Learning eBPF the Hard Way: 从 nginx eBPF 的实现说起
前言
关于新系列的严正声明
首先这个标题起的调子有点高,搞得好像我对 eBPF 有着非常深入的理解一样😂,如果是冲着 eBPF 高端进阶内容点进来的哥们,我只能先说声抱歉。因为我其实还处于学习 eBPF 的社会主义初级阶段,有蛮长的路还要走,只是想通过这个新系列博客来记录我是怎么一路摸爬滚打学习 eBPF 的,以及督促自己加快学习进度,以练代学,早日进入下一个发展阶段。讲道理 eBPF 应该没那么难学才对,我也在认真的自我反思,为什么会踩那么多坑,所以这个系列就是我自我反思和学习总结的一个过程。
为什么喜欢 eBPF 技术
eBPF 技术介绍
考虑到标题都起成这样了,那 eBPF 技术相关基本介绍,本博客是不准备提一个字了,不然怎么叫 the hard way,反正基本概念都可以问问 AI,AI 能巴拉巴拉扯好长一坨。我在刚学习 eBPF 的时候,是直接找了一本电子书 learning-ebpf,这书其实写的挺不错的,蛮适合入门 eBPF 的,只不过我当时看的很粗略,本来是打算细读一遍的,但是在当时读的时候,遇到了不少我刚接触的上下文,让我果断决定还是边实践边回看吧。
对了,在了解了 eBPF 技术之后,如果对 Linux 下追踪系统的大概情况还是存在疑惑,比如不晓得 eBPF 是依赖哪些机制,怎么获取到想看到的数据,什么阶段生效的,诸如此类的问题。大家可以看看这篇博客的 Linux tracing systems & how they fit together,会在 high-level 层面上有一个非常直观的认识。毕竟,哪怕用 bcc 或者 bpftrace 进行了一些实践,刚接触的话,还是会存在大量的问题,因为这些好用的框架和工具隐藏了底层太多的细节。
什么样的 Bug 最难排查
在聊我为什么喜欢 eBPF 技术之前,我想聊一个老生常谈的问题,什么样的 Bug 最难排查。可能直觉上,大家会觉得一眼扫不到根因或者问题出在自己不熟悉领域的 Bug 会非常难排查。但是我个人的经验教训来说,我觉得难以复现的 Bug 是最难排查的。
我觉得排查 Bug 的过程,本质上是不断收集信息的过程,当获取的信息越多,那么 Bug 根因定位就更容易也更清晰。而可以稳定复现的 Bug,意味着我们是可以源源不断获取到我们需要的信息,根据这些信息来不断纠正我们排查问题的方向,缩小排查范围。最经典的获取信息手段就是加大量日志,在复现 Bug 的路径上慢慢研究,哪怕是不熟悉的第三方依赖,我们也有信心去把问题定位清楚(不行可以拉外援,没外援就自己硬着头皮看),最坏也可以把问题收敛在某一处很小的范围内。
但是,如果 Bug 是出现在线上环境,只有非常小概率发生的话,一旦当时仅有的信息无法定位出 Bug,那么这种 Bug 的排查过程就会格外痛苦。这个其实很好理解,大部分获取排查信息的方式都是有着比较高的成本,比如临时修改版本添加日志,光是发布流程就够喝一壶。而且日志添加也是个大问题,添加多了影响线上系统的性能和成本,添加少了没抓到关键信息,白白发布一轮,Bug 解决却遥遥无期,更别提新增日志可能带来的性能和稳定性隐患。一想到这,是不是觉得自己和老板之间脆弱的信任关系又多了一些裂痕😂。
eBPF 是这类问题的救世主
eBPF 技术本身在设计上就具备灵活(可编程)、低开销、安全这些核心特性,可以针对这种难以复现的 Bug 来快速持续的获取相关信息,是真正的救世主。是的,没有什么 Bug 在获取到足够的信息后,还是无法解决的,大家想必看过很多有趣的 Bug 排查分享文章,而这些文章更多都是在分享排查思路和具体信息应该怎么高效获取。
当然 eBPF 其实在很多领域都大放异彩,这里我就不啰嗦了,但是我最喜欢 eBPF 技术的点,还是在于 eBPF 真的可以很好的帮助排查一些困难的问题。这里,我想推荐一篇写的非常好的技术博客(动态追踪技术漫谈),这篇博客里面就做了非常好的阐述,我每年基本都会再读一遍这个博客,感觉真是常读常新。至于我为什么对这块特别感兴趣,不仅仅是因为问题排查是一个工程师的核心能力,更多的是我以前的工作经历,大家可以看我之前写的一篇博客(线上故障应急处理:4 年多 on call 经验总结),来感受我的心路历程🤣。
可惜的是,我在第一份工作中基本没有机会用到 eBPF 技术,主要是内核版本太低了,当时线上环境一直是 3.10 版本,根本都不支持 eBPF。当时基本就只能使用 systemtap 救救急,但是 systemtap 显然没有 eBPF 好用,我印象深刻的一件事情是,好久好久之前,我一个临时编写的 systemtap 脚本直接把线上一台机器干宕机了,还有一次把 CPU 干了百分百,要是被抓住就算是踩安全生产红线了,算是鬼门关前面走了一遭,不到万不得已,我肯定是不会乱用 systemtap 了。
Reuseport eBPF
上面说到我在一开始学习 eBPF 的时候,总感觉学的有点干巴巴的,正好我知道 eBPF 是 UDP-Based 传输协议数据包正确匹配到特定进程问题的解决方案之一,所以我在学习 eBPF 的时候,索性就以这个问题是怎么被 eBPF 解决的,作为学习 eBPF 的切入点。不过,在开始下面的内容之前,建议先阅读一下我之前的两篇博客(用 Rust 从零开始写 QUIC:实现连接迁移 和 Linux 服务端 UDP 网络编程:无损热更新),了解相关问题背景。
Linux 内核解决方案
在 Linux 服务端 UDP 网络编程:无损热更新博客里面,我贴出了大量 Linux UDP sk 匹配查询逻辑的代码,如果看过那篇博客的话,想必都能注意到,其实有一些 eBPF 相关实现,也在这里面的核心逻辑中一闪而过。更具体是在 Linux 内核源码这里,eBPF 在 Reuseport 查询匹配的核心逻辑里面,插入了自己的 Hook 点,也就是 eBPF program type BPF_PROG_TYPE_SK_REUSEPORT,这意味着当 UDP 数据包在内核 UDP 二元哈希表里面查询匹配的时候,找到了合适的 Reuseport Group,并且有对应 eBPF 程序被 attach 到这个 hook 点上面去,那就会执行 eBPF 程序中定义的查询匹配逻辑,如果 eBPF 代码主动放弃选择对应的 sk,那么还是会走到原有的逻辑,根据 UDP 四元组哈希在 Reuseport Group 中快速挑选一个 sk 来处理该 UDP 报文。
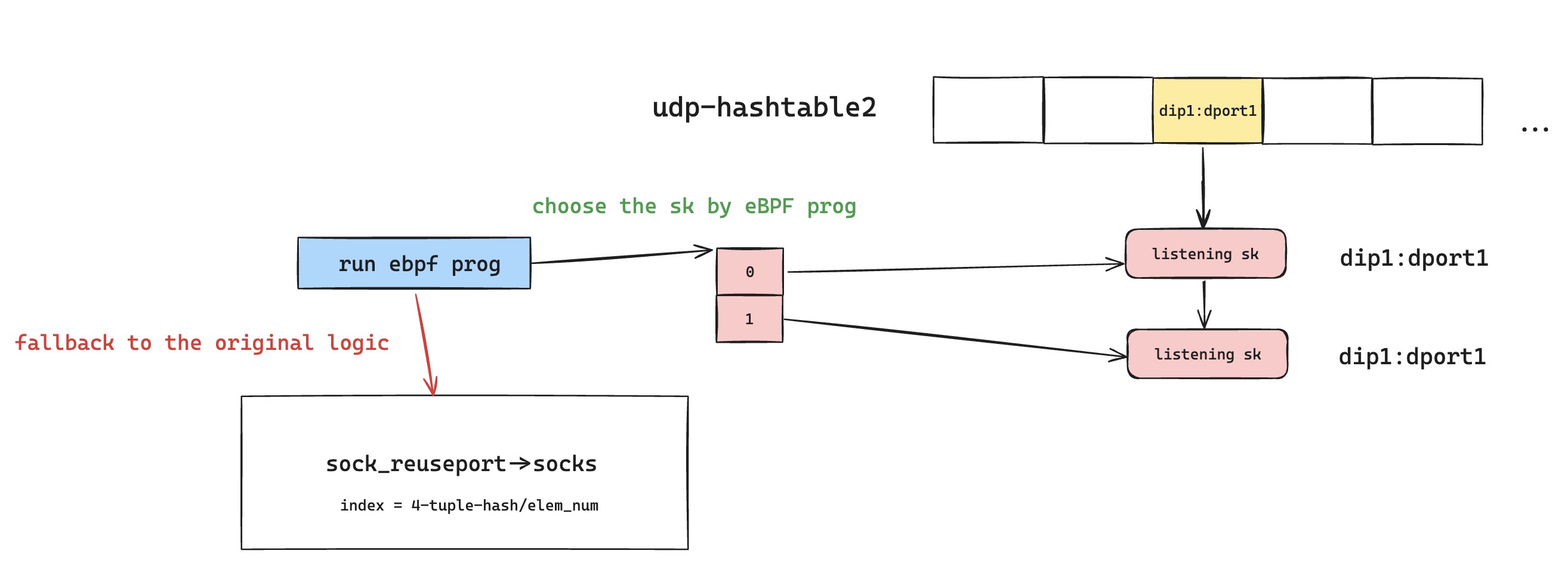
接下来,就是看内核为了 BPF_PROG_TYPE_SK_REUSEPORT 类型的 eBPF 程序提供了哪些能力,来方便实现 UDP-Based 协议中的数据包精准的找到属于自己的 sk。我在用 Rust 从零开始写 QUIC:实现连接迁移这篇博客里面提到过,UDP-Based 协议一般都不会使用 UDP 四元组来作为协议的连接标识符,这么做的好处是和 UDP 以及更底层做了解耦。比如说,QUIC 就使用了 connection id 来协商出独一无二的连接标识符,那以 QUIC 为例,eBPF 程序必须能够对数据包,更准确的说是 UDP Payload 进行特定的解析,获取到自定义协议的连接标识符,即 QUIC connection id。然后再根据连接标识符,让 QUIC 连接的流量整个生命周期中所有 UDP 数据包,都牢牢锁定唯一的 sk 来处理,不管 UDP 四元组有没有变化。
接着就是继续看如何使用 eBPF 程序了,在 BPF_PROG_TYPE_SK_REUSEPORT 文档中提及了,eBPF 程序上下文参数是 struct sk_reuseport_md,从这个参数身上可以获取到 UDP Payload 数据等关键信息。另外,eBPF 程序还提供了 BPF_MAP_TYPE_REUSEPORT_SOCKARRAY 类型的 eBPF Map 和 bpf_sk_select_reuseport helper 函数。
具体使用方法的话,该 Map 作为一个哈希表,它的 key 大小是 4 字节索引,而 value 则是开启了 reuseport 的 sk,我们可以直接理解成套接字。所以,我们在创建完该 eBPF Map 之后,需要手动把自己负责监听的 UDP 套接字给插入到这个 Map 里面。然后在 eBPF 程序里面,从 UDP 数据报文里面获取到对应的 key 具体数值,然后通过调用 bpf_sk_select_reuseport 来选择正确的 sk,即唯一的 UDP 套接字。
但这里有个需要注意的点,就是在具体实践中,一般来说,不会维护每个 QUIC 连接和 UDP 套接字的映射关系,因为这样的话,成千上万个链接,对哈希表大小是有要求的。要知道 eBPF Map 大小是固定的,自然也不会有 rehash 扩容一说,这么做应该是出于安全的考量。所以,实现方式和用 Rust 从零开始写 QUIC:实现连接迁移博客里面提及的 QUIC-LB 方案类似,在 eBPF Map 里面的,每个 UDP Reuseport 套接字只会被插入一次,这些套接字对应的 key 是固定的。这样的话,QUIC 的 connection id 只需要按照私有约定把 key 装进去就好了,一般 4 字节大小的 key 不会用完整个 connection id,所以 connection id 也不会因为这个影响唯一性。这里,如果感觉还是有点模糊,下面分析 nginx 源码实现的时候,也会进一步解释。
应用层的正确使用方式
由于我们可以自行编写 eBPF 程序,来决定 UDP 数据包到底归属于哪个 Reuseport 套接字,所以,我们不需要像 Linux 服务端 UDP 网络编程:无损热更新博客里面提及的 Established-over-unconnected 技术方案那样,模拟 TCP 网络编程的操作,给每一个 UDP-Based 传输协议连接创建一个独立的 UDP 套接字,寄希望于内核 UDP 数据包的查找匹配逻辑,来保证诸如 QUIC 连接数据包始终由一个 UDP 套接字来接收的效果。
可以参考下图,每个进程仅需要持有一个 UDP 套接字,新的 QUIC 请求 eBPF 程序会 bypass 掉,交给内核默认的 UDP 四元组哈希查找逻辑来负载均衡分配给所有监听进程,即图中的第二步负责处理新请求。然后 QUIC 请求在完成握手的过程中,会更新自己的自定义 connection id,确保 connection id 中会持有图中 eBPF Map 里面对应的 key 数值。这样后续的 UDP 数据包,可以服从 eBPF 程序逻辑,获取 eBPF Map 的 key,查询到属于自己的 UDP 套接字。
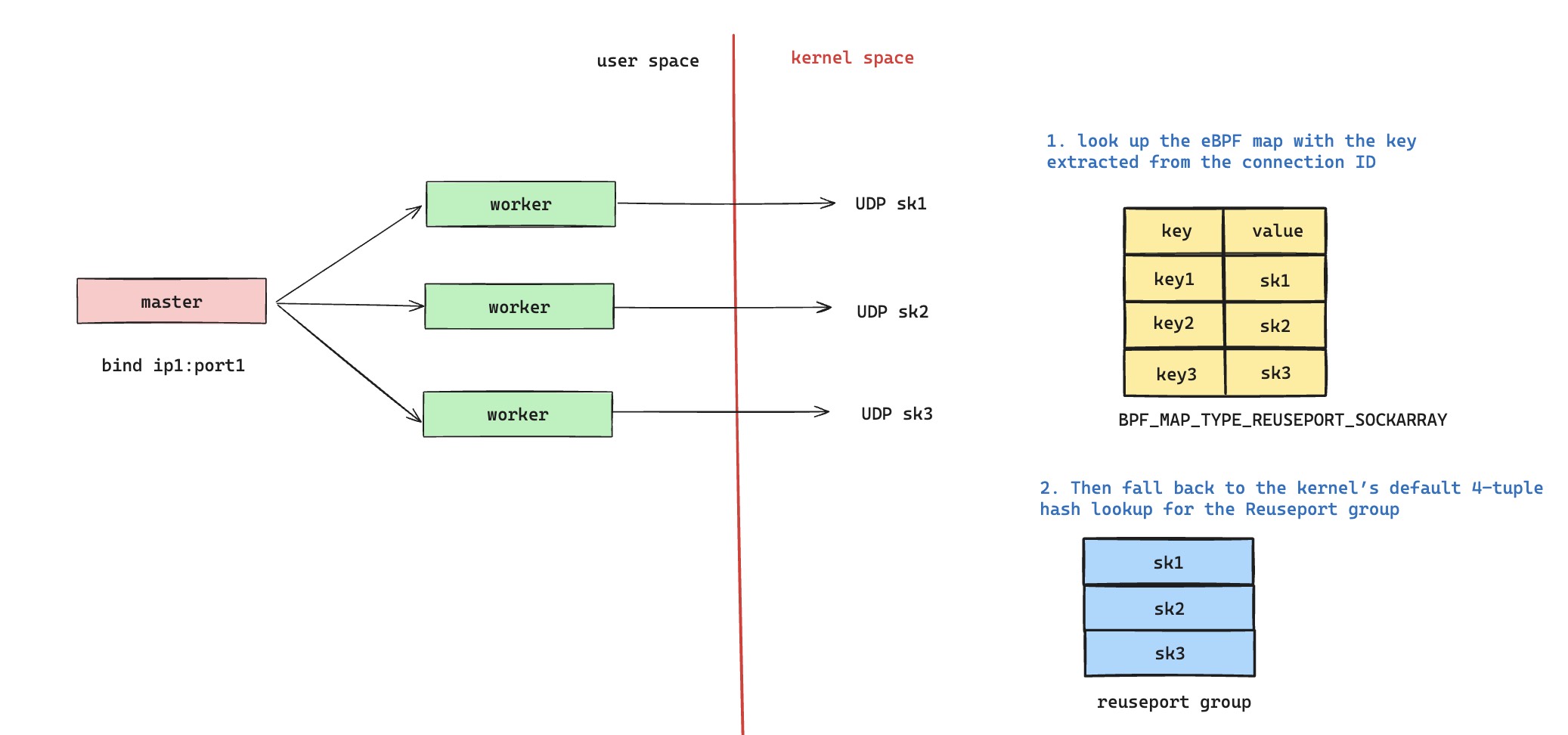
可能有人会说,如果没有 eBPF 程序或者 Established-over-unconnected 方案,是不是 QUIC 也能工作的很好,毕竟内核会一直按照 UDP 四元组的哈希值来查询 Reuseport Group 里面的 sk。但是之前聊到过,QUIC 存在连接迁移,UDP 四元组并不是 QUIC 连接唯一性的标识,一旦 UDP 四元组发生切换,那么走默认内核分配逻辑就会出现问题。另外,Reuseport Group 也不是一成不变的,热更新场景就会导致 Reuseport Group 发生变化,那么整个哈希查询的结果都会发生错乱,这些都是 QUIC 无法接受的。所以,我们接下来会分析 nginx 是怎么通过 eBPF 技术来解决这个问题的,要知道上面这张图其实还不够完备,只能解决 QUIC 连接漂移场景,没有办法解决好热更新问题。
nginx eBPF 实现细节
聊完上面 Reuseport eBPF 的原理,想必大家还只是对 eBPF 技术只有一个模糊的认知,只是知道 Reuseport eBPF 大概是在内核哪个阶段生效的以及作用是什么,但是没有真实的感受,至少我当时就是这样 😛。所以,那接下来就是看 Reuseport eBPF 具体怎么在实战中被使用的,我当时正好看到 nginx 里面引入了 eBPF,也是为了解决上述的问题,所以我就很开心的一头扎进了 nginx eBPF 的实现细节里面。
源码阅读时产生的问题
我在阅读代码的时候,喜欢先尝试给代码挑毛病,哪怕是 nginx 这样知名的开源项目,我也会跃跃欲试,可能是挑刺比创造容易得多吧。
libbpf 去哪里了
快速游览一遍,nginx eBPF 相关的代码大概有三处地方:
- src/core/ngx_bpf.c 里面封装了 bpf 系统调用,支持 eBPF 程序加载和 eBPF Map 增删改查
- src/event/quic/bpf/ 这个目录里面,有要被加载到 eBPF 程序代码,是用 c 编写的。
- src/event/quic/ngx_event_quic_bpf.c 是维护 nginx Reuseport QUIC 监听配置的套接字,插入到 eBPF Map 里面
我心里开始产生了第一个问题,libbpf 去哪里了,我刚熟悉了的 bpf skeletons 去哪里了。好歹跟着教程写了几个样例,结果在 nginx 里面没找到一点熟悉的痕迹。于是我仔细的翻了翻代码,发现了 nginx eBPF 构建脚本的存在,看了一下脚本,大概明白了 nginx 的做法,是把 src/event/quic/bpf/ngx_quic_reuseport_helper.c 文件里面的 eBPF 程序通过 clang 编译成 eBPF 字节码,然后从 clang 编译出的可重定向文件里面,把 eBPF 字节码给扒拉出来,然后生成出 src/event/quic/ngx_event_quic_bpf_code.c代码文件。
ok,有点元编程的感觉了,这么做的话,难怪不需要 libbpf,蛮酷的,我瞬间就自以为明白了 nginx 这么做的精髓,当然是为了减少第三方依赖,这样更干净。我又仔细看了相关构建脚本并没有在 nginx 的构建流程里面被调用过,所以我确定了 src/event/quic/bpf/ 这个目录只是为了方便大家理解 nginx eBPF 程序的逻辑,其实只有 src/event/quic/ngx_event_quic_bpf_code.c 是真正参与了 eBPF 功能的实现。
可能的资源泄露?
接着,我又去习惯性的看了下结束流程,比如说热更新的时候,随着老进程的退出,eBPF Map 是怎么处理的。我突然惊讶的发现,nginx 代码中的 ngx_bpf_map_delete 是一次都没有被调用,我打了个激灵,这玩意会不会资源泄露了。我又去检查了一下,每次热更新的时候,QUIC Reuseport 套接字都会重新创建,然后新的套接字会被插入到 eBPF Map 里面,而老的套接字却没有从 eBPF Map 里面删除掉。
我转念一想,nginx 不可能犯这种错误的,考虑到 eBPF Map 是固定大小,这玩意也很容易被发现的。是不是又是那种老旧的套路,套接字被删除的时候,能够自动从 eBPF Map 里面删除掉。我看了下 nginx 使用的 eBPF Map 是 BPF_MAP_TYPE_SOCKHASH 类型,这个倒是让我有点惊讶,我本来以为会使用 BPF_MAP_TYPE_REUSEPORT_SOCKARRAY 类型。看下了 BPF_PROG_TYPE_SK_REUSEPORT 文档里面,明确说了内核 5.8 之后,也支持 BPF_MAP_TYPE_SOCKHASH Map 类型。
Since v5.8
BPF_MAP_TYPE_SOCKHASHandBPF_MAP_TYPE_SOCKMAPmaps can also be used with this helper.
首先,BPF_MAP_TYPE_SOCKHASH 类型的 eBPF Map 是支持套接字被最终关闭的时候,顺带也自动清理掉 eBPF Map 的元素,所以是不存在资源泄露这一说了。以防万一,我实际启动了一组 nginx 来做了测试,测试方法很简单,使用 sudo bpftool map dump id {map id} 命令去检查对应的 eBPF Map 成员个数,在进行了 nginx reload 之后,当所有的 shutting down worker 都退出后,Map 成员个数又和 worker 个数一一对应了,所以没有资源泄露问题。但是我又有了一个新的想法,就是当我看到 nginx eBPF Map 默认大小是 worker 进程数的四倍,我突然觉得如果反复进行 nginx 热更新的话,并且老进程还没来得及退出,那么 eBPF Map 大小肯定是不够用的。我很轻松复现了这个边缘场景,刻意准备几个 idle 请求,让老进程不退出,然后就复现出来了。不过,我觉得这个场景倒是没有什么修复的必要,因为反复热更新就是不合理的使用场景。
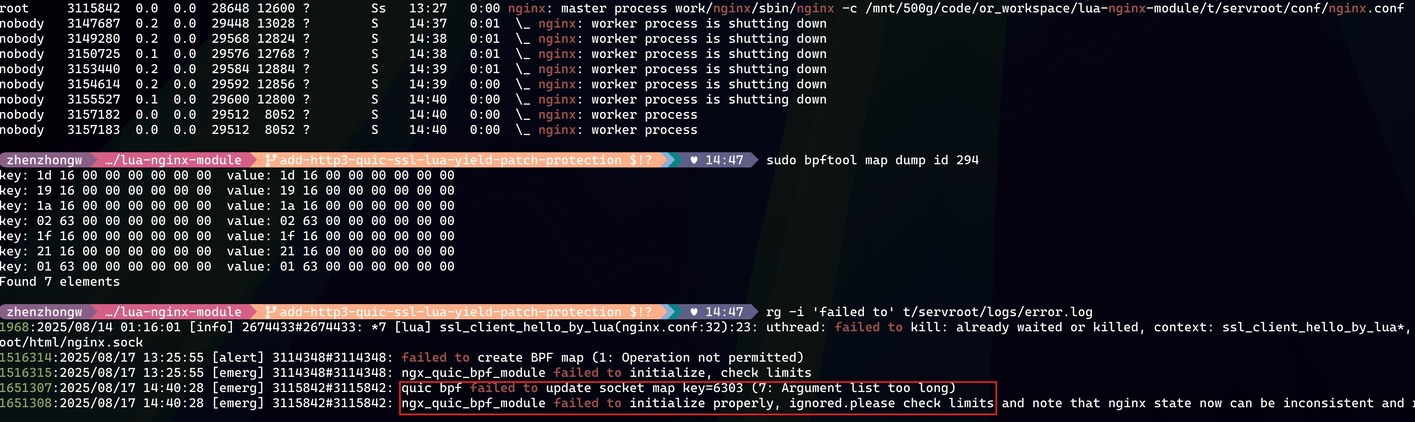
其次,为什么 nginx 会使用 BPF_MAP_TYPE_SOCKHASH,而不是 BPF_PROG_TYPE_SK_REUSEPORT 。我个人觉得,应该是 BPF_MAP_TYPE_SOCKHASH 更加灵活,是一个真正的哈希表,只要 key 是固定的,就能轻松确保使用的 sk 是唯一不变的。而 BPF_PROG_TYPE_SK_REUSEPORT 则是使用数组,key 是数组下标,那么意味着删除和新增该 Map 的时候,需要特别小心,才能不打破映射关系,并且有一些复杂的场景不够灵活。
最后再补充一下,上面提及过的, BPF_MAP_TYPE_SOCKHASH 中每个 Reuseport sk 对应的关键字一般用什么,怎么能有一个独一无二的关键字给每个 sk 使用呢,这里通用的做法,在 nginx 源码中给出了示范,每个套接字都有一个独一无二 cookie,这是内核提供的能力,我们使用这个 cookie 来作为 eBPF Map 的 key 来使用,然后再把这个 cookie 包含在 QUIC connection id 里面,这样的话,就可以确保 QUIC 连接一直由这个 cookie 对应的套接字来接收数据了。
无法正确处理热更新场景?
接着,我们就去仔细阅读 nginx 编写的 eBPF 代码了,就是这个 src/event/quic/bpf/ngx_quic_reuseport_helper.c 代码文件。读着读着,我突然发现了一个新的问题,nginx 在进行热更新的时候,新的请求有可能被分配到老的 worker 上面服务。
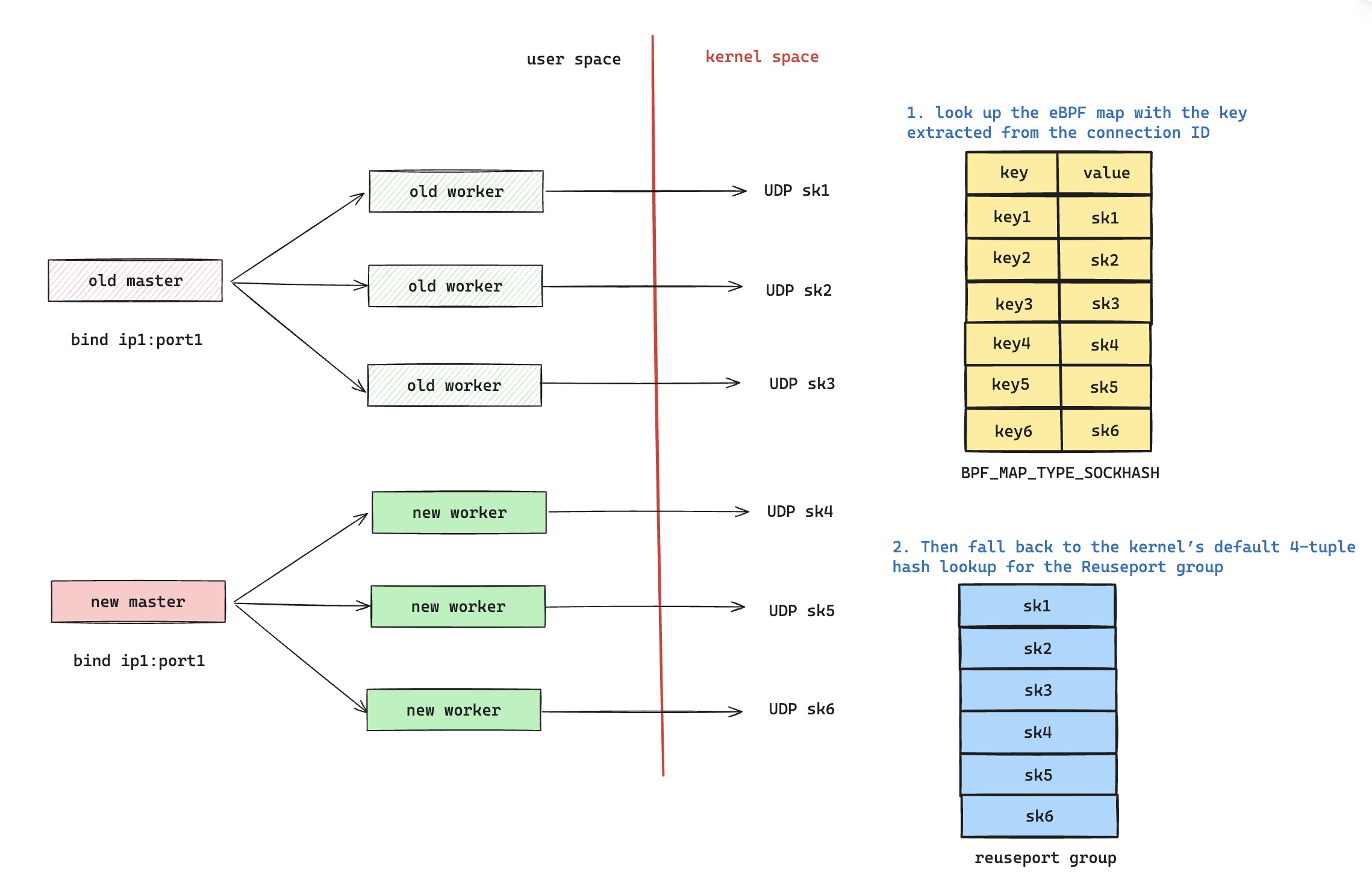
以图中为例,当 nginx 发生热更新的时候,老进程如果还有正在服务的请求,那么老进程持有的 UDP 套接字不会关闭,eBPF Map 里面会同时存在新老进程的套接字。这样的话,新老进程正在服务的 QUIC 连接可以正确的查询到属于自己的 sk,进行正确的匹配。但是存在一种情况,就是如果是新的请求打过来,是肯定无法命中 eBPF Map 的。所以只能走图中的逻辑 2,即服从 UDP 四元组负载均衡哈希查询,但是 Reuseport socket 里面存在新老进程的套接字,这意味着会有一部分请求被分配到老进程上。而老进程这个时候,已经进入了 ngx_exiting 状态,这里可以从 nginx 代码上看到,这部分请求只能通过超时感知到失败。
尝试复现问题
当我意识到 nginx 可能存在这个问题之后,我觉得有点逆天,很难想象 nginx 会犯这样的错误,于是乎,我立刻开始尝试复现该问题。
先从加日志开始
这个问题复现我本来预想应该是挺简单的,nginx eBPF 功能配置一开,在热更新状态下,利用一些长连接请求刻意维持住老 worker 不退出,然后开始打 HTTP/3 新请求给 nginx 服务,预期会有一些请求拿不到响应,但是 curl 工具发出的每个请求都顺利获取了响应。额,有点尴尬,和我源码分析的猜想不一致,难道我理解有问题。为了更进一步的分析该问题,我灵光一闪,不如给 nginx eBPF 程序加点日志,这样看的更清楚一些,于是我猛踩一坑😒(本文主题终于正式开始)。
首先,我先尝试给 src/event/quic/bpf/ngx_quic_reuseport_helper.c 代码添加更细节的日志,我当时也没多想,反手就把 debugmsg 改成 eBPF 日志输出函数 bpf_trace_printk,当然这里需要把第二个参数,fmt 的长度也补上。然后开始尝试自己通过 src/event/quic/bpf 目录下面的相关构建脚本生成 src/event/quic/ngx_event_quic_bpf_code.c 文件。
经过几次短暂的尝试终于构建成功了,不过遇到了一个小问题,编译 nginx eBPF 程序的时候,报了一个编译错误: error: variable has incomplete type 'struct bpf_map_def',我当时也没多想,网上搜了一搜,记得当时是找到了这个 Explain where bpf_map_def comes from,而这里面啰了八嗦,我也没心情看,索性自己临时把 struct bpf_map_def 这个结构体也给补上了完整定义,也没去多想为什么 libbpf 头文件里面没有包括这个定义。但是,我有点费解,ngx_quic_sockmap 这个 eBPF Map 变量只有声明,没有定义,为什么 nginx 里面没有去实现这个 Map 的定义呢。
处理完这些之后,我直接把生成的 ngx_event_quic_bpf_code.c 文件给替换掉,但是在启动 nginx 的时候,就遇到了 eBPF 字节码加载报错,cannot call GPL-restricted function from non-GPL compatible program,这个报错倒是很好理解,bpf_trace_printk 要求 eBPF 程序必须是遵循 GPL 协议,而 nginx 是 BSD like 开源协议,所以我们调试的时候,需要手动把 License 代码修改成 GPL,这样 eBPF 字节码被 bpf 系统调用加载的时候,也会主动消费这个。不过,我更好奇的是为什么 bpf_trace_printk 强制要求 GPL 程序,可能是 bpf_trace_printk 性能较差,仅供调试选择,所以只希望严格遵循 GPL 开源协议的程序才能使用它。
直接遇到了 eBPF 字节码加载的错误。具体错误内容,我贴在下面了,直接搞得我两眼一抹黑,完全不知道怎么办。再回看一下我修改的代码,除了 Map 定义,就是挑了一行 debugmsg 代码修改成了 bpf_trace_printk("nginx quic socket selected by key 0x%llx", sizeof("nginx quic socket selected by key 0x%llx"), key);,我当时百思不得其解。
132: (bf) r3 = r2 ; R2_w=pkt(off=13,r=14) R3_w=pkt(off=13,r=14)
133: (07) r3 += 9 ; R3_w=pkt(off=22,r=14)
134: (2d) if r3 > r5 goto pc-6 ; R3_w=pkt(off=22,r=22) R5=pkt_end()
135: (71) r4 = *(u8 *)(r2 +1) ; R2_w=pkt(off=13,r=22) R4_w=scalar(smin=smin32=0,smax=umax=smax32=umax32=255,var_off=(0x0; 0xff))
136: (67) r4 <<= 56 ; R4_w=scalar(smax=0x7f00000000000000,umax=0xff00000000000000,smin32=0,smax32=umax32=0,var_off=(0x0; 0xff00000000000000))
137: (71) r3 = *(u8 *)(r2 +2) ; R2_w=pkt(off=13,r=22) R3_w=scalar(smin=smin32=0,smax=umax=smax32=umax32=255,v
2025/08/20 10:55:59 [emerg] 3605800#3605800: ngx_quic_bpf_module failed to initialize, check limits
日志问题排查
我当时回头又去快速的翻了一翻 learning-ebpf 这本书,正所谓边学边练。突然想到要是 eBPF 字节码有问题,我干脆尝试直接用 bpftool 直接去 load 这些字节码呢,看看有没有什么线索。于是说干就干,我起手就用 bpftool 去加载我编译的可重定向文件。sudo bpftool prog load ngx_quic_reuseport_helper.o /sys/fs/bpf/reuseport 跑了一下,结果又是一个加载失败报错: libbpf: elf: legacy map definitions in 'maps' section are not supported by libbpf v1.0+。这个,我也去翻了一翻,发现 libbpf 官方 淘汰了对 struct bpf_map_def SEC("map") my_map; 这类写法的支持。我光速滑跪,换成了最新的正统写法,即定义好完整的 Map 数据结果,然后存放在 .maps 的 section 里面。然而,我还是产生了一个疑问,这个写法变化的优势是什么,我们后面再说。
改完之后,我接着又遇到一个加载错误:libbpf: BTF is required, but is missing or corrupted,这个倒也难不倒我,我很快知道 BTF 是 eBPF 的类型信息,有点像 Dwarf 调试信息那样,使用 clang 的时候,只需要加一个 -g 编译选项,就可以生成出来。但是我又开始困惑了,理论上来说,调试信息不应该影响 eBPF 字节码加载才对啊,为什么这里 BTF 是必需品,nginx 为啥不需要这玩意。
紧接着又是加载错误: libbpf: failed to guess program type from ELF section 'ngx_quic_reuseport_helper',看到错误提示,我大概明白 elf section 名字也是要讲规矩的,我得按照 bpftool 的规则来办事,eBPF program type 是什么,全靠这个 elf section 的名字,于是我把代码里面对应地方给改成了 sk_select_reuseport。
终于,bpftool 运行成功了,目前的 eBPF 字节码被成功加载了。然而这并不是一个好消息,因为我的问题还没有得到答案,为什么 nginx 加载这段 eBPF 字节码就失败了,而 bpftool 却能加载成功,这个不科学。我快速的掏出 strace 来看 nginx 和 bpftool 在加载字节码的时候,系统调用上有没有区别。sudo strace -e bpf bpftool prog load ngx_quic_reuseport_helper.o /sys/fs/bpf/reuseport 跑了一下,我仔细对比两者的 bpf 调用情况,发现 nginx 比 bpftool 多创建了一个 eBPF Map。sudo bpftool map show 展示出来当前的 eBPF Map,很快找到多创建的 eBPF Map 名字叫 .rodata.str1.1,紧接着我通过 sudo bpftool map dump id {map id} 获取到了里面的内容,再通过 readelf 查看 eBPF 可重定向文件里面 .rodata.str1.1 section 内存,发现两者完全一致。
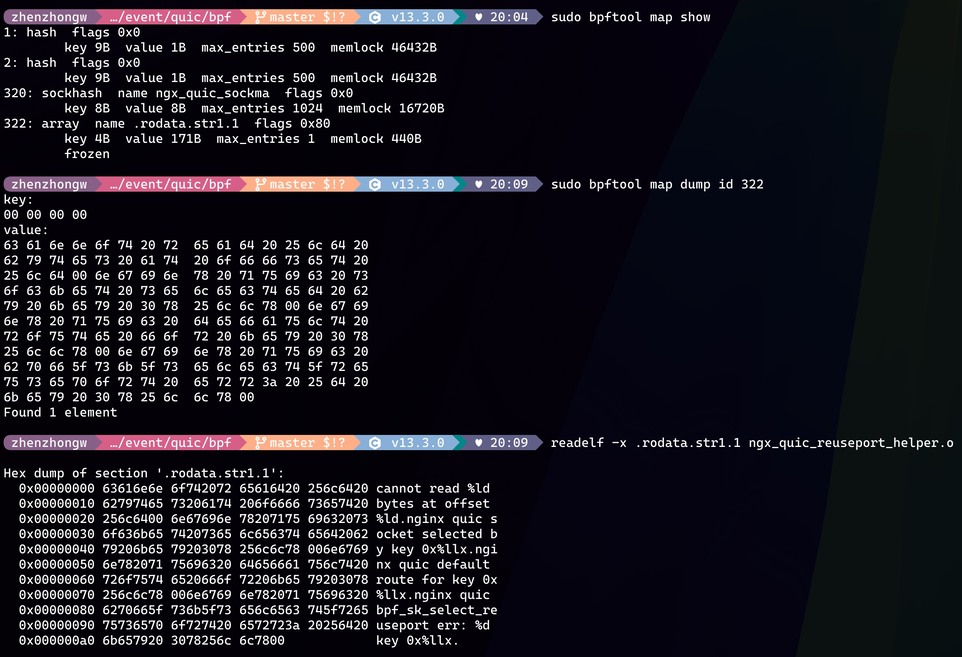
排查到这里,其实真相已经水落石出,bpftool 显而易见的比 nginx 多做了一些工作,所以相同的 eBPF 字节码才能被加载成功。而这些工作,应该就是 eBPF 字节码链接和加载工作。我在 eBPF 程序里面新增的打印日志的代码,使用了字符串常量,即 bpf_trace_printk 的 fmt 参数。这种字符串常量既不存放在栈上,也不是存放在堆上,在编译的过程中,clang 将这种字符串常量还是像普通 c/c++ 编写的程序一样,存放在类似 rodata 段里面。像 c/c++ 会在链接过程中,针对访问字符串常量的代码进行地址重定向。所以,eBPF 在被加载的时候也需要做类似的事情,只不过 eBPF 不像常见的用户态进程一样拥有虚拟地址空间,所以必须通过 eBPF Map 的方式来存放 .rodata.str1.1 段,然后主动去修改 eBPF 字节码,进行类似地址重定向一样的工作。
nginx eBPF 重定向实现细节分析
下面我们来看看 eBPF 怎么进行地址重定向的,像 nginx 构建脚本 其实已经给了我们一些提示。我们直接输出可重定位项的细节,如下面所示。我们可以看到这段 eBPF 程序里面,一共有两处地方需要被重定向,一处是 nginx 里面本来就有的,对 eBPF Map 的使用,另外一处就是我们新增的 bpf_trace_printk 调用,需要把调用参数重定向到对应的 section 里面。那我们先参考下 nginx 里面的做法,首先可重定位项中 OFFSET 是要被重定向 eBPF 字节码在 .text 段的偏移量,需要注意的是,该偏移量是字节为单位,而一条 eBPF 字节码是 8 字节,所以要简单处理下,就是 0x500 % 8 = 160,即第 161 个 eBPF 字节码是要被重定向的。
/usr/bin/llvm-objdump-18 -r ngx_quic_reuseport_helper.o
ngx_quic_reuseport_helper.o: file format elf64-bpf
RELOCATION RECORDS FOR [sk_reuseport]:
OFFSET TYPE VALUE
0000000000000500 R_BPF_64_64 ngx_quic_sockmap
0000000000000560 R_BPF_64_64 .rodata.str1.1
所以,我们看到 nginx 源码中对该指令做了两处修改,我先快速的把这条指令通过 objdump -d 给找到,即 line 160: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0x0 ll。其中一处修改是把 src_reg 设置为 1,另外一处修改是把 imm 给设置成了新建的 eBPF Map fd 了。为了深入理解这些改动究竟是干什么的,我含泪翻看了 eBPF 指令集文档。根据 objdump 反汇编的友好输出结果 r2 = 0x0ll,我至少知道这条指令是给 R2 寄存器赋值的。eBPF 指令集又表明 R2 寄存器是代表 eBPF 函数调用的第二个参数,而 bpf_sk_select_reuseport 第二个参数正好是 eBPF Map,至少我们目前是找对了地方。
然后我按照指令集文档把这条指令的操作码给翻译出来,即 BPF_LD | BPF_IMM | BPF_DW,代表立即加载 64 位立即数到 R2 寄存器上,所以这其实不是一条指令,而是两条指令,毕竟立即数是 64 位的,这也难怪重定向信息中,类型是 R_BPF_64_64。接着进一步分析 nginx 那两个操作,第一个是把源寄存器置 1,这个在指令集文档也有详细说明,如果希望使用 eBPF Map fd 来指代 Map,那就直接赋值 1 就完事了(dst = map_by_fd(imm))。nginx 的操作就很清晰明了了,可能还需要注意的是,fd 都是 32 位大小,所以只需要像 nginx 里面实现一样,改第一条指令里面的立即数就好了。
解决日志问题
这个时候其实日志问题解决起来就很简单了,有两种办法。方法一的话,nginx 其实就已经提供了,代码这里直接用栈变量来存放 fmt 字符串,这样常量字符串直接不需要了,那就啥也不用搞,直接就能看到日志。当时我回过头来才发现这里,差点把大腿拍断,而且 libbpf 也有专门的打印宏 bpf_printk 也帮忙做了类似的事情,甚至更多。
第二种方法就是自己来实现对 fmt 字符串的重定向,这里论效率上肯定是上面的方法一来得高,但是方法二比较万能,至少我是知道 eBPF 栈空间大小是被严格限制的。这里面的工作呢,其实就是上面分析的 nginx 做的事情,再干一遍,包括自己创建 eBPF Map,根据 rel 段找到重定向信息,然后找到对应的指令,根据指令文档,把重定向乖乖做完,在下面我会提供一个 c 语言实现的样例。
最后的话,eBPF 打印日志其实不是很推荐直接使用 bpf_printk 这类调用,这篇博客 有比较详尽的分析,主要是存在一些性能问题,并且不是很灵活。通常 eBPF 打印日志的需求,其实也可以归类为 eBPF 空间试图向用户态进程发送数据,所以生产级别的实现都是使用 BPF_MAP_TYPE_PERF_EVENT_ARRAY 或者 BPF_MAP_TYPE_RINGBUF 来把日志信息传递到用户态进程,再做展示和分析。对了,再推荐下 aya-log 这个项目,做的非常精巧,就是这类实现的范例。
加载器如何处理 eBPF Map 定义
其实,上面还存在一些疑问没有被解答,我最想知道的,就是 bpftool 为啥汰换了 eBPF Map 定义,并且新版本的接口为什么一定要有调试信息,才能正确加载 eBPF Map。首先,我知道了 nginx 为什么没有在 eBPF 程序里面详细定义 eBPF Map 的细节,比如 Map 的具体类型,以及 key value 的类型。因为 nginx 自己实现的是一个简单专用的 eBPF 字节码加载器,所以 Map 定义被写死在了 nginx 的启动代码里面,根本不需要在 eBPF 程序里面定义。
所以,我只需要研究 eBPF 相关加载工具或者库是怎么处理 eBPF Map 定义的,就能搞清楚这些问题。而搞清楚这些的办法很简单,其实就是看 Map 的定义信息是存放在哪里,以及是如何被消费的。考虑到我一直在学习 Rust,那我就结合 aya-obj 的实现,来聊一聊具体是怎么操作的。首先是 struct bpf_map_def 老版本的定义,通过 SEC 宏都定义在了 maps 段里面,所以加载器只需要去读取该段,然后就知道了自己需要构造什么样的 eBPF Map。aya 源码里面去读取了 maps 段内容,并且会按照符号表的格式进行解析,而这里会去依次解析出 struct bpf_map_def 的定义内容,所以加载器就知道应该创建什么类型的 eBPF Map 以及里面的键值类型。
但这里面,有一个实现不太好的地方,就是 bpf_map_def 中的 value_size 和 key_size 成员变量里面存储的是 Map key 和 value 的类型大小,这意味着加载器没办法做类型检查,如果在 Map 创建和使用的时候,键值有类型不对应的情况,编译时候也无法提示使用者。甚至 eBPF verifier 都无法提示报错,因为 verifier 只检查内存使用情况,如果 Map 定义的 key 类型大小是 4 字节,这个时候使用 Map 传入的 8 字节 key,那应该只会被截断,特别是用户态增删查改 Map 的时候,更是没有任何防范了。为了确保我理解正确,我特意测试了一下,确实能够顺利加载这样错误的 eBPF 字节码,clang 和 eBPF verifier 安静如鸡。
最后,可以看到下面新版的 Map 定义,是能够解决这个问题的。首先对 section 的不同命名,确保了加载器可以知道应该按照什么方式来解析 Map 定义,.maps 段名称肯定是最新版的 Map 定义。接着使用了 __type 宏,通过用类型定义来明确 key 和 value,这样的话,上面的问题就会得到缓解。但是,这里有一个问题,就是加载器该如何知道 Map 定义呢,正常来说,如果有 Dwarf 格式的调试信息,这里面是会有 Map 里面成员结构的具体定义。但是,eBPF 其实是更进一步,在 Dwarf 的基础上设计出了 BTF,更为精简,基本只保留了类型和字段布局,所以对于 Map 定义的表达是绰绰有余的。而 eBPF 加载器都会依赖 BTF 去识别新 Map 定义的具体细节,比如说可以参考 aya-obj 源码这里。对了,BTF 其实还有更重要的作用,也就是 CO-RE ,这里不详细展开了,如果哪天我积累了足够有趣的素材,我再开一篇博客分享下我的学习成果。
struct {
__uint(type, BPF_MAP_TYPE_SOCKHASH);
__uint(max_entries, 1024);
__type(key, __u64);
__type(value, __u64);
} ngx_quic_sockmap SEC(".maps");
我当时忍不住手痒,还用 c 语言实现一个简单的 eBPF 加载程序,把最简单一句 bpf_trace_printk eBPF 程序,给加载到 Reuseport hook 点上,大家如果觉得上面 nginx 的代码复现起来太费劲,可以参考我这个代码。
继续排查 nginx 热更新问题
到这里,eBPF 程序里面我感兴趣的地方都轻松的加上了日志,于是我开始尝试复现。继续用 curl 命令去给正在处于热更新状态的 nginx 打 HTTP/3 请求。从下面的 eBPF 日志输出,我们可以看到,curl 发出新请求的 QUIC 握手包,都没有命中 nginx eBPF 程序中的 Map,最后都是走了内核默认的四元组哈希匹配查找。而老进程的 Reuseport UDP 套接字还没有关闭,所以也会有机会处理到该数据包。
sudo cat /sys/kernel/debug/tracing/trace_pipe
bpf_trace_printk: nginx quic default route for key 0xbcf02d56a2dd29ef
bpf_trace_printk: nginx quic default route for key 0xbcf02d56a2dd29ef
bpf_trace_printk: nginx quic default route for key 0x21bddac2ce121be5
bpf_trace_printk: nginx quic default route for key 0x21bddac2ce121be5
我们再看抓包的情况,首先,可以看到 curl 发出两个 QUIC 握手包。为什么是两个握手包,这里倒不是重传之类的,是握手包比较大,默认的 1200 字节无法携带完毕,可以从 frame_type 列中看出,第一个握手包值是 6,即只携带了 QUIC crypto frame,而第二个握手包值是 6,0,还携带了 QUIC Padding frame,所以两个握手包不是相同的。接着,可以看到第三行第四行是 nginx 回应前两个握手报文,又从 long.packet_type 数值 3 可以知道,这两个回应报文是 QUIC Retry Packet,由于我们在 nginx 配置里面打开了 QUIC Retry 功能,这也是符合预期的。另外从 nginx 日志中,可以确认 curl 新发出的请求是被 nginx 老进程处理并且回绝了,那为什么我的 curl 显示我请求成功了。
sudo tshark -i any -Y quic -T fields \
-e frame.number -e frame.len \
-e ip.src -e udp.srcport \
-e ip.dst -e udp.dstport \
-e quic.dcid \
-e quic.frame_type -e quic.long.packet_type
286 1244 127.0.0.1 56477 127.0.0.1 1984 bcf02d56a2dd29ef 6 0
287 1244 127.0.0.1 56477 127.0.0.1 1984 bcf02d56a2dd29ef 6,0 0
288 153 127.0.0.1 1984 127.0.0.1 56477 3
289 153 127.0.0.1 1984 127.0.0.1 56477 3
290 1244 127.0.0.1 56477 127.0.0.1 1984 21bddac2ce121be5f1644d62b3183f08c8286ebc 6 0
291 1244 127.0.0.1 56477 127.0.0.1 1984 21bddac2ce121be5f1644d62b3183f08c8286ebc 6,0 0
292 165 127.0.0.1 1984 127.0.0.1 56477 3
293 165 127.0.0.1 1984 127.0.0.1 56477 3
于是我又回过头去看 curl 的命令输出,硕大的 HTTP/2 字样展示在输出上,嗯,原来 curl 会快速降级请求尝试,我应该使用 --http3-only 选项,大写的尴尬😓。
./curl -v -i -sS -k --http3 --connect-timeout 30000 --max-time 300000 https://127.0.0.1:1984/t
* Trying 127.0.0.1:1984...
* Trying 127.0.0.1:1984...
* ALPN: curl offers h2,http/1.1
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (IN), TLS change cipher, Change cipher spec (1):
* TLSv1.3 (IN), TLS handshake, Encrypted Extensions (8):
* TLSv1.3 (IN), TLS handshake, Certificate (11):
* TLSv1.3 (IN), TLS handshake, CERT verify (15):
* TLSv1.3 (IN), TLS handshake, Finished (20):
* TLSv1.3 (OUT), TLS change cipher, Change cipher spec (1):
* TLSv1.3 (OUT), TLS handshake, Finished (20):
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384 / X25519MLKEM768 / RSASSA-PSS
* ALPN: server accepted h2
* Server certificate:
* subject: CN=localhost
* start date: Nov 5 06:54:15 2021 GMT
* expire date: Jan 4 06:54:15 2041 GMT
* issuer: CN=localhost
* SSL certificate verify result: self-signed certificate (18), continuing anyway.
* Certificate level 0: Public key type RSA (4096/152 Bits/secBits), signed using sha256WithRSAEncryption
* Connected to 127.0.0.1 (127.0.0.1) port 1984
* using HTTP/2
* [HTTP/2] [1] OPENED stream for https://127.0.0.1:1984/t
* [HTTP/2] [1] [:method: GET]
向社区反馈问题
既然 nginx eBPF 程序实现有缺陷,热更新情况下,会导致相当一部分比例的新请求失败。于是乎,我当时就发了邮件给了 nginx 开发组(当时 nginx 还没有迁到 github 上面)。这是我发过去的邮件内容,我主要反馈了这个问题的严重性,至少在我眼中是有点不太能够接受的,如果不开启 quic_retry 配置的话,非常多的新请求只能通过超时来重试,我觉得在高要求的生产环境,可以说是故障了。
很快就有大佬回复了我的邮件,我定睛一看,名字有点熟悉,再一查,发现是 ngx-rtmp 的作者,瞬间有点激动,要知道中国直播绝大部分流量都跑在 ngx-rtmp 上面,而且这个 nginx 模块写的特别吊,我之前在上面学到了挺多东西的。大佬不愧是大佬,反手甩了我两个 patch,一个是基于 eBPF 的优化方案,一个是我之前博客提到的 Established-over-unconnected 方案。
我也蛮开心的分享了 Established-over-unconnected 方案在 Linux 上会遇到的核心问题: 哈希表查询性能退化。大佬直接高屋建瓴的来了一句:Apparently current UDP stack is just not made for client sockets,并且还指出了 eBPF 的一个痛点,即需要特殊权限才能运行(我个人觉得还好,并不是我的痛点)。
如何优化修复
现在就开始分析大佬给的 eBPF 程序优化补丁,其实我觉得这个问题修复起来挺简单的。因为问题本质是,在 nginx 新老进程都存在的情况下,以 nginx eBPF 程序目前的实现,新请求注定是无法命中 eBPF Map 的,因为新请求只有在握手阶段协商了新的 Connection id,并且 Connection id 中设置了正确的 socket cookie,才能命中 eBPF Map。所以,新的请求注定要按照 UDP 四元组进行哈希,走内核 Reuseport Group 查找逻辑。
那解决办法就很清晰了,既然内核默认逻辑会导致新的请求还打到老的进程上面,那么就得在 eBPF 程序里面下功夫,让新请求也不会走到内核默认查找逻辑。那么我们可以在 eBPF 里面再维护一个新的 Map,专门是处理新请求的,即把内核 Reuseport Group 哈希查找逻辑,在 eBPF 程序里面重新实现一遍。这样的话,当 nginx 发生热更新,新老进程同时存在,我们就可以很轻松的把老进程里面负责处理新请求的套接字从这个新的 Map 里面剔除掉。
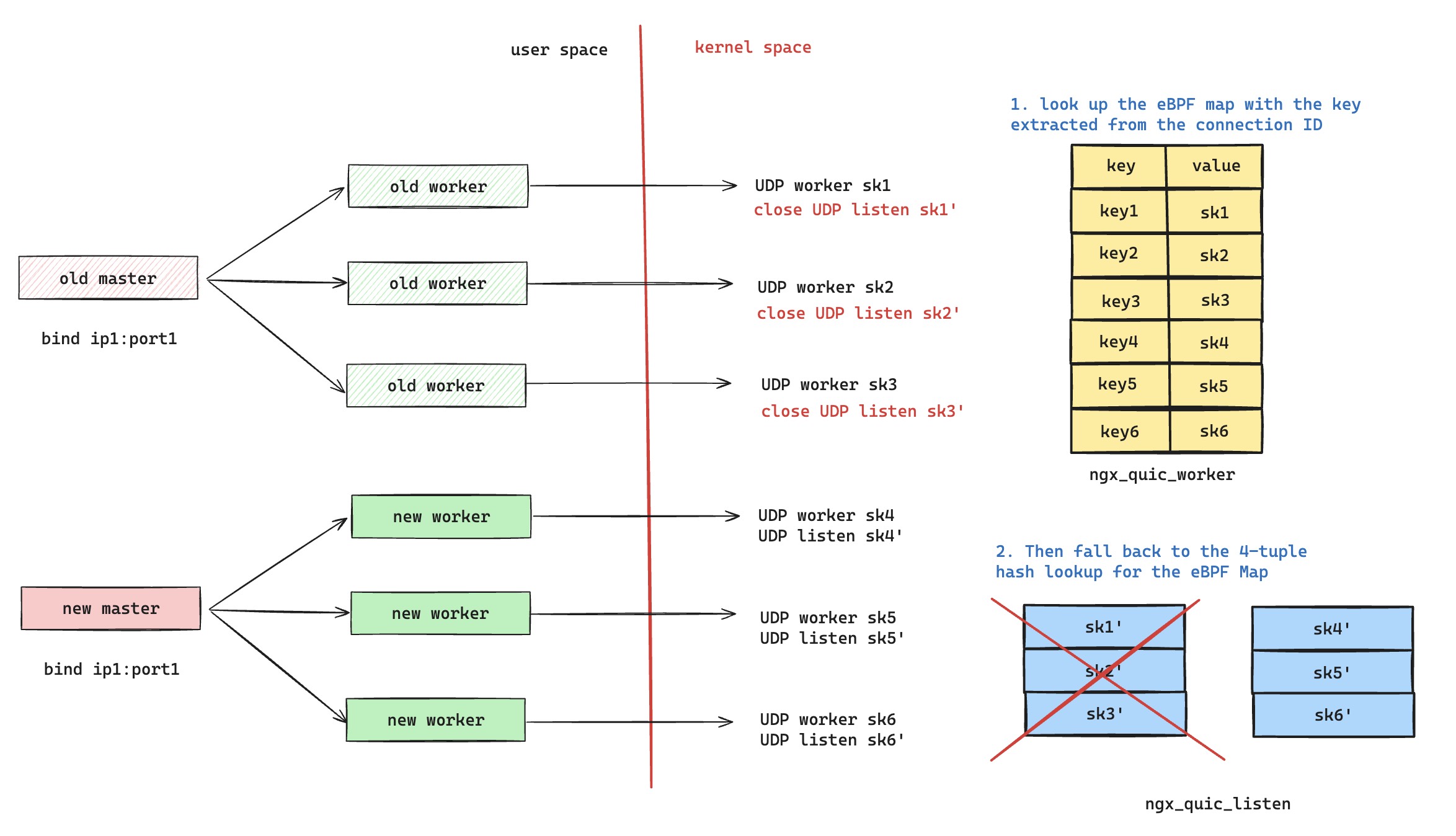
在 Roman 的 patch 里面,把 UDP 套接字分成了两套,就按照上面所说的那样,一套存放在 ngx_quic_listen Map 里面,负责监听处理新请求。另外,一套存放在 ngx_quic_worker Map 里面,负责处理已建联请求,这样的话,热更新时候,老进程把存放在 ngx_quic_listen 的套接字都删除掉,这样老进程就不会接收到新请求,而 ngx_quic_worker 里面的套接字还保留着,所以老请求也不会受到影响。
一切看上去都很美好,但是唯一让我蛋疼的是,直到今天,2025 年 8 月 21 号,这个 eBPF 修复 patch 居然还没有被合并到 nginx 主线里面。
目前 nginx HTTP/3 推荐配置
针对 nginx 1.27.2 以及之前的版本(宽泛点说,1.29.1 之前的版本,我没测试过最近的,但是代码上看起来变化不大),这里我简单给一下配置要领:
- listen option 中 reuseport 必须打开,如果不开,多进程情况下,QUIC 请求服务都可能会出现问题
quic_ebpf on;配置推荐打开,如果不打开,QUIC 连接迁移功能会存在问题,另外在热更新的情况下,老的请求会被动断流。(补充说明,目前 nginx 实现是一旦发生热更新,原有的 HTTP/3 请求都会因为自身被设置了 idle 状态而被销毁掉,具体逻辑在这里以及这里,不知道后续什么时候会优化)quic_retry on;配置推荐打开,如果不打开,热更新的情况下,nginx 老请求会。(补充说明:这个配置会导致常规请求的 QUIC 握手新增一个 RTT 的开销,但是对于公开的服务端来说,其实还是蛮刚需的,这里涉及的 trade-off 我在之前博客的 QUIC Retry 小节也有一些分析)
复盘
上面回顾了我两年前的学习 nginx eBPF 实现的过程,这里面我其实花了不少时间,左试右试,才最后找到答案。所以,接下来我就再复盘下我的排查过程,犯了哪些错误。
首先是问题的根源,curl 有降级重试机制,导致我没有复现出我预期中的问题。这个其实我得反思,但凡我认真看一眼 curl 的输出日志,或者去仔细翻一翻 nginx 的错误日志,甚至去抓一下包,都不会出现这样的误判。
另外,就是我在 eBPF 错误日志加载失败这件事情上,花费了太久的时间。正常来说,当你排查一个问题 A 过程中,衍生出了问题 B,你是要权衡一下,解决问题 B 的代价是否值得,是不是必须解决问题 B 才能解决问题 A,排查过程中没察觉的精力分散是非常可怕,这也是很多时候,我们需要跳出细节的泥潭,全局看待问题。但在这里,由于整个排查都是我自娱自乐的学习过程,没有任何 deadline 的压力,所以精力分散完全不是问题,一步一步把问题研究明白,才是快乐的源泉。
最后,我在整个排查过程中,花了不少时间,但我并不觉得这些时间算是浪费了,学习这种东西,快即是慢,慢即是快。你想想,哪怕是快两年后,我依然可以很轻松的把当初踩坑经历给复现出来,甚至还能拉扯这么长的一篇博客,并且为我后续 eBPF 学习打下基础,这些努力其实一点都没有被白费,哈哈,我已经自我洗脑了🤪。
udpgrm 实现分析
其实写到这里,我应该就收尾了,这篇博客已经很臃肿了,但是我还是想一鼓作气,再分享下我关于 Cloudflare 刚刚开源的项目 udpgrm 的学习成果,这个项目通过 eBPF 来解决我这里一直在聊的 UDP 热更新问题,所以让我们看看 Cloudflare 是怎么解决这个问题的。
如何提供给开发者使用
我大概是今年五月份时候知道这个项目的,第一反应是震惊,没想到这个场景也能做成通用解决方案🤔?在看这个项目代码之前,我先想了一下,如果想抽成通用解决方案,那可能有哪些问题需要解决,并且尝试自己思考一下解决方案,这算是我阅读开源项目的主要乐趣之一了。
- UDP-Based 协议五花八门,依赖的连接标识符也不一样,这样的话,怎么在 eBPF 里面识别 UDP 报文属于哪个连接,并且更进一步判断应该交给 eBPF Map 里面哪个套接字处理呢?
- udpgrm 怎么管理这些 Reuseport UDP 套接字?难道这些套接字全部都是由 udpgrm 独自管理,那 udpgrm 怎么和各种 runtime 进行适配接入呢?另外 udpgrm 怎么识别这些 Reuseport 套接字是否是自己管理的呢?
第一个问题,我左想右想,都没想到好的解法,难道是规定一套统一的标准?比如说 QUIC 的 Connection ID 定义规范化?姑且不说设计上的安全性考虑,更直接的问题是使用者必须要强改自己使用的 QUIC 协议栈实现。另外,如果是其他 UDP-Based 协议又咋办呢。我赶快去翻了 udpgrm 文档和代码,发现 udpgrm 居然在 eBPF 里面实现了 cBPF 解释器。所以,问题迎刃而解,开发者可以自己编写 cbpf 字节码,去 UDP 报文里面自由读取自己存放的 cookie 值,这样就可以轻松完成上面 nginx eBPF 程序类似的效果了。
当发现 cBPF 解释器实现的时候,我是有点震撼的,不知道是不是我孤陋寡闻了,真的没想到可以这么解决问题。果然用可编程的方式给用户提供灵活度,永远是一个可行的方案。好奇点进去看了具体实现,毕竟解释器肯定是一个大的循环执行,eBPF 对循环代码可是卡的很死。这里 udpgrm 使用了 bpf_loop 来实现了循环,好吧,原来 eBPF 早就支持了有限循环。
第二个问题的话,我也没有想到特别好的方案,感觉得额外拿一个 eBPF Map 来专门记录 udpgrm 套接字的 cookie,但 udpgrm 是怎么标识一个 Reuseport UDP 套接字是属于自己的呢,会不会是按照 Reuseport Group 来划分的,只要是在这个 Group 内,就都算是自己人。好奇的去看了看 udpgrm 实现,原来 udpgrm 通过 BPF_PROG_TYPE_CGROUP_SOCKOPT 直接在 getsockopt 或 setsockopt 系统调用里面,设计了自定义的 option 选项,诸如 UDP_GRM_WORKING_GEN 等等。让用户可以对自己的 socket 显式通过 setsockopt 去设置 udpgrm 相关的功能配置。udpgrm eBPF 还通过 bpf_set_retval 来保证自定义的 option 选项不会对原有系统调用造成影响,同时还处理不少边缘场景。这个是我第一次知道有这样的操作,可能 cilium 这样的项目早就这么做了,因为我看相关 eBPF 支持很早就出现了,算我孤陋寡闻了,但是现在知道应该也不算太晚,以后有机会我自己项目也会这么使用。
除了应用程序自己去适配 udpgrm 的功能开启方式,udpgrm 还提供了 udpgrm_activate.py 来减轻使用者的工作量。使用者可以通过该 python 脚本参数来配置好要使用 udpgrm 的相关功能,Python 脚本会负责创建套接字,并且按照要求对套接字进行 setsockopt udpgrm 选项设置。紧接着,就是我们熟悉的父子进程套接字继承环节,udpgrm_activate.py 会通过 fork+exec 来启动用户的应用程序。所以用户的 Server 其实已经持有了脚本创建好的那些套接字。接着就是用户的 Server 怎么感知到这些套接字的文件描述符是多少,方法有很多,udpgrm 的示例程序里面,是直接去尝试打开 [3, 3+32] 区间的文件描述符,这是一个办法,但是不够精确。nginx 给了我们一个示范,父子进程可以通过环境变量的方式来传递这些文件描述符。所以用户的 Server 其实还是需要做一些适配工作,不过这些工作已经变得很简单了。
udpgrm 设计和使用细节
work generation
udpgrm 提出了一个概念 work generation,这个其实很好理解,毕竟 udpgrm 是要解决 UDP 热更新问题的,所以当前应用服务持有的 Reuseport UDP 套接字组和热更新后新服务持有的 Reuseport UDP 套接字组,虽然在内核层面都是同一个 Reuseport Group,但是对于 udpgrm eBPF 程序而言是不同的 work generation。我们可以拿上面的 nginx 热更新举例子,shutting down worker 持有的 Reuseport UDP 套接字是上一代的 work generation,而新生成的 worker 持有的自然是新一代的 work generation。大家如果不理解,可以仔细参考上面文档链接的图片,我本来想画一张图在这里的,但是我发现文档里那张图画的非常精髓,我就不画蛇添足了。
接着我们看一看,使用者应该具体怎么创建 work generation,特别是不同代的 work generation 套接字。这个倒也是简单,每个套接字在使用 setsockopt 的 UDP_GRM_WORKING_GEN 选项时候,都可以设置自己的 work generation id,并且还可以通过 getsockopt 来获取当前 work generation 的 id。而 setsockopt eBPF 程序会通过 ringbuf 把注册情况发送给 udpgrm 后台 demon 服务,后台服务有专门的逻辑负责把这个套接字给 update 到对应的 eBPF Map 里面。接下来就是 udpgrm 的 BPF_PROG_TYPE_SK_REUSEPORT 程序怎么处理 UDP 数据包,并且分发给对应的 work generation 了,如果 work generation 中有多个套接字,也要确保负载均衡。
udpgrm 模式
接下来聊一聊 udpgrm 几种模式的实现细节
DISSECTOR_FLOW 模式
这个模式我个人不太喜欢,感觉有几个缺陷。第一个缺点的话,就是使用了 UDP 四元组信息作为哈希表的查询关键字,这么做的话,意味着 UDP-Based 协议和 UDP 四元组绑死了,另外还意味着没办法支持高并发量,因为 eBPF Map 大小都是有上限的,我们之前也聊过这个话题了。第二个缺点的话,就是使用了三元哈希(3-tuple hash of {remote IP, remote port, reuseport group ID}),个人感觉碰撞的概率又大了不少。没有使用本端 ip 和 port 的原因,是 sendmsg 的 eBPF 程序里面无法感知到这些信息。
至于为什么使用 sendmsg eBPF 程序,这是因为 eBPF Map 里面成员需要有一个淘汰机制。虽然 udpgrm 里面使用了 BPF_MAP_TYPE_LRU_HASH 类型的 Map,如果 Map 打满了,会按照 LRU 语义来更新。但是,如果我们有一个生命周期超时销毁机制,应该会更好一些,均摊了销毁的操作成本。这个生命周期超时机制,就是对应的连接有没有发送 UDP 数据包,全部都在 sendmsg eBPF 程序里面维护。另外,sendmsg eBPF 程序还负责在 lru_map 的插入,这意味着只有服务端回应了客户端的握手包,udpgrm lru_map 才会记录这个 flow。这样的实现也减少了不必要的开销,尽量减轻了 lru_map 的负担。
第二个缺点引申出来的问题,udpgrm 文档也说的很明白了,会出现哈希碰撞的情况。虽然 lru_map 哈希表查询的关键字大小是 4 字节,文档里面说会存在 1 / 524288 的机会发生哈希碰撞。这个倒是很好理解,三元哈希生成 4 字节哈希值一致的概率是 1 / 2^32,8192 个并发的 flow 同时存在,也就是碰撞概率是 8192 / 2^32,即 1 / 524288。发生哈希碰撞的后果,就是新的请求也可能被误认为是老的请求,那么就会有概率被分配的旧的服务上,所以文档反复强调了一件事情:an application should be capable of accepting new flows even in draining mode,如果支持的话,只是老的服务退出慢一些。但是遗憾的是,很多服务不一定支持这一点,比如说 nginx 的 shutting down worker 就不会继续处理新的 HTTP/3 请求。
那有没有优点呢,我觉得优点就是这个模式非常简单易用,不需要对 UDP-Based 传输协议做额外的开发,比如说把套接字 cookie 放在自己的连接标识符上,更不用说去写蛋疼的 cBPF 字节码去 UDP Payload 里面提取 cookie 了。
DISSECTOR_CBPF 模式
所以,我们接着看看 cBPF 模式是怎么使用的,这里面实现细节我觉得已经基本没什么好说的了,我翻了翻代码,发现除了 cBPF 外,其余基本和 nginx 的 eBPF 优化补丁实现基本大同小异,都是要确保所有的请求都会被 Reuseport eBPF 程序处理掉,不要跑到默认的内核四元组哈希分配逻辑。
不过有一个挺有意思的地方,就是 cBPF 自定义字节码只需要读取的一个 2 字节的数据,而套接字的 cookie 则是 8 个字节,这里其实是 udpgrm 额外维护了一个二维 u64 数组,这个二维数组就负责存放 cookie。而在 2 字节数据里面有这个数组里面的具体索引,可以快速在 eBPF 程序里面查找到对应的套接字 cookie 是什么。查到 cookie,就可以找到是哪一个套接字应该服务这个 flow 了。
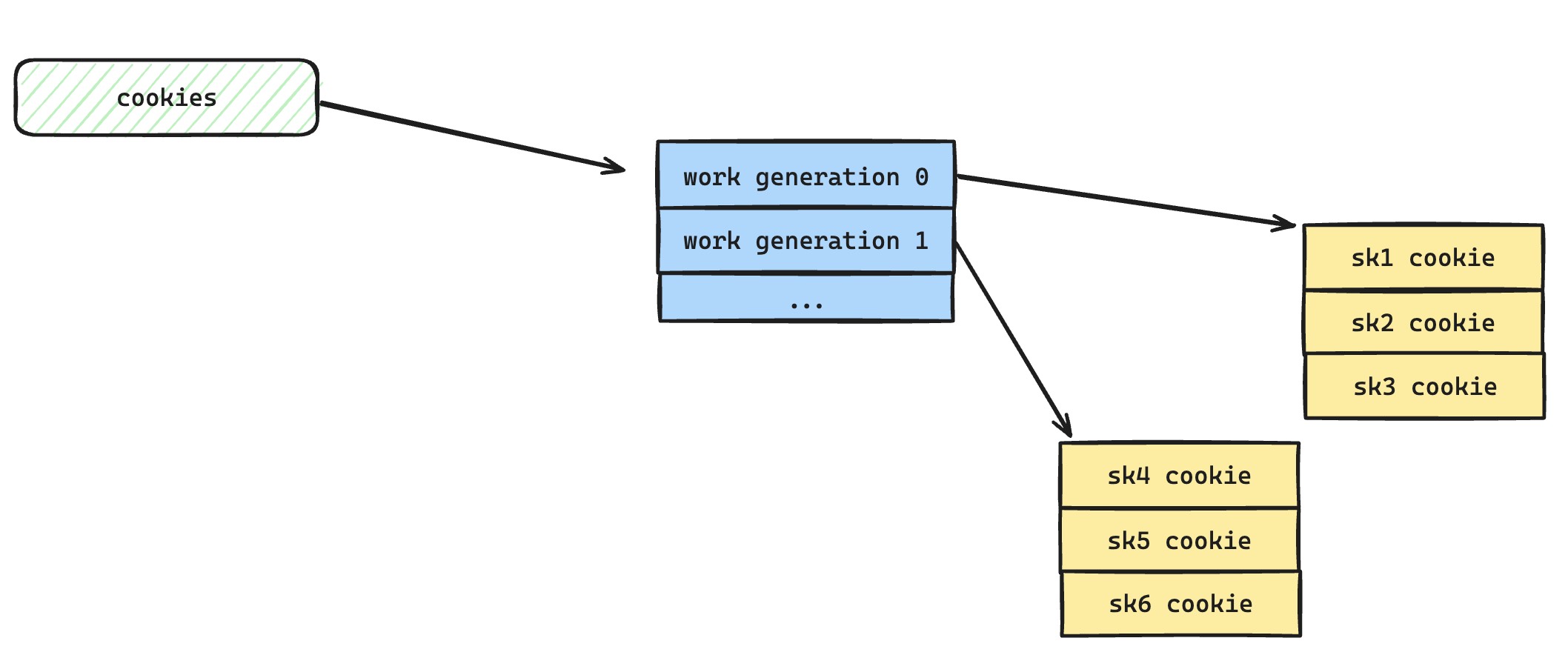
这里还可以再细说一下,2 字节里面存放了非常多的信息,具体解析逻辑在这里,不仅仅存放了 work generation id 信息,还存放了在特定 work generation 对应 cookie 数组里面具体的索引。更重要的是,还有一个很关键的实现,通过校验和方式来确认这 2 字节数据是否是符合 udpgrm 自定义规范的,如果不是,则说明基本是 new flow,即新请求。
然后,我们再关注一下 new flow 是怎么处理的,这里也非常关键,因为关乎到会不会犯了目前 nginx eBPF 程序所犯的错误,把新请求分配给了老的服务。udpgrm 代码在这里会进行判断,当前最新的 work generation id 是多少,然后当前 work generation 的套接字有多少个,然后根据 UDP 四元组哈希负载均衡选择当前 work generation 里面合适的套接字进行处理绑定。
说实话,我觉得 udpgrm 的 DISSECTOR_CBPF 模式实现比 nginx eBPF 优化补丁实现还要好一些。我觉得主要是归功于 work generation 概念的提出,瞬间很多东西都清晰了起来,果然大佬还是厉害,随便一出手,就不同凡响。
Application selection
udpgrm 还提供了一个更细分的维度,应用程序维度选择,这个非常酷炫。我从来没有思考过这个场景,当然我不会妄自菲薄😏,因为这个一看就是特定业务需求迭代出来的产物。更具体的来说,是同一台机器上在相同的监听地址和端口背后,可能存在多个应用服务,这个时候如果在 eBPF 程序里面就能区分清楚,当前这个 UDP 数据报到底应该由哪个应用服务,把 UDP 数据报指定到对应应用服务持有的套接字上面,岂不是美滋滋。
具体怎么判断 UDP 报文属于哪一个应用,这里就得应用程序自己在 UDP 报文里面加私货了,然后自己写 cbpf 字节码去自定义解析了。不过 udpgrm 给了一个示例(DISSECTOR_BESPOKE 模式),通过 TLS 协议里面 client hello 携带的 SNI 扩展来判断,其实就是我们熟悉的请求域名。这里我想聊一下具体实现细节,DISSECTOR_BESPOKE 示例是专门针对了 QUIC 握手报文进行 TLS SNI 提取。我们都知道 QUIC 融合了 TLS 1.3 协议,但是当我看到 eBPF 程序里面,对 QUIC 握手报文做了相关解析,我还是蛮吃惊的,因为没想到 eBPF 里面啥都能套进去,酷!
不过我还是想挑挑刺,这个 QUIC 解析只会对 QUIC Initial Packet 生效,当然了,其他空间的 QUIC Packet 它也解密不出来。但是解析逻辑里面预设了 QUIC Initial 空间的首个 UDP 数据报一定会携带 TLS SNI 扩展。如果说,我的 Client Hello 足够的大,里面有很多乌七八糟的扩展,导致 QUIC 握手包需要放到两个 UDP 数据报中发送,而 TLS SNI 扩展在第二个 UDP 数据报,那么这个解析器应该就没办法用了(没有缓冲区来应对 Crypto 的可靠字节流)。当然,实际生产环境是不太可能出现这种情况的,更何况 QUIC 握手包强制最低 1200 字节,不是故意搞事情,是不会出现上面这种问题的。
螺蛳壳里做道场
之前看过 parce 的代码,在 eBPF 里面实现了对用户态进程的栈回溯,甚至还支持一些虚拟机语言比如 Python、Ruby 啥的。这回又在 udpgrm 里面看到了 cbpf 解释器以及 QUIC 握手包解析(包括 AES128 和 SHA256 安全算法)在 eBPF 里面的实现。这让我不得不感叹 eBPF 潜力无穷,好的项目层出不穷,根本学不完,正所谓螺蛳壳里做道场,艺高人胆大。
最后,本节对 udpgrm 项目的分析就到此为止,可能还不够深入,但是考虑到这个项目刚出现,也没多少人知道,相信这篇博客应该是为数不多的中文资料了。我大概只花了几个晚上读完了 udpgrm 源码,个人收获还是蛮多的,如果有理解疏漏的地方,大家随时指出。后续的话,可能只有当我有机会做相关项目的时候,才会回来通过抄作业或者说是借鉴的方式来继续看 udpgrm 了。
尾声
其实这篇博客也是我一个暗线系列的结尾,当然是我 eBPF 自我学习系列的开端。这个暗线系列主要聊了 Linux 下 UDP 网络编程中的一些痛点,还包括之前的两篇文章:用 Rust 从零开始写 QUIC:实现连接迁移和 Linux 服务端 UDP 网络编程:无损热更新。其实,好的文章应该详略得当,我这里这几篇博客写的特别臃肿,并且前后关联比较紧密,还需要大量的背景知识理解,但我就那么写了,而且还挺满意的,毕竟主要是对我好几年前踩坑经历的一次完整总结,对我而言,能把脑海里残存的记忆还算有逻辑的写出来已经算是成功了。