signed。在 DWARF 里面类型属性还有更多,比如说布尔、浮点数以及指针等等,这一切都为 DWARF 多语言支持打下基础。
更进一步,Rust 还有 enum 这样更复杂的类型,这种类型的含义取决于在内存中特定数据的具体数值,这让我想起来 Lua 虚拟机里面对各个类型的实现。而 DWARF 在类型描述设计的时候,已经把这个自由度留给了编程语言自己,提供了 DW_TAG_variant_part 这样的设计,这里就不做展开了。所以,我们知道 GDB 最后会根据每个编程语言的独有语义规范,来去精准还原出对应编程语言的源码级别语义。
那么,我们接着看下一个问题,虚拟机语言调试器方案会使用 DWARF 吗,比如说 JAVA、Python 或者 Lua 这类编程语言。这里答案是否定的,因为 DWARF 更多的是描述机器指令,关注对应内存地址的数据应该对应源码什么信息。而虚拟机语言自成一派,它们的源码级别语义只在虚拟机字节码中有才有意义。最关键的是,虚拟机语言一般都有 GC 和 JIT,这两个都是动态运行时会改变对应内存的源码含义,而 DWARF 记录这些太过于复杂。这还不如调试的时候,直接请求虚拟机的帮助,来对源码语义进行回溯,而不是使用 DWARF 作为地图。
我记得以前我们线上使用的 OpenResty 服务出现了 crash,当时 GDB 进去看了下调用栈,只能看到是 Lua ffi 调用 c 代码的时候发生了 crash,但是这个对问题排查帮助不大。因为我们触发 crash 的业务逻辑在 Lua 代码里面,而 Lua 的调用栈都隐藏在了 Lua 虚拟机里面,GDB 只能看到 Lua 虚拟机的执行调用链。当时线上 crash 非常频繁,我们需要快速确认原因来止血。我当时反手掏出平时用的一个 gdb 脚本 可以直接去查看 Lua 虚拟机实例 Lua_State 的内部状态,把 Lua 调用栈获取到,这样就可以快速知道根因,来进行故障止血了。
DWARF 相关 section 总结分类
随着 GDB 核心功能实现分析完毕,我们现在清楚了绝大部分 DWARF 的作用,我觉得这里可以把这些相关的 section 分成三大类:
- 核心信息存储:比如说上面提及的
debug_line和debug_info这两个 section,另外还有类似于eh_frame的debug_frame存放调用栈回溯信息。- 查询加速:
debug_aranges可以根据Address来快速查找到对应的编译单元在debug_info中的具体位置。又或者是debug_names来根据函数名或者变量名进行类似的快速查找。- 重复信息共享:将各种重复的类型定义,甚至是字符串等等都放在一个池子里面,负责核心信息存储的 section 只需要引用这个池子里面的偏移量即可。
所以我们可以看到 DWARF 其实面临非常多的挑战,最明显的就是需要将繁杂的信息,高效的存储下来,并且方便调试器或者其他工具高效查询使用。DWARF 使用了变长编码压缩,重复信息共享,甚至为了描述复杂的信息而引入了以栈为基础的虚拟机语言。我觉得这些操作,都是我们在工程上在面对一些类似问题,可以拿来借鉴的。另外,GDB 也基于 DWARF 提供加速查询信息设计基础上,又额外做了非常多的索引构建工作,确保在特别复杂的程序上面,也能提供足够好的调试体验。
这篇博客关于 DWARF 的基本介绍就到此结束了。最后来一个免责声明,我对 DWARF 的学习只是浅尝辄止,并不能确保博客里面每个细节都是完全正确的理解,另外还有很多细节内容不仅在这篇博客没有展开,甚至我自己也是一知半解(但是我一点也不慌,毕竟有 AI 和各种源码,只要花时间终归是可以搞清楚的😏)。要知道在晚上刚打完游戏,比较兴奋,很难入睡的时候,我只需要掏出 iPad 看一会 DWARF 官方文档,就会困得不行,立刻想睡觉了。
再次聚焦回 GDB 本身
GDB 的局限
我觉得到这里,GDB 的大部分原理已经比较清晰了,我想再回顾下 GDB 的局限有哪些,毕竟如何用好一个工具,更关键的是知道它的缺点是什么。而 GDB 的局限,我觉得主要有两方面。
很多人会有这样的经验总结,GDB 在一些有异步时序依赖或者并发的场景下会变得比较难用,比如说会影响问题的复现,又或者 GDB 肯定不能拿来对线上服务进行调试(嗯,根据我丰富的犯罪经验,你偷偷对线上服务跑一把 pstack 其实应该没人会发现)。这些其实都是 GDB 依赖的后端能力 ptrace 性能比较差而导致的。最直观的一点使用 ptrace 的时候,调试器是完全暂停被跟踪进程,然后通过信号再通知被跟踪进程恢复执行的,这个就是标准的 stop the world 操作,当然这也不能怪 ptrace,毕竟这是一个调试器,本来就是要停下目标进程,然后进行交互式调试操作的。
那如果,我们效仿 pstack 工具的实现方式,写一段静默的 GDB 脚本,快速执行,获取信息,再恢复执行呢,我们可以对调试器和被调试进程之间的复杂交互视而不见,但是这里还存在一个性能杀手,那就是 ptrace 是如何读取被调试进程的用户态数据的。GDB 得使用 PTRACE_PEEKDATA 来读取目标进程的地址数据,每次只能读取八个字节,这意味着稍微复杂一些的场景,数据一大,就意味着若干次系统调用,以及对应的上下文切换开销。当然,和交互式调试操作相比,本来让人担心的上下文切换开销都变得不值一提了。
如果 GDB 因为 ptrace 的后端能力受限,那么我们能不能换一个后端能力。我其实一直有这样的想法,并且之前尝试实践了一下,在 ghostscope 项目中,我尝试用 eBPF 来替换掉 ptrace,用 DWARF 作为地图来指路,eBPF + uprobe 来去获取数据以及进行展示。当然提升性能的同时,也失去了交互式调试的能力,我觉得有失必有得吧,所谓各有各的使用场景。
另外一方面,DWARF 作为地图,有时候也存在不给力的情况。除了上文提及的高优化编译选项下,某些变量会被优化掉的问题。我还在比较新的 GDB 18.0.50 版本上,遇到内联函数支持不够好的问题,比如说断点没打上,或者没给所有内联函数都打上。换句话说,还是高优化版本下,DWARF 地图相当于粘上了一些墨水,调试体验还是受到了影响。这其实是 DWARF 是为了将机器语言再次映射回我们熟悉的源码世界,但是编译器的优化让这个实现的难度大大提升,这就像是一场拔河,但你都不知道应该站在哪一方,也不知道该期望着谁获胜。
GDB remote 模式
想必大家都听过 GDB remote 模式,通俗点来说,就是如下图所示,我们执行两个 GDB 命令,GDB Server 会跑在被调试进程的环境,然后 GDB Client 在远程机器上提供正常的 GDB 交互能力,双方通过 RSP (Remote Serial Protocol)协议进行交互。不过需要注意的是,大家平时在 vs code 或者 vim 里面使用 GDB 其实严格意义上来说不是 GDB 的 remote 模式,而是在 GDB Client 之上又套娃了一层,加上了 DAP(Debug Adapter Protocol),来确保编辑器只需要为不同的调试工具编写一套操作命令代码。
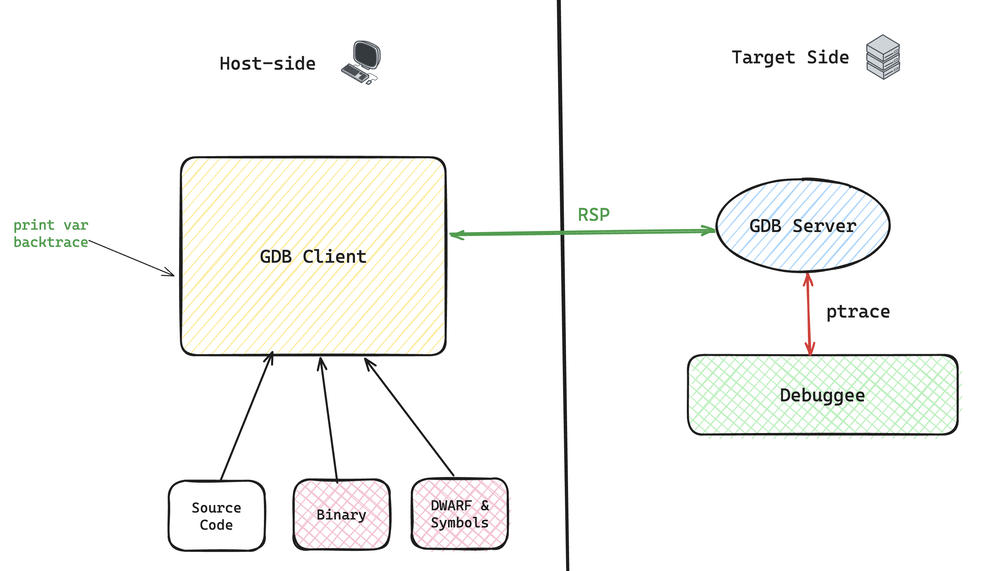
由于我们都已经清楚了 GDB 的基本工作原理,其实这套玩法的原理也就非常简单了。ptrace 是 GDB 的后端能力,让 GDB 可以完全掌控被调试进程的行为,所以哪怕是 remote 模式下,ptrace 还是得在被调试进程的环境执行。但是 DWARF 作为地图,完全不需要搬到目标机器环境,完全可以在远程就对用户输入的 GDB 命令进行分析,确认需要采集或者操作的细节,然后再发给 GDB Server 让它无脑执行。
这么做的好处,我觉得比较明显的就是提升了安全性,毕竟 DWARF 本身描述了大量的源码信息,很多公司肯定不希望 DWARF 随意的泄露出去,所以正常来说发布的公开二进制版本都是被 stripped 的,也就是 DWARF 被剥离了。那么,在客户环境调试的场景下,GDB remote 模式就变得格外的有用了。另外,把 DWARF 地图解析和处理的工作放到 Host-Side 也可以减轻真实运行环境的压力。最后,你如果真的不喜欢 remote 模式,特别是想质疑为什么要把这些剥离出真实运行环境,那么你也可以 SSH + GDB 直接去调试,这也算是自发的 remote 模式,不需要 GDB 额外做什么事情。
这里还需要注意的一点是,GDB 本身支持展示源码,不管是 list 命令,还是说通过 TUI 模式启动。能够实时看到源码,对我们调试工作肯定是有利无害的,这也是我特别喜欢 cgdb 的原因。然而很多时候,我们的环境里面明明有源码,但是 GDB 总是不能正确展示源码,一个经典的场景就是二进制是线上流水线构建的,而我们环境的源码是 git 下载的,源码大概率是无法正确展示。所以,我们需要了解一个问题:GDB 是怎么获取到源码文件的位置。
答案其实也很简单,源码文件的地址就在 DWARF 里面,更准确的说,每个编译单元对应一个源码文件,里面的属性就描述了存放着源码文件的绝对路径目录和源码文件带有相对路径的名称。我们再回到上面的问题的根因:源码文件在编译机器的路径和调试机器的路径不一样。而 GDB 会提供类似 set substitute-paht 这样的命令来帮助我们重新映射源码路径,来确保 GDB 在调试机器上找到我们源码目录所在位置。我们在上面的篇幅里面,对源码、调试信息、可执行文件和进程讲了很多内容,也明确了它们的存在的方式和各自的分工,所以这些 GDB 使用的细节,理解起来就变得很容易了。
和 AI 工具结合使用
现在市面上主流的 AI 工具,不管是 Claude Code、Codex 还是 Copilot 都能很方便的使用 GDB 来进行问题排查分析,我这里分享一些我日常使用的场景。我最早是拿 ChatGPT 帮我写 GDB 脚本,感觉还是在 ChatGPT 刚出来一年吧,具体时间记不清了,反正是听到大家说 ChatGPT 能写代码,我就去这么用了,反正效果还挺好。不管是 GDB 脚本,还是更复杂一些的 Shell 脚本,都能再几轮对话内给出符合要求的成品,那个时候,我还没有预见到,AI 工具能力能发展到现在这个地步。
再回到 GDB 脚本,某种程度上就是让 GDB 连续执行多个 GDB 命令。我个人觉得 GDB 脚本比较好用的核心是让 GDB 放弃了交互式的使用方式,改成静默持续执行。因为有的时候,我们是需要交互式的调试体验,但有的时候,我们只是需要在某个环境快速的,或者说是自动化的获取信息罢了。我还记得当年故障排查的时候,我师兄让我现场写 GDB 脚本,让我写的一头汗,现在全都可以放心交给 AI 来写了。
我的第二个高频使用场景,就是 Coredump 文件分析,一般来说操作系统会在进程 crash 的那一瞬间,把进程核心的信息都记录在 Coredump 文件里面,比如说我们上文提及的进程虚拟地址空间对应的数据内容,当时的所有寄存器数值,/proc/maps 里面的内容之类的。有了这些信息,GDB 才能进一步去把 crash 时候的调用栈等一些有用信息恢复出来。一般来说,没有调试信息,只要有符号表,调用栈还是能恢复出来的,只不过里面大部分函数只能是冷冰冰的偏移数字,而不是精准的源码行号。如果问题定位真的需要更精准的源码信息(手头还暂时没有调试信息的时候),我会把对应的汇编贴给 ChatGPT,然后让它给我解释一下,我再去看源码,确认精准的位置。是的,在 AI 时代,阅读汇编代码,完全不算是高级技巧了,只需要提问就好了。
现在有了 AI Code Agent,分析 Coredump 文件变得简单直接,Agent 可以自动分析定位出源码行号,然后再进一步结合源码来确认问题应该如何修复。如果项目构建、e2e 这些都做的让 AI 方便执行,那 Agent 甚至可以自动化的构建 Fix 版本,尝试复现问题,确认是否有没有真正修复问题,我们只需要最后审批下结果,看看根因是否正确,复现是否准确,以及修复方案是否合理,有没有引入风险,就结束了。是的,现在使唤 AI 使用 GDB 来排查问题,很多时候都是一条龙服务,非常贴心,但是我相信只有从原理上知道这些信息是从哪里获取到,怎么一步步推算到结论的,才能用的更有自信,也更能对 AI 的产出结果负责。
关于 GDB 很好的文章或者资料
《深入理解计算机系统》有一个实验 Bomb Lab,非常有意思,完美展现了在没有调试信息的情况下,获取可用信息是多么困难。我刚学计算机的时候,是迷迷糊糊做完了,这里给大家提供一个新思路,可以考虑和 AI 打配合完成这个实验,整个过程应该非常丝滑
这篇博客 GDB 从裸奔到穿戴整齐,主要是说各种 GDB 的配置方式,属于术的良好总结,唯一可惜的是我不用 emacs。tmux + vim + cgdb 已经是我装逼的极限了。
这篇博客 how-does-gdb-call-functions 讲述了 GDB 是怎么实现 call 命令的,其实某种程度上就是 jit 技术。
我还记得我好早之前跟着这个博客(用 Python 拓展 GDB)还有官方文档后面给 nginx 写数据结构展示的 Python 脚本,当初啥也不懂,就觉得好神奇,当然了,现在其实也没懂很多。
这里没有推荐官方文档,因为,嗯,确实有点多,感觉 AI 盛行的时代,大家是越来越不爱看官方文档了,至少我是不太爱看了,大家关于术上面的疑惑,直接问 AI 就完事了。
尾声
这篇博客写的有点断断续续的,时间跨度长达两三个月,导致有点脱节,可能读起来也比较割裂,毕竟开头还在庆祝美股暴涨,而现在的新闻头条则是川普在施压欧洲,想染指格陵兰岛,美股承压,以至于所有多头都在等待 taco。
至于写这么长时间的原因,一方面我觉得是因为我实力有限,虽然脑海中早就已经有了这篇博客的雏形,但是在写博客的过程中,还是有点磕磕绊绊的,得不停的翻阅资料和编写测试程序来验证想法,哪怕现在已经写完了,依然还是觉得不太满意,但是写了好久还是干脆发出来吧🐶。而且因为篇幅巨长,很多内容不得不临时砍掉,比如 rust-gdb 的实现细节,包括 GDB 本身是怎么支持多编程语言的实现细节。
另外一方面,就不得不责备一下 33 号远征队,本来我在圣诞和年底的时候,我给自己放了八天假,我不是一个喜欢旅游的人,平时只喜欢待在家里,也给自己规划了很多学习任务,然而突然看到 33 号远征队拿了年度游戏奖项,就把所有计划放在一边,一口气通关了这款游戏。另外,这款游戏对我来说还有额外的意义,毕竟按我现在的年龄,我也得参加 33 号远征队了,不然就要被抹煞了。这让我在想,人生的意义究竟是什么,不过我没有想出个所以然出来。这让我感觉我对人文社科的知识掌握的太少,也许我应该像研究技术底层细节一样研究隐藏在社会背后的运行规律,至少是某一领域的。所以我最近正在学习区块链,虽然有点逆潮流,但是对我来说很有意义,还可以顺便补充一下基础的金融学知识。