Linux 服务端 UDP 网络编程:无损热更新
从当年的一个紧急需求说起
事情起因
大概是在四五年前,我接手了一个非常紧急的功能需求。具体情况的话,是要在一周时间内,给当时线上基于 UDP-Based 传输层协议做分发的 nginx 流媒体服务器实现无损热更新功能。更确切的说,我需要在几天时间内快速完成这个复杂功能的设计、开发、回归测试以及上线灰度。
相信有人看到这,已经开始皱眉头了(地铁老人.JPG),灵魂拷问随即涌现,为什么要那么在那么短时间去做这件事情,功能的质量能得到保证吗?只能说,工作中有很多项目,他们存在的意义和 timing 是绑死的,也就是说如果这些项目做的慢了,哪怕只慢了一天,可能就算是错过了机会,项目也失去了他们原有的价值(这里我只是在陈述一个事实,不代表我个人观点😂)。至于这个复杂功能,我为什么敢接这个军令状,自然是以前接手 TCP 流媒体热更新功能时积累的经验,让我信心满满,觉得又是个秀的机会,冲就完事了。
可惜的是,当我快马加鞭的完成了功能设计和开发,突然在回归测试环节卡死住了。在我有一台测试机器上,无损热更新功能运行不符合预期,但是在预发环境却没有问题。我记得当时时间已经过了一大半,再过一天就是最后一个发布窗口了,如果错过,那意味着我在这个项目上失败了。其实,很多时候,项目成功与否都是和非技术因素,以及后续功能稳定性有比较大的关系,真的很难遇到因为技术实现细节导致项目推进失败的情况。而我当时正是搬砖渐入佳境的时候,更无法接受这样的失败。
在头昏脑涨的排查了一晚上之后,我还是没有一个特别清晰的结论,既然功能可能存在隐患,肯定不能稀里糊涂的上线,但是发布窗口就在明天,我应该怎么办。嘿嘿,我从来不迷信个人英雄主义,团队里面那么多大哥,我肯定不能一个人蒙头瞎搞。我当时直接拉了个紧急会议,刷脸硬是把我熟悉的几位大佬都拉到了会议了,并且很“无耻”的表示,我们会议里面直接现场开始问题排查,如果没有一个结果,我是不会把会议结束掉的,请大家做好心理准备。
结果,就在我详细介绍完功能背景以及我当前遇到的问题时,突然有个大哥打断了我,问我有问题的测试机器 Linux 内核版本是多少。我当时很疑惑,我说这个怎么会和机器内核版本有什么关系,应该是我的锅,可不带甩给内核的。大哥嘿嘿一笑,跟我说,关系可大了。果然,出现问题的机器内核版本清一色都是 4.19,而没复现出问题的机器内核版本是 3.10 版本。大哥跟我说,放心发布吧,我们线上是 3.10 版本,UDP 无损热更新功能不会有问题。
相信看到这里,大家可能还是对这个问题的细节是一头雾水,究竟什么是无损热更新,为啥基于 UDP 的传输协议在热更新场景能否正常工作,会和内核的版本有关联,UDP 网络编程究竟是什么样,以上问题我都会在下文中进行详细解答。而这篇博客其实是想进一步阐述上一篇博客里面介绍的一个难点,即:在多进程服务端架构下,如何确保 UDP 数据包被正确的匹配到连接会话所在的进程上,这也是 UDP 网络编程的一大难点。需要特别注意的是,如果是多线程的服务端进程,只要是出现热更新,即多个服务实例以不同进程的形式同时出现,都会面临这个问题。
nginx 无损热更新功能介绍
这里考虑到 nginx 相关资料特别多,并且官方文档也写的非常详细,我就说一下这里需要特别关注的地方。即 nginx 热更新时候,不管是 reload 还是 upgrade,本质上都生成了新的进程来继续服务新请求,而老进程会开始关闭负责监听的套接字,只服务热更新之前的老请求,直到所有老请求正常结束或者达到优雅退出等待时长后,再进行退出。
那这套官方方案又存在什么样的使用局限呢,正常来说,nginx 都是作为反向代理来使用,即请求都被代理到了后端源服务器,nginx 把源服务器的响应转发给原始请求。这么看,官方的热升级方案,并没有什么问题,每个请求打到 nginx 后都会独立发起对上游的请求,新老进程同时存在对所有请求都没有影响。但如果 nginx 本身就是源服务器呢,像 nginx 开发的三方模块就有这样的情况,比如说大名鼎鼎的 nginx-rtmp 流媒体模块,因为流式分发数据,就是存在生产者和消费者的情况。如果发生了热更新,生产者在优雅退出的老进程上,那么后来的请求,是无法命中老进程上的生产者的。
基于 TCP 多进程架构的无损热更新实现
面对这样的问题,解法其实很直观,就是让打到新进程的新请求也能访问到老进程上面的生产者,更确切地说,是想办法把老进程上面的生产者挪到新进程上面。我们当初考虑了两套实现方案,最早想到的第一套方案有点 tricky,采用了进程之间传递文件描述符的方案(该技术细节会在下文再聊),将生产者的文件描述符以及会话状态核心信息传递到新进程,然后新进程重新构建生产者的会话,确保能够正常服务新的请求。但是这里,最大的问题,就是版本发布可能导致会话构建特别脆弱,给后面的功能迭代、维护带来相当大的困难。
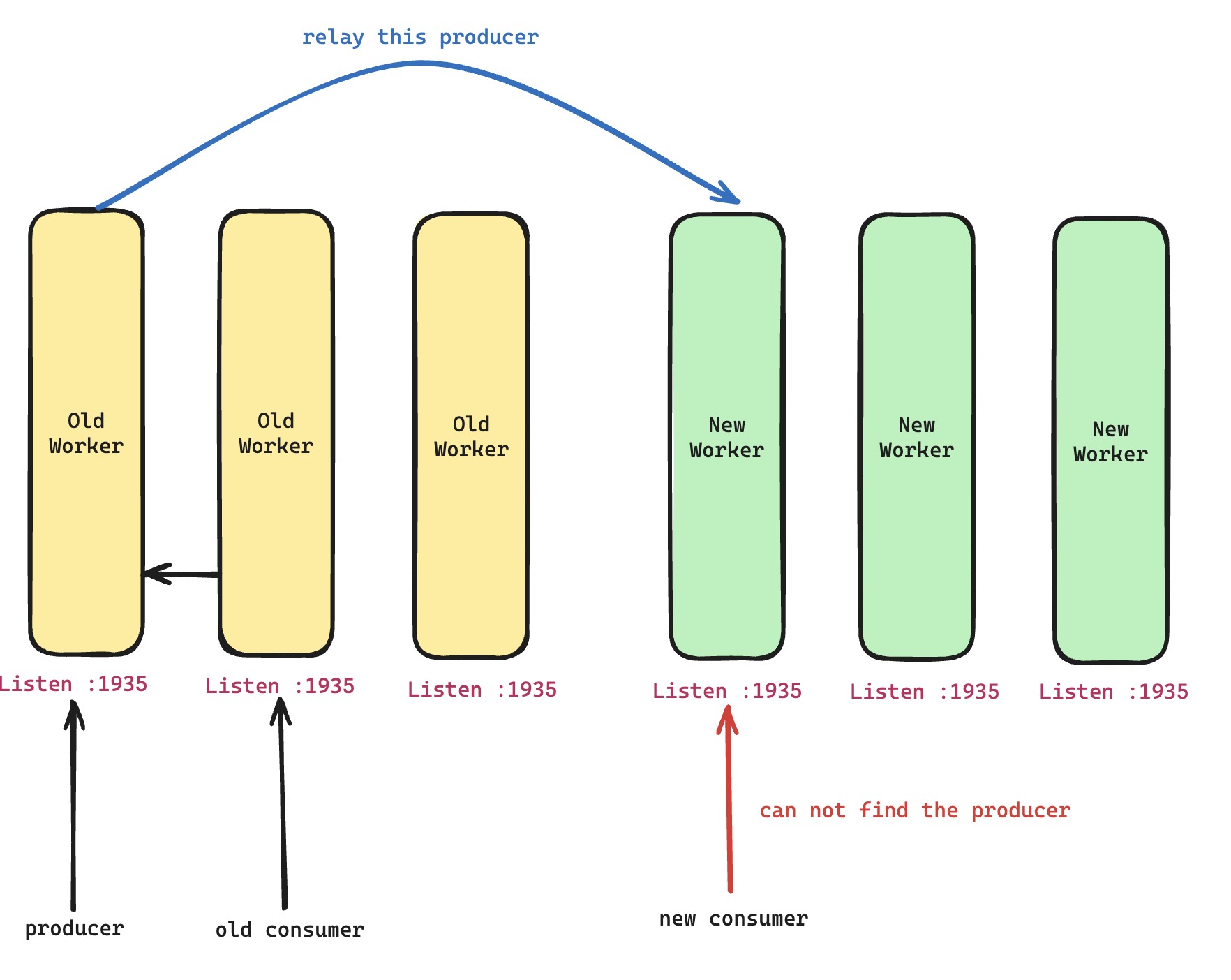
所以,我们很快就切到的第二套方案,即如上图所示的那样,让生产者将实时数据再转发一份到新进程上面去,然后新进程就相当于有自己的生产者来服务新请求了。看起来朴实无华的技术方案,却非常好用,确实有时候回想一下,平平淡淡才是真。
对于 TCP 来说,上面说了,老进程把负责监听的 TCP 套接字给关闭掉,其实就相当于不再接收新请求,然后再主动对新进程监听地址发起转发请求。但对于 UDP 来说,甚至没有负责监听 UDP 套接字的概念,很多实现里面,哪怕是多个 UDP-Based 传输协议的连接,都是一个 UDP 套接字打天下,那么这里就存在两个问题。
- 那正常来说服务端 UDP 套接字编程应该是怎么样的,特别是多进程的架构下,怎么确保进程持有的无连接状态 UDP 套接字能够获取到属于自己进程上 UDP-Based 传输协议连接会话的数据包。
- UDP 服务器的老进程想确保拒绝新的请求,同时又不影响当前正在服务的老请求,即 UDP-Based 的传输协议怎么实现 nginx 正常的热更新功能。只有这个基础核心功能支持完毕,才能再谈及去支持新的无损热更新方案。
UDP 套接字网络编程
铺垫了这么多,现在我们来看看 UDP 套接字究竟应该怎么使用,才能解决上面所说的那些问题
套接字背后是什么
Linux 有一个核心设计思想,一切皆文件,网络套接字本身在用户态只是以文件描述符的形式存在,即一个无符号整数。但是,我们都很清楚,这个简简单单的文件描述符背后肯定关联复杂的传输层协议会话状态,特别是 TCP 套接字。毕竟我们用 Rust 写 feather-quic 玩具项目还写了那么久,都晓得一个真正久经考验的传输层协议栈有多么复杂。
那么我们就初步看一下,内核是怎么串联管理套接字背后的状态的。还是那句话,我自己并不是内核态开发者,只是偶尔翻一翻,所以理解可能有一些偏差。首先,进程用户态的文件描述符可以关联到进程本身持有的文件数组。而网络套接字在文件结构体中对应的是 struct socket,这个结构体对我而言,意味着是内核的套接字层的实现,里面核心成员 sk 对应的才是真正的内核传输层会话状态 struct sock。
user space fd
↓ (task_struct->files_struct->fd_array[fd])
struct file
↓ (file->private_data)
struct socket → (socket->proto_ops)
↓ (socket->sk)
struct sock → (sock->proto)
参考上图的串联关系,我们简单的梳理出了网络套接字背后内核数据结构。而更关键的在于,struct socket 作为套接字层,持有了 proto_ops 回调数组。可以很清晰的看到,我们熟悉的网络套接字相关系统调用,在这里面都有涉及。像 TCP 套接字,注册在 proto_ops 里面的是 inet_stream_ops。而 UDP 套接字,注册在里面的是 inet_dgram_ops。其中可以很明显看出来,inet_dgram_ops 注册的回调少很多,像 listen 以及 accept 这种都是没有实现的,当然这也是符合逻辑的,UDP 套接字本来就不是面向连接的。
另外,如果细看这些注册回调的实现,其实很多都是直接再次调用了 struct sock 持有核心的回调数组 struct proto。我是这么理解的,struct socket 只是提供了一层抽象,让内核中各种 TCP、UDP 甚至包括 STCP 等一系列协议可以使用基本一致的套接字系统调用。而真正这些系统调用的核心实现,都是在内核各个传输层自己独立实现的回调中完成的,比如说 TCP 的 tcp_prot 以及 UDP 的 udp_prot。同理,struct sock 其实也是对各个传输层实现上下文数据结构的抽象,当然真正持有 TCP 协议栈上下文的是 struct tcp_sock ,这里其实是常见的 c 语言技巧,tcp_sock 首个成员实际上是 struct sock,形成了实际的组合关系,方便两者之间快速转换类型。
这里,我突然想到当年,有位大哥跟我说,如果真想学习内核态协议栈开发,可以试着把 KCP 给做进内核里面,虽然没有什么实际意义,但这是一个很好的练手项目。哈哈,很抱歉,我虽然曾经心动过好几次,但是一直没有付诸于行动😁。
Linux 内核中 TCP 面向连接实现
抛开 TCP 中的拥塞、流控、reliability 等核心特性不谈,我们光看看 Linux 内核中 TCP 是如何实现面向连接的。这里就不涉及 TCP 面向连接协议上的设计了,之前博客已经讨论过好几轮了。简单来说,大家都知道 TCP 是依赖四元组来区别独一无二的连接的。所以,我们接下来看看,内核 IP 网络层处理数据后,是怎么把 TCP 数据报文送到属于它所在连接的会话状态上的,即交给对应的 tcp_sock 来处理,然后再根据 TCP 协议栈处理结果看是否需要唤醒持有该 tcp_sock 的进程,对应的进程通过套接字读取数据,根据 UDP-Based 协议的连接标识符,交给对应的会话上下文来处理数据。
| 哈希表 | Key | Value | 匹配逻辑 |
|---|---|---|---|
established-hashtable | 本地 IP、本地端口、目的 IP、目的端口 | 建联成功的 socket(TCP_ESTABLISHED 及之后) | 四元组完全一致 |
bind-hashtable | 本地端口 | 所有绑定到该端口的 socket | 本地 IP 和本地端口组合一致 |
listening-hashtable | 本地端口 or 本地 IP 和本地端口组合 | 所有处于 TCP_LISTEN 状态的 socket | 本地 IP 和本地端口组合一致 |
这里的一切其实都是数据结构的设计,如上面的表格所示,TCP 内核协议栈维护了三张全局哈希表,来解决刚才我们说的问题,确保全局的 TCP 套接字状态不会互相冲突,内核 IP 网络层的数据也会被准确的送到对应的 tcp_sock。在详细解释这些细节之前,有一个值得关注点,就是这些全局哈希表全部存放在 inet_hashinfo 中,而 inet_hashinfo 是 struct net 持有的,这又涉及到了 Linux Network Namespaces 的设计实现,如果想实现网络层的隔离,那确实得各自维护这些核心的全局数据结构,不过这里不会进一步分析。
那现在我们看,传统的 TCP 客户端和服务端通信场景下,有哪些系统调用,需要使用到这些哈希表。首先,我们从服务端开始,大家熟悉的是,服务端会创建负责监听的套接字,然后会依次调用 bind 和 listen 系统调用,然后就老老实实的等待可读事件,然后去 accept 新请求,然后在新的套接字上进行读写通信。这里 bind 系统调用,会去查询 bind-hashtable,以确保本地 IP 和本地端口不会和其他 TCP 套接字发生冲突,想必大家也经常遇到执行 bind 时候发现端口或者 IP 地址冲突的错误,这里就是 bind-hashtable 在默默的发挥着作用。接着就是 listen 操作了,这里会把这个套接字加入到 listening-hashtable 里面去,这样的话,后面有新的流量打进来可以准确通知持有该监听套接字的进程。
再看 TCP 客户端一般会怎么做,创建好 TCP 套接字之后,直接开始 connect 服务端的目标地址和端口。这里,想必大家都晓得,TCP 的三次握手就是在 connect 系统调用中发起的,只有三次握手完成,内核才会根据独一无二的四元组,将已建连的 tcp_sock 塞到 established-hashtable 里面去。然而 connect 还会在握手之前,确定好当前 TCP 连接的四元组。由于服务端的目标 IP 地址和端口已经确定,所以这里就是完成类似 bind 系统调用的效果,给当前 TCP 套接字,锁定一个独一无二的本地端口和 IP 地址组合。一般来说 IP 地址是根据路由表查询,看服务端目标地址往哪走,选择合适的客户端 IP 地址。而关于本端端口的选择,也是依赖 bind-hashtable 来快速判断是否有冲突,来分配一个不冲突的本端地址和端口组合。这也是为什么作为客户端不需要自己去 bind 的原因,因为客户端是主动发起方,本来本地端口就不确定,如果让客户端自己来选择太过于麻烦,还是让内核代劳,通过 connect 分配一个不冲突的本地端口。
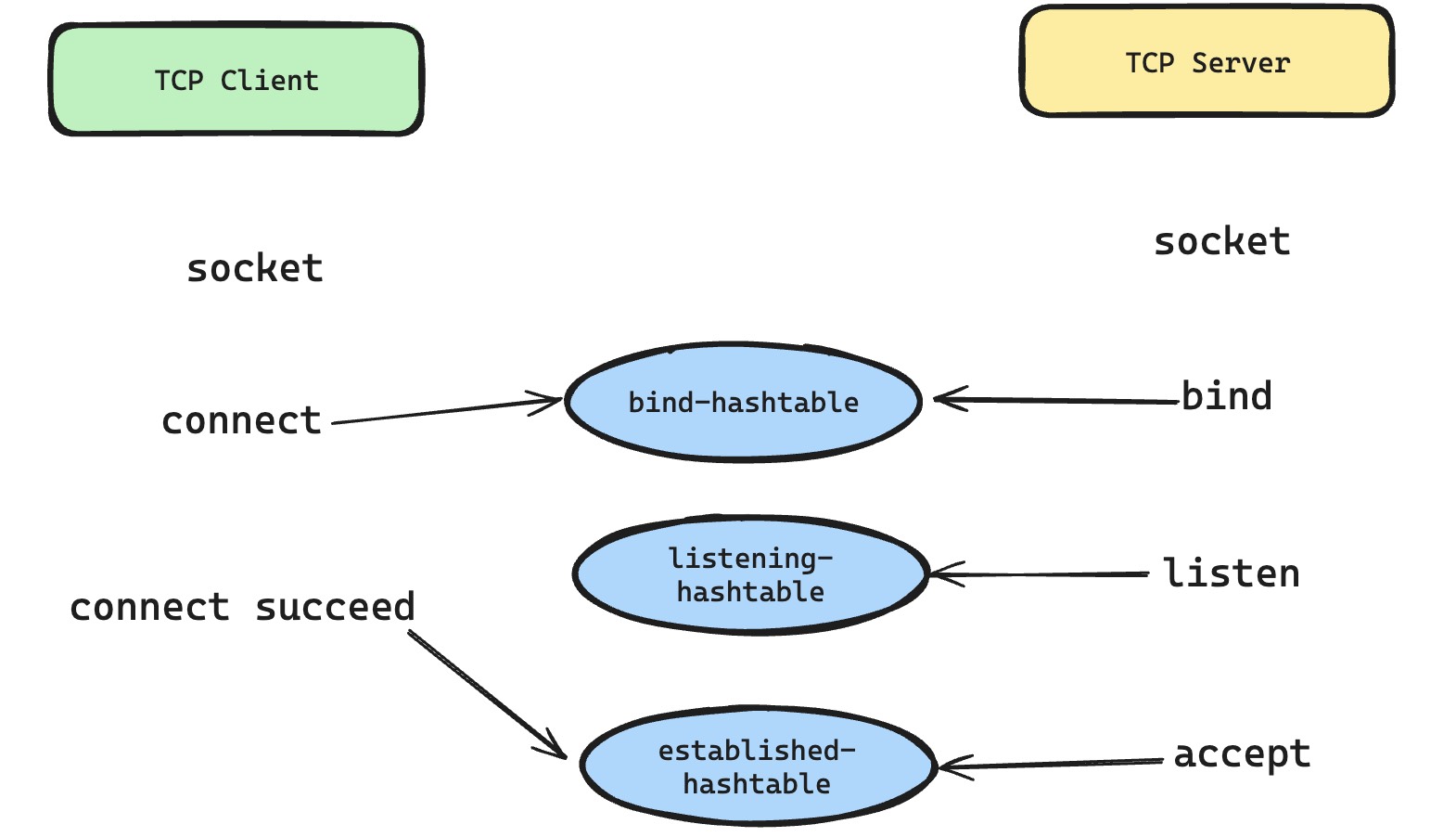
最后,就是内核在处理 IP 网络层抛上来的 tcp 数据包的逻辑,会首先去查询 established-hashtable,确认是否匹配已经建联成功的 TCP 会话。如果没查询成功,那么就在 listening-hashtable 中继续查找,来确认建联包是由哪个正在监听的套接字来处理。我在想,为啥是先查 established-hashtable,而不是先判断建联包,如果是建联包就去查 listening-hashtable。我理解可能是四元组查询效率更高,可以快速判断 TCP 报文是否属于某个连接,另外,如果连接已经建立,可能还有残留的握手包姗姗来迟,也能规避这种特殊情况的处理。
Established-over-unconnected
唠叨完了这些前置信息,我们终于可以开始讨论怎么基于无连接的 UDP 套接字,来支持有连接状态的 UDP-Based 传输协议实现了,特别是前文提到的热更新实现问题。首先,大家可以注意到这一小节的标题是 Established-over-unconnected,这个名字是我在 Cloudflare 博客里面看到的,不过这套技术实现方案,其实已经出现很久了,这里我就不考古了,因为我也不晓得到底哪位大佬先想出来的。
本质是在 UDP 套接字上面,模拟刚才我们聊到的 TCP 套接字中 listen、accept、connect 等系统调用,这些操作分别代表创建了负责监听的 UDP 套接字,服务端获取了新请求连接的 UDP 套接字以及客户端创建发起新请求的 UDP 套接字。这也意味着,不再是一个 UDP 套接字接收全部流量,然后根据 UDP-Based 协议自身连接标识符设计来区分连接会话,而是创建不同的 UDP 套接字来分别处理对应的流量数据。
还是一样,先从 UDP 套接字在内核的数据结构说起,在 struct sock 这层数据结构中,如果创建的是 UDP 套接字,那么实际数据结构是 udp_sock,这里可以看出 udp_sock 数据结果比 tcp_sock 精简很多,这是因为 UDP 不像 TCP 那样特供那么多特性。然后就是内核怎么管理这些 udp_sock 的,即怎么把 IP 网络层抛上来的 UDP 数据报匹配到对应持有 udp_sock 的进程套接字上。这里也是非常类似的实现,内核也维护了 UDP 的哈希表,只不过在 udp_table 这里没有了 listening-hashtable 和 established-hashtable 的踪迹,这是因为 UDP 设计上就没有面向连接这个说法,所以当然不需要了。所以,我们内核会根据 udp_table 来进行 udp_sock lookup,根据 UDP 数据报的四元组信息,将数据包匹配到正确的,或者我们希望的那一个对应 udp_sock 的 UDP 套接字上面去。
接下来,就是想办法让新建的 UDP 套接字,能够在这个 UDP 哈希表中有一席之地,就可以让该 UDP 套接字能够接收到自己想接收到特定 UDP 四元组的数据了。而我们可以使用 UDP 套接字的 bind 和 connect 系统调用,可以赋予 UDP 套接字背后 struct sock 四元组信息,这样的话,内核的 UDP 数据包匹配逻辑,就可以让新建的 UDP 套接字准确接收到特定 UDP 四元组的数据。特别提一嘴,UDP 套接字的 connect 系统调用,可没有像 TCP 套接字那样触发 TCP 三次握手,只是简简单单的分配了不会冲突的四元组信息。而针对想模拟出 TCP 监听套接字的效果,那就只需要 UDP 套接字去 bind 本地地址和端口,只要内核的查找逻辑是以四元组匹配优先,次优是本地二元组匹配,类似于 TCP 数据包分配的原则,那么整个流程就可以正常运转起来了。所以,具体的实现方案如下图所示, 我们可以清晰的看到 UDP 套接字是怎么模拟出 TCP 套接字中 listen、accept、connect 等系统调用的。
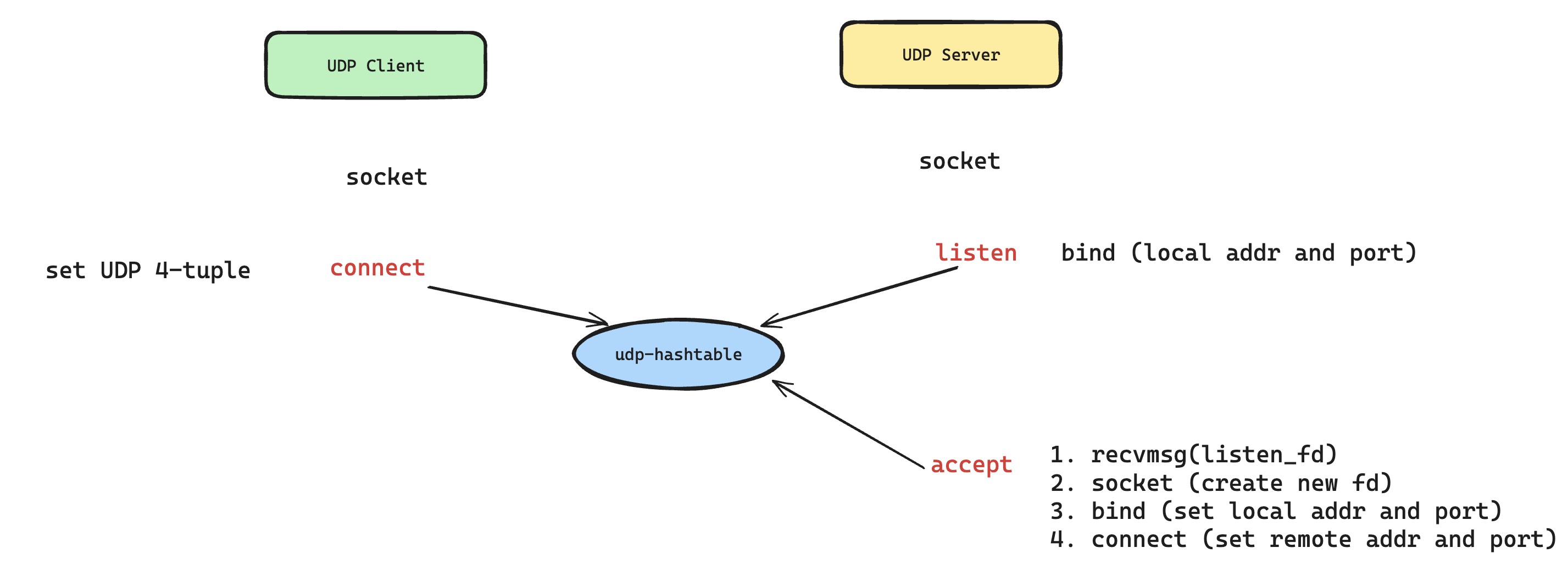
这个技术方案的好处非常直观,上面的热更新问题终于有救了。在发生热更新之后,老进程只需要关闭自己持有的监听 UDP 套接字,然后新的请求(即新的 UDP 四元组流量)就会被分配到新进程持有的监听 UDP 套接字,然后新进程再根据四元组创建出对应的 UDP 套接字(accept 操作),然后持有该 UDP 套接字就可以正常服务新的请求了。而老进程持有原来的那些 UDP 四元组套接字还可以正常服务。至于,我们想进一步实现无损热更新功能,只需要让老进程上的生产者发起请求给新进程,然后建立转发通道即可,一切看上去都那么美好。
但是事情并不是想的那样一帆风顺,这套实现方案在落地的时候,会遇到非常多的困难。首先,这里有一个非常直观的弊端是,UDP-Based 的传输协议和 UDP 四元组绑死了,而实际上 QUIC 这类传输协议根本没有选择 UDP 四元组作为连接标识符。上篇博客还在聊 QUIC 的连接迁移,要是按这套实现搞起来,岂不是连接迁移都彻底玩不转了。但其实这并没有真正绑死 UDP 四元组,多进程的架构下,监听 UDP 套接字获取到新的 UDP 四元组数据之后,可以根据 UDP payload 里面携带的连接标识符以及是否是协议的握手报文等逻辑,来判断真正连接会话在哪个进程上,然后再把数据转发到对应的进程。如果真正发生了连接迁移,再让该会话另外创建一个新的 UDP 套接字,并且设置上新的 UDP 四元组,确保后续跑在新链路的数据能够被该会话直接接收到。
大家可能已经敏锐的感觉到了,这套方案面临的真正的挑战,并不仅仅是上面这些异常场景的处理。而是这套机制完全依赖内核对 UDP 数据报的匹配机制实现,而 Linux 内核又没有给出任何承诺,毕竟 UDP 从来没有过面向连接的设计,我们甚至可以从内核代码的注释里面感受到,当年的内核开发者也没有预想有人会这么使用 UDP 套接字。换句话说,这套方案本质上是非常 tricky 的,这也意味着自然会有代价。我在实现热更新功能的时候,就一脚油门猛踩进了坑里。
如何让同一个套接字被多个进程同时持有
在探究内核 UDP 数据报文匹配机制细节之前,我们还要再讨论一个问题,即本小节的标题。为什么会有这样的这个问题,其实在这里,只是为了解决一个场景,如果让多个进程都持有监听在相同地址的套接字,要知道上文提到的 bind-hashtable 可是拦路虎,不过你是 TCP 套接字,还是 UDP 套接字,绝对不让你能够 bind 在相同的本地地址和本地端口组合上。至于为什么需要多进程同时监听,本质上多进程或者多线程可以利用 CPU 多核能力,但这个话题就有点越扯越远了,都开始聊多线程和多进程优缺点比对了,我必须紧急打住。
一般来说,解决这个问题有一个非常传统的方案,就是通过父子进程继承,来实现多个进程同时持有相同的监听套接字,更具体一些来说,是父进程负责创建监听套接字,然后 fork 出多个子进程,这样每个子进程都可以共享这个监听套接字。另外,我好早的时候还在 《unix 网络编程卷1》里面看到过一个解法,就是通过 sendmsg 和 recvmsg 配合着 SCM_RIGHTS 控制消息,让两个进程之间可以传递文件描述符。最后,Linux 内核高版本甚至还提供了专门的系统调用 pidfd_getfd,来帮助用户态进程之间更方便的共享文件描述符。
这些方案虽然形式各不相同,但是实现的本质应该是基本一致的。考虑到上文已经介绍了隐藏在套接字背后的数据结构,所以这里可以说的更准确一些,每个子进程都会在 struct file 结构里面引用计数加一,这也意味着这些进程持有的套接字背后,比如在内核态的 struct sock 都是完全共享的。
惊群
共享同一个的监听 struct sock 状态,但是多个进程同时持有,那么如果有新请求来了,内核到底该唤醒哪个进程去处理该请求呢。想到这,是不是有点熟悉,这就是有点老掉牙的惊群问题。惊群问题的缺点我就不再赘述了,我就简单说一说在多进程持有监听套接字情况下,惊群问题在 Linux 下的解法。Linux 在内核 4.5 版本为 accept 实现默认引入了 WQ_FLAG_EXCLUSIVE 特性,当有新 TCP 请求到达的时候,陷入 accept 阻塞调用的所有进程不会都被唤醒,而是只唤醒在等待队列中的第一个进程(相关代码逻辑)。
当然,这里有一个特别值得注意的事情,就是已经没有多少服务端实现是傻乎乎阻塞在 accept 上面等待新请求,都基本上是使用 epoll + non-block 的 IO 复用模型,所以 epoll 针对这个惊群也有对应的实现,即注册在 epoll 的监听套接字,需要显式 epoll_ctl 设置 flag EPOLLEXCLUSIVE,才能确保 epoll 添加等待队列的时候 去设置 WQ_FLAG_EXCLUSIVE,最后同样确保仅唤醒第一个进程去处理新请求。同样,上面 UDP 模拟监听套接字的方案也可以受益于此。
这个方案存在一些缺陷,就是每次一定唤醒等待队列里面的第一个进程,相当于按照 First In First Out 原则来进行唤醒。这样的话,并不能很好的保证多个进程之间调度分配的公平。另外,还有一个比较致命的点在于,多个进程同时持有同一个底层 struct sock 来监听,不可避免的会存在一些锁的竞争,会影响一定的性能。
对了,我这里甚至没有提及可能存在的一些应用层解决方案,比如以 nginx accept_mutex 功能为例,引入锁的争用,来确保负责监听的套接字同一时间只会在某一个进程上被注册到 epoll 事件中,也就是说让每个进程轮流负责处理新请求,这样惊群问题就被解掉了,同时还解决了负载均衡的问题,只要某个进程的负载超过一定阈值,那么这个进程就会主动放弃锁争用,不再将监听的套接字加入自身 epoll 事件中。不过这套方案自然没有真正从内核态去解决这个问题来得干净高效,只是无奈之举,早就被废弃掉了。
Reuseport
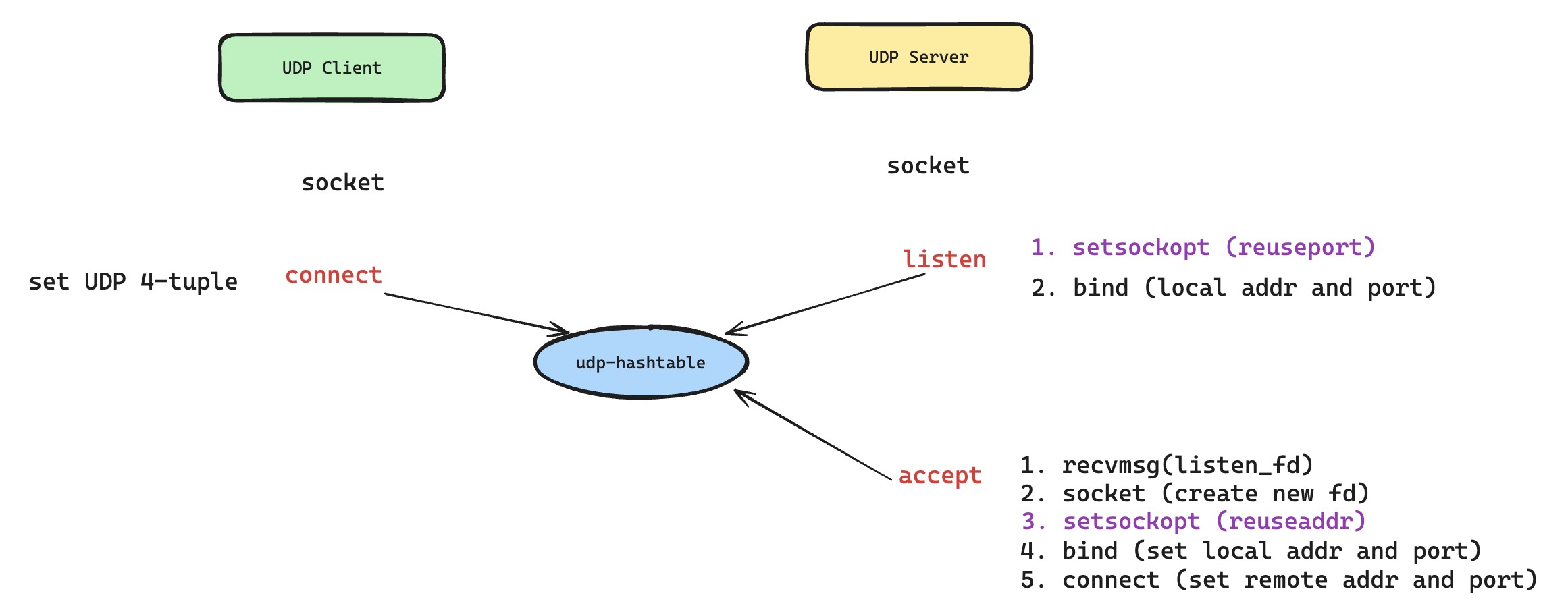
所以,如何共享监听套接字需要一个版本答案,那就是让所有进程都单独持有一个监听套接字,互不干扰,于是 Reuseport 解决方案应运而出。特别注意的是,不管是 TCP 还是 UDP,内核都给他们支持了 Reuseport 功能,而市面上的多进程服务端,肯定是会优先使用 Reuseport 功能,来确保在新请求处理时候的足够高效。
首先,Reuseport 允许不同进程创建独立的套接字,但是这些套接字可以 bind 在相同的本地地址和本地端口组合上,即 Reuseport 要在 bind 系统调用的执行逻辑里面,绕开 bind-hashtable 的限制。这样的话,内核 Reuseport 要处理的问题,就从之前新请求需要唤醒哪个进程,变成了接收到的新四元组数据包需要分派给给哪个监听 struct sock 会话,即内核的数据包查找逻辑需要对 Reuseport 做特殊的适配,这里面就确保了所有开启 Reuseport 的套接字,会根据四元组哈希结果严格进行分配。
这里还需要补充一个点,就是 Established-over-unconnected 使用,有了一些新的改动。可能之前大家会有问题,为什么新建连接的套接字可以和监听套接字一样 bind 相同的本端地址和端口。现在我们清楚了,监听套接字利用 Reuseport 来共享监听地址,而这里 UDP 新建连接套接字则是利用 Reuseaddr 来确保可以 bind 成功。Reuseaddr 不像 Reuseport 那么复杂,但是也可以帮助套接字突破 bind 冲突限制。
最后,根据四元组做哈希来分配,看似公平,但是在真实的生产环境,很可能还是会出现负载不均的情况,毕竟四元组没有包含业务属性,有的热流死皮赖脸不走,你也拿它没办法。像一致性哈希算法,也有类似的缺陷,面对这种情况,是没办法做到真正的负载均衡。
Linux 内核 TCP 或 UDP 报文匹配机制
接下来就是开始真正分析 Linux 内核数据包在传输层的匹配机制了。上文提到过,TCP 数据包匹配时,会优先匹配已经建联的四元组,查找失败后才去看有没有监听的套接字可以处理新的请求。也就是说 TCP 是严格遵循先查找 establish-hashtable 再去查找 listening-hashtable 的逻辑,所以 Reuseport 需要在 listening-hashtable 里面做特殊适配。
而 UDP 数据包只会查询自身维护的 udp-hashtable,也并没有提供保证说,UDP 数据包一定是优先匹配到四元组信息完全一致的套接字,如果查找失败,就把数据包分配给本地地址和本地端口组合匹配的套接字,所谓上文提及的 UDP 监听套接字。然而 Established-over-unconnected 一切都建立在这个逻辑上,而这个逻辑在内核很多版本中是脆弱的。特别是 Reuseport 功能也在 UDP 查找逻辑里面做了大量改动,让这个逻辑也引入了很多变数。
代码分析
下面只是描述了内核各个版本对匹配机制的实现具体细节,但只是描述了对应版本的现状,并不代表改动是该版本引入的,这个得把 commit 找到,然后看到底是哪个版本引入的,我有点懒,就没有去一个一个翻了。
内核 2.6 版本
我们先从相对古老的 Linux 内核版本开始分析代码逻辑,这样也更容易理解。首先是 TCP 查找逻辑,established-hashtable 查询没什么好说的,直接四元组哈希查找。但对于没有找到的新请求来说,listening-hashtable 查找逻辑 就是我们要研究的地方,这里很清晰的看出,listening-hashtable 是以数据包目标端口来进行查找的。
而 UDP 的查找逻辑和 TCP 的基本一致,udp-hashtable 查找逻辑 也是以数据包的目标端口作为哈希表的 key 来查找的。但是,值得注意的是,内核 2.6 较高的版本中对此还进行了优化,引入了一个新的哈希表 udp-hashtable2,以数据包的目标端口和目标地址作为哈希表查找的 key。如果 udp-hashtable1 的 hash slot 对应链表长度大于 10,就切换使用 udp-hashtable2 来提升查找效率。
所以,在内核 2.6 版本中,UDP 哈希表查找,有额外的优化,而 TCP 哈希查找逻辑并没有。这个其实也容易理解,因为 TCP 哈希查找只发生在 TCP 握手的时候,换句话说,TCP 还有 established-hashtable 来保证查询效率,而 UDP 的所有数据包都会走这个 udp-hashtable 的查询逻辑,很容易暴露出哈希表退化成链表的问题,是的,Established-over-unconnected 方案在高并发场景下,存在严重的性能问题。
Established-over-unconnected 技术方案中存在两类套接字,模拟监听的 UDP 套接字个数很少,并不会影响到查询效率。而真正绑定了新请求四元组信息的套接字是和请求数量一一对应的,高并发的场景下,自然会导致性能问题。另外需要注意的是,udp-hashtable2 的优化是根本没有办法解决这样的问题,因为这些套接字使用的都是相同的本地地址和本地端口,即 UDP 监听地址,所以 udp-hashtable2 本质上没有改变任何事情。
值得补充的一点是,TCP listening-hashtable 同样存在这个问题,虽然只是新请求握手会查询这个哈希表,但是 linux 内核最早给这个哈希表的大小仅仅设置了 32,如果存在非常多个不同的 TCP 监听套接字,也会导致 listening-hashtable 性能退化成链表。话说,除了调大哈希表的大小,还有一个办法,就是尽量减少监听套接字的个数,比如说全零地址监听,然后应用层自己来做区分处理,但是这个对业务配置存在一定的要求。这个性能问题同样也有很多博客描述过,我这边把 Cloudflare 博客给贴出来,给大家参考。
内核 3.9 版本
内核在 3.9 版本左右吧,前后脚分别支持了 TCP Reuseport 和 UDP Reuseport 功能,核心改动的话,主要是在刚才分析的查询匹配机制里面,这里就不去探究 TCP bind 逻辑的调整了。哦,对了,在这个版本,TCP 的 listening-hash 也开始使用本地地址和本地端口组合作为关键字做查询了,毕竟单独使用本地端口做查询,效率实在是有点差。
TCP 匹配逻辑和 UDP 匹配逻辑实现基本是一致的,代码有一点点 tricky,四元组匹配查询优先级最高,然后是本地端口和本地地址组合匹配优先级次之,然后会遍历完链表中所有的节点,这样开启了 Reuseport 功能的套接字,会进行四元组哈希计算,来根据哈希值负载均衡选择一个 Reuseport 监听套接字,正如上文所说的那样。所以,从代码上来看,Established-over-unconnected 技术方案需要的前提条件并没有被打破,即一定是四元组匹配成功的套接字优先来处理数据包。
内核 4.6 版本
这里我看到内核对 Reuseport 功能做了一些优化,不管是 TCP 还是 UDP 都享受到了。优化首先是引入了 struct sock_reuseport 来提升查询效率,提升的思路很简单,用空间换时间,新维护一个 reuseport group 来快速查询,把所有开启了 Reuseport 功能并且监听在相同本地地址和本地端口组合的套接字都维护在这个数组里面。
这样的话,我们在哈希表查询的过程中,不需要每次都必须遍历完整个链表了,如果链表里面一旦找到匹配的 Reuseport 套接字,就直接开始去该套接字对应的 reuseport group 里面根据哈希值快速匹配。如下图所示,这样的话,新的请求意味着新的四元组,不会匹配到绿色的 sk,而一旦匹配到第一个红色的监听 sk,就可以直接跳过对下面红色监听 sk 的匹配流程,直接去 reuseport group 里面快速进行四元组哈希匹配。
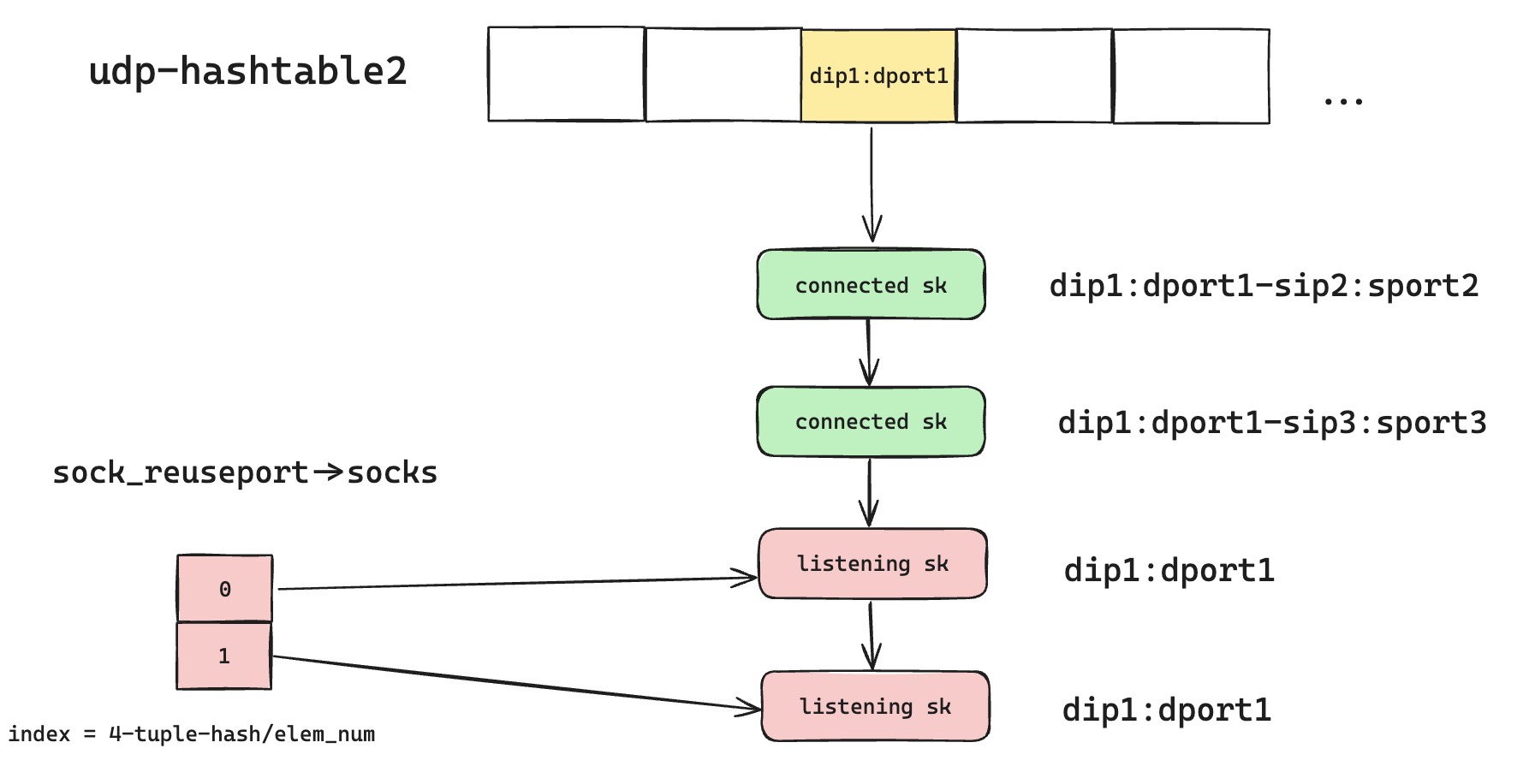
但是这个优化,对 Established-over-unconnected 方案是一个致命的打击,破坏了之前那个脆弱的保证,即四元组匹配优先级最高,本地二元组匹配次之。仔细看这个优化的实现逻辑,一旦遇到匹配的 Reuseport sk 就立刻返回查询结果,不再继续匹配,那么在某些情况下,对于已经建联的绿色 UDP sk 来说是致命打击。我们可以举个例子,如果后续又有新的 Reuseport 监听 sk 创建,那么 udp-hashtable2 会变成如下图这样。那么根据优化后的匹配规则,本来属于绿色 sk 的 UDP 数据报,会和第一个红色的监听 sk 部分匹配上,然后因为是 Reuseport 开启了,所以会立刻返回结果。
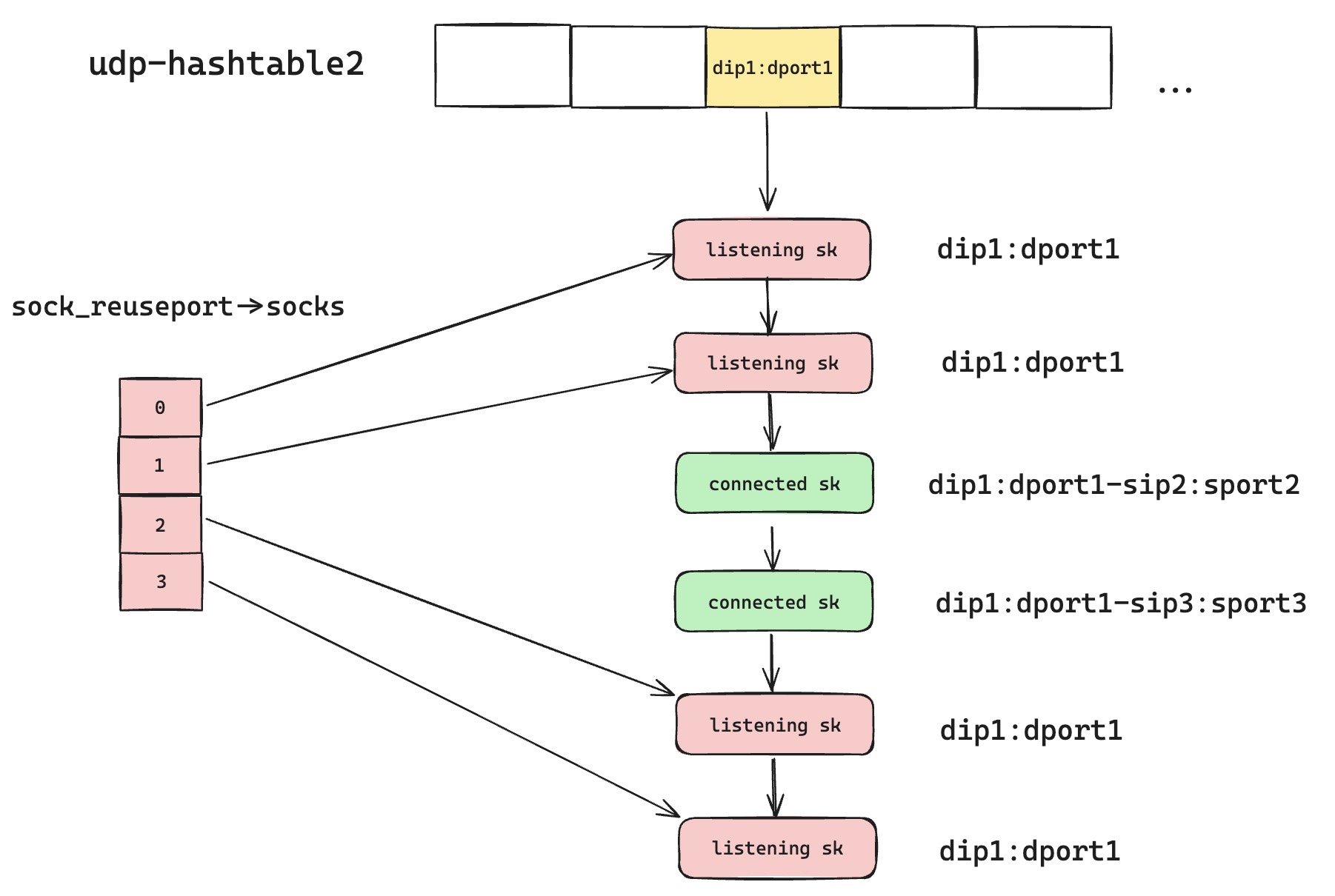
上面的场景看似很难发生,但是我的热更新功能,却会结结实实踩到这个坑里面来。UDP 热更新功能同时使用了 Reuseport 和 Established-over-unconnected 功能,新启动的进程会再次创建监听 sk,这样原来进程还在服务的老请求,将无法接受到数据包,数据包会被分配到监听 sk 上面,并且有可能是分给新进程。这也是为什么,我在 3.10 版本机器上测试是正常的,而在 4.17 版本的机器上,热更新会导致老的请求断流。
内核 6.1x 版本
所以,这个问题的解法是什么,其实就是像 TCP 实现那样,udp-hashtable 也急需一个类似 established-hashtable 的存在。就在去年的时候,Linux 内核终于把 udp-hashtable 进行了升级,优化成了按照四元组进行哈希匹配,代码补丁在这里。这样的话,就可以一箭双雕,既可以解决性能查找的问题,又不会出现找错套接字的情况,因为四元组哈希的话,新建联套接字很难和监听套接字再碰撞在一起。Established-over-unconnected 方案终于迎来了新生,不过我们当年是通过打内核补丁的方式解决了这个问题。
Established-over-unconnected 特别注意事项
抛开上面描述的问题不谈,这个方案依然还存在一些坑需要特别注意
创建新建联套接字并非原子操作
回顾上文,针对 UDP 新建联的套接字,我们是通过 bind 和 connect 系统调用,来为新建套接字添加四元组信息的,调用完成后,有完整四元组信息的套接字可以稳定接收属于自己的 UDP 数据报。但是,bind 和 connect 并非原子操作,在这个执行的间隙,可能存在一些报文,会被错误的匹配到其他套接字上面去。
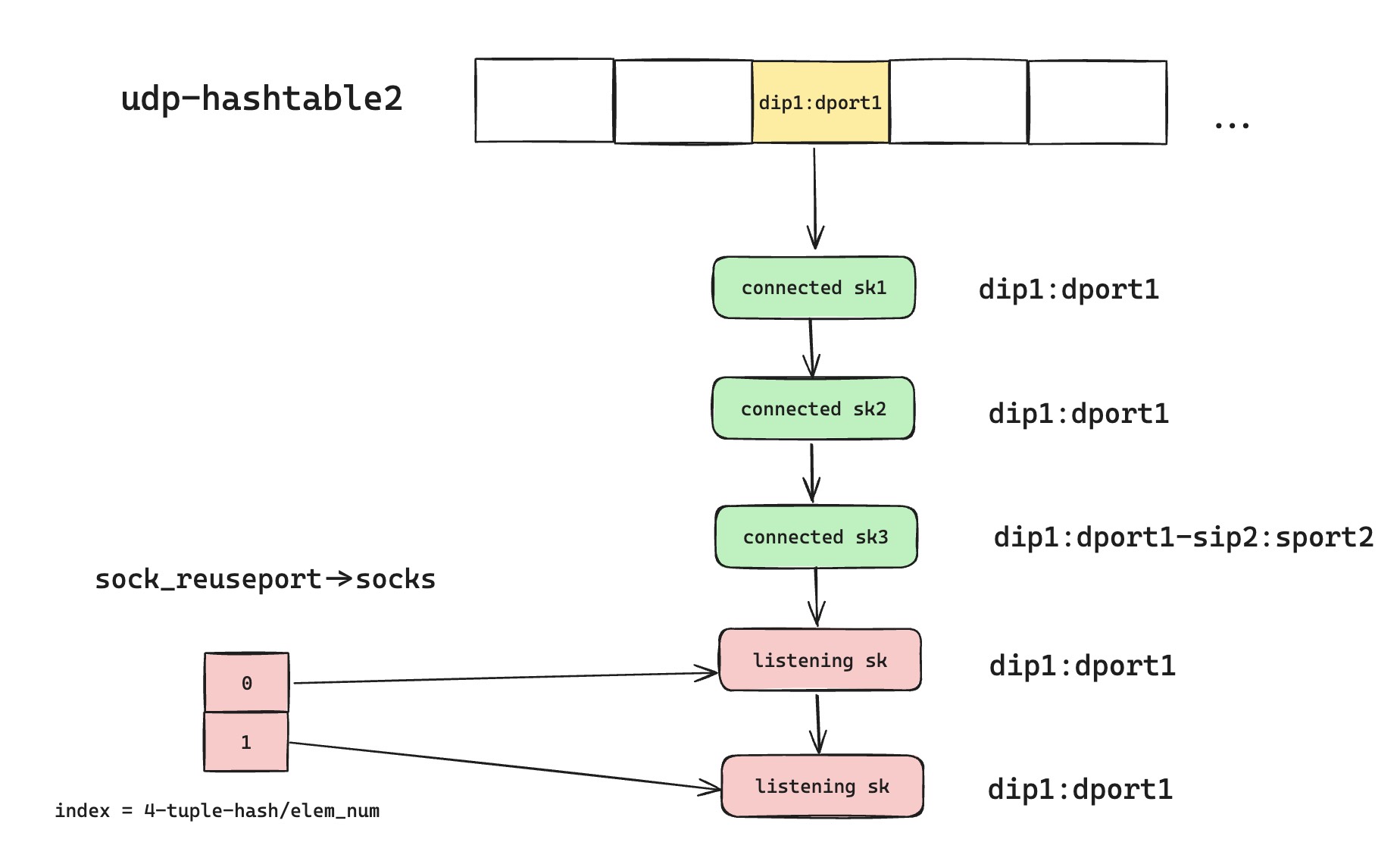
那我们可以举个例子,如果有两个进程都在创建新的套接字,但是都只执行了 bind 操作,还没有来得及 connect,这个时候在 udp-hashtable2 里面的情况会如图所示。属于 sk1 和 sk3 的数据包,可能最后还是会分配给开启了 Reuseport 的监听套接字。所以针对这样的情况,我们需要应用层接收数据包的时候,做一些特殊处理。如果更狠一点,可以考虑扩充内核能力,直接支持一个可以加锁一口气设置四元组信息的系统调用。
使用 Reuseport 的正确姿势
首先在这里,想强调的一点是,监听套接字不要有的使用 Reuseport,有的没使用,要保持统一。如果有人这么干了,那整个匹配就变得比较烧脑,得看对应内核匹配的代码,才能知道最后数据包会被匹配给谁了,相当于错误的道路上越走越远。还有一个小细节,如果有多组 Reuseport 数组的套接字,即监听在不同的本地端口和本地地址组合上。考虑到 4.6 引入的优化,在 udp-hashtable1 和 udp-hashtable2 中如果发生了哈希碰撞,然后全零监听的
还有一个需要注意的核心事项,尽量不要改变 Reuseport 套接字数组大小,哪怕是在 4.6 版本引入 Reuseport Array 之前,因为 Reuseport 最后的匹配逻辑,都是拿四元组的哈希值去当前所有 Reuseport 套接字中匹配。如果套接字个数发生变化,那么哈希表匹配就会完全乱掉的。dog250 博客给出了一些解决方案,但是如果我们内核版本已经支持了 udp-hashtable 四元组查找,那么只需要监听 UDP 套接字做一些简单的同步处理,就可以规避这个问题。
基于上面的注意事项,再补充一下 nginx 和 tengine 当初引入 Reuseport 时候一个细微的差别。tengine 早期的实现,是每个子进程都自己打开一个 Reuseport 监听套接字,反正 Reuseport 就是让不同进程可以自由 bind 在相同的地址端口组合上。然后发生热更新的时候,老进程会直接把监听套接字关闭掉,新的进程重新创建新的监听套接字。所以,我们看到这样的实现,会导致 Reuseport 监听套接字数组发生变化,哈希匹配会乱掉。
如果是 TCP Reuseport 套接字的话,那么是可能会影响新建请求的,因为是监听套接字维护了两个队列,一个是半链接队列,一个是全链接队列。如果正在服务的监听套接字被关闭了,那么对应的半链接队列也会一起销毁掉,而半链接队列里面的请求,是会挂掉的。即客户端发送 syn,服务端接收 syn,并且创建 req,同时塞到 icsk_accept_queue 队列中,同时回复 syn+ack,icsk_accept_queue 队列和监听套接字对应的 sk 是强绑定的,如果监听套接字销毁了,那么这个队列也会销毁,并且丢掉 req。因为客户端已经是 establish 状态了,不会再发送 syn 包了。
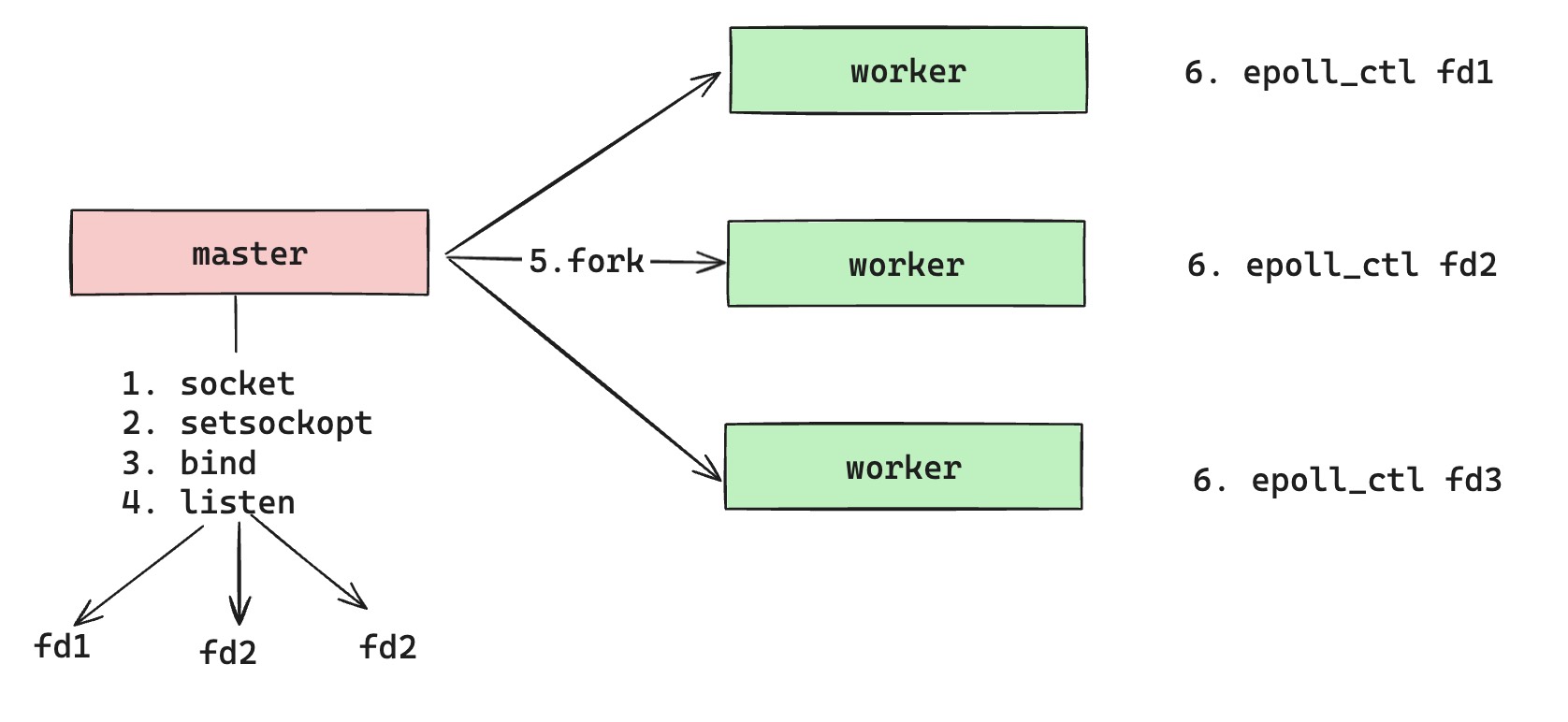
所以,我们来看看 nginx 正确的做法是什么,自然是尽量保证监听套接字不要被销毁掉,同时也做到每个子进程都拥有独立的监听套接字。如上图所示,我们还是利用父子进程继承的方法,父进程直接借助 Reuseport 选项,直接创建出子进程个数一致的监听套接字。这样,fork 出来的每个子进程,都可以独立的使用着其中一个监听套接字,对应内核中唯一的 sk。最关键的是,在热更新过程中,父进程 spawn 出新版本的父进程,可以借助 nginx 原来的机制,即通过环境变量,将原父进程所有监听套接字都传递给新父进程,然后新父进程再去解析配置,并且重新复用这些监听套接字,避免了销毁和再次创建这些套接字的操作。但这个实现,并不是万能的。在实际线上场景中,如果调整 nginx worker 个数的配置,依然会导致出现监听套接字被删除的情况,所以说,线上尽量不要去调整 nginx worker 个数配置。
尾声
其实这一系列问题,早就在 dog250 和 Cloudflare 的博客里面有一些描述了,不过我还是坚持写了这篇博客,试图在不一样的视角,进行一些补充。虽然我早在四,五年前就在以前公司的内网发布类似的技术文章,但是我觉得我这次写的应该比上一次前后文要逻辑性更强一些。但在写这篇博客的过程中,我还是有很多次想中途放弃写这玩意,因为这里有太多细节了,而且串起来的线不是很清晰,让我写的时候有点痛苦。
既然这么痛苦,那其实是不是 Established-over-unconnected 这个 UDP 的解决方案是不是尽量就别用了。毕竟一方面内核本身就没有这样的保证,各个版本内核之间的细微差别,真的让人头大。另外,上篇博客说了半天,UDP-Based 协议是怎么摆脱 UDP 四元组束缚的,结果现在还是想像 TCP 那样根据四元组进行 sk 的匹配,着实有点舍本逐末了。
所以有没有其他解决方案呢,其实这里还有使用 eBPF 的解决方案,最早应该是 facebook 提出的,简略的来说,就是在 Reuseport 核心查找逻辑里面,引入 eBPF 执行脚本,让用户可以编写 eBPF 脚本,来自由的根据 UDP 数据报的 payload 内容选择对应的 Reuseport sk。这样可以达成一个很完美的效果,所有 UDP-Based 协议的流量都可以自由的根据自身定义的连接标识符去匹配到对应的套接字。我在下一篇博客,会聊一聊这个基于 eBPF 解决方案的实现细节,以及分享一下我当时是怎么从这套解决方案里面从零开始学习 eBPF 的。对了,正巧 Cloudflare 上个月还开源了一个基于 eBPF 的 UDP 热升级通用解决方案,我正好也抽空学习下代码,蛮好奇他们是怎么做的。