用 Rust 从零开始写 QUIC:实现 QUIC 多路复用流传输和流量控制
QUIC 多路复用流传输
单路数据流可能面临的问题
关于 Head of Line Blocking
大家都知道,QUIC 多路复用流传输主要是为了解决 HOL blocking 问题的,所以我们就从这里开始。但是,我这里不会花费太多时间在解释什么是 Head of Line Blocking 问题,因为网上有非常多资料很好的讲述了这个问题。
从这篇 wiki 我们可以知道,这个问题可能发生在不同的协议层上,但 QUIC 解决的是出现在网络传输层的问题。比如说,TCP 连接虽然提供了可靠字节流的抽象,但是一个 TCP 连接只能提供一个可靠字节流,当传输的数据中逻辑上存在多种流,并且不存在互相依赖关系时,唯一的可靠字节流抽象,就会导致 HOL blocking 问题。
缺乏优先级控制的手段
当应用层存在多个数据流,不仅仅只是逻辑关系上没有互相依赖,很大概率上还会存在优先级差异的情况。比如说,在一个远程桌面软件中,用户操作的控制指令、用户正在下载或上传的数据、以及桌面图像和音频数据,他们有着截然不同的优先级关系。我们更期望能够保证关键数据的优先级,而不是让用户下载或上传的数据去占用我们的宝贵的带宽。
而在 TCP 的单一可靠字节流上,我们很难控制数据发送的优先级,因为一旦数据塞进 TCP 层的发送队列,应用层就无能为力了,只能依赖 TCP 自身的发送策略听天由命。具体 TCP 的发送策略有很多,比如说受限于对端的流控接收窗口,自己作为发送方的拥塞窗口以及 Pacer 控制器,甚至还有出于传输效率考虑的 Nagle 和 Corked 优化策略等等。
而 TCP 本身也不会提供特定的优先级设置。对了,TCP 有一个 urgent 机制的设计,但是实际上没有什么用,一方面是支持力度非常有限,还受限于中间设备的兼容性。另外一方面,能够携带的紧急数据太少,只能用来做控制命令,没办法适用于更普遍的多优先级数据流发送场景。
关于 TCP 的多路复用方案
按照正常的节奏,我应该是开始仔细描述 QUIC 是如何实现多路复用流,来解决 HOL blocking 还有流优先级控制等诸多问题的。但是在这之前,我想先描述下 TCP 这个老前辈是如何应对这个问题的。
TCP 应对方案很简单,既然一个 TCP 连接无法提供多个可靠字节流的能力,那么就同时使用多个 TCP 连接来达到相似的目的。更具体一些,就是在应用层直接维护多个 TCP 连接,应用层自己自适应的去根据自身的业务逻辑,来将没有互相依赖关系的流量分配到不同的 TCP 连接上。
这里顺便提一嘴,还有一种解决方案是 MPTCP ,直接在 TCP 协议里面进行设计,并且实现在内核态。但是这套方案,本质上并不是为了解决我们上面提及的两个问题。而是为了更好的复用多个网络链路,比如说可以同时使用 5g、wifi 和有线,来同时向目标建联,让单一的可靠字节流可以跑在多个不同的网络链路上,从而达到更好的网络传输效率。QUIC Multipath 也是类似的设计,让 QUIC 也可以利用多个网络传输链路,也许我在后面可以尝试在 feather-quic 里面实现这个草案。
QUIC 在设计多路复用时值得关注的细节
QUIC Stream 开启
之前的博客中详细讨论了 QUIC 握手的细节,强调了传输层协议握手,通常是为了保证建立连接的安全性、链接唯一性,以及传输效率等等。现在,展示 QUIC 设计优越性的时刻又到来了,因为 QUIC 将传输能力(QUIC Stream Frame)和控制消息解耦开,这意味着,QUIC Stream 根本不需要去考虑普通传输协议需要考虑的握手问题,QUIC Stream 只需要享受着 QUIC 握手成功之后的提供一切便利。
所以 QUIC Stream 在设计上,根本不需要握手,直接开始发送数据即可。这里肯定会有人问,那怎么区分多路流,以及每条 QUIC Stream 又是怎么创建的呢?其实答案很简单,QUIC Stream Frame 中包含了 Stream ID 字段,该字段来区分不同的 QUIC Stream。而当应用层(不论是服务端还是客户端)想创建一条新的 QUIC Stream 的时候,只需要构造好新的 QUIC Stream Frame 就可以创建 QUIC Stream。因为 QUIC 协议规定了,Stream ID 比特位的最后两位,可以用来判断 QUIC Stream 是客户端主动创建还是服务端主动创建,是单向流还是全双工流。这些关键的信息,都通过 Stream ID 设置好了,这么做的好处是显而易见的, QUIC Stream 启动不需要任何额外的流程,主动发起方设置好正确的 Stream ID,然后正常的发送携带数据的 QUIC Stream Frame 即可。
这里,还需要强调的是,QUIC Stream Frame 还携带了 offset 和 length 两个字段。offset 字段在之前的博客也有提到过,是用来实现单个 QUIC Stream 可靠传输的核心。接收方通过 offset,知道接收的数据具体的排序,能够保证最后按序的抛给应用层。至于 length 字段的话,自然是该 QUIC Stream Frame 的数据长度。还有一点小优化,就是 QUIC Stream Frame 的 Frame ID 是有多个值的(0x08..=0x0f),因为在 Frame ID 里面也携带了一些关键信息,比如说 offset 字段是否存在,length 字段是否存在,甚至关闭 QUIC Stream 的 FIN flag 也在其中,极大的节约了传输的数据。所以 QUIC 协议的高效就是这样一点一滴积累起来的。还需要注意的是,如果 length 字段不存在,QUIC 会默认是接下来所有 UDP Datagram 中的数据都是 QUIC Stream Frame 传递过来的,我在实现的时候,没注意到这点,被小坑了一下。
QUIC stream 关闭
刚才说到,QUIC Stream 开启设计只需要享受 QUIC 握手成功的成果,自然而然的,QUIC Stream 关闭也无需考虑 QUIC Connection 在关闭过程中,需要考虑的问题。QUIC Stream 只需要关注,如何正确的结束掉全双工的通信。当然,单向的 QUIC Stream 只是减少了部分工作,其余和双向 QUIC Stream 没有本质的差别。
在描述 QUIC Stream 关闭之前,我还是想以 TCP 为例,因为在数据传输通道关闭的过程中,其实有很多细节。其中最关键的一个问题,就是当应用层调用了 TCP Close 这个 socket api 之后,之前发送的数据,是否能够真正抵达对端。因为我们都知道,TCP Send 调用成功之后,只代表数据被塞进了 TCP 协议栈,在发送侧能够确认对端已经收到的唯一信号,就是对端发过来的 Acknowledge 信息。但是,如果出现了丢包等情况,这个确认的过程可能会被拉长。而 TCP Close 调用成功,并不能保证最后发送的数据,是真的抵达对端了。所以,这本质上还是相同的一个问题, TCP 的控制通道和数据通道耦合在了一起,导致 TCP Close 会让使用者产生误解。
其次,TCP Close 调用还有一个非常小的边界情况,如果 TCP 接收队列还存在数据,没有被应用层读取出来,那么 TCP 协议栈不会执行正常的四次挥手,而是会直接使用 RST 报文去终止 TCP 连接,这样更有可能导致对端无法接收到发送方在关闭前最后发送的数据。TCP 协议栈这么实现的初衷,是希望能够通知对端,本端作为接收方其实没有处理接收到的数据。感觉有点累赘,并且容易让人误解。毕竟 RST 报文会导致对端 TCP 协议栈直接终止,从而可能无法正确处理本应该接收到数据。
想必,大家都想起来了 TCP 网络编程中 Linger 选项。没错,这个实现本质上就是给这个问题打的一次补丁。一方面 Linger 可以让 TCP Close 的时候,进入阻塞式等待,这样直到最后发送的数据被对端确认,我们再进行 TCP 四次挥手。另外一方面,Linger 可以选择直接使用 RST 终止 TCP 连接,不过考虑到 TCP 数据传输通道也会受影响,显然不是一个很好的做法。在这里,QUIC Stream 只是用来服务于数据传输,所以 QUIC Stream 关闭的时候,并不需要考虑 QUIC Connection 是否需要被结束。QUIC Stream 只需要按照自己的节奏来关闭自身即可。
但是,我们还有第二个问题,就是 TCP 是一个全双工的传输层协议,所以当我们在应用层 Close 了 TCP 连接,相当于同时关闭了 TCP 连接的读写通道。TCP Shutdown 则是这个问题的解决方案,提供了一个单独关闭读或者写的操作。
所以,QUIC Stream 在关闭的时候,很自然而然的,也有分别关闭读和写的操作。正常关闭写的操作是,通过在 QUIC Stream Frame 中设置 FIN flag 来实现。关闭读的操作,是通过发送 Stop Sending Frame 来实现。这里有一个特别需要注意的地方,就是说,Reset Frame 的作用是什么。这里,我理解有两处作用:
QUIC Stream Frame中的FIN flag只是正常主动关闭连接写方向,发送方会确保所有已经发送的数据都会抵达对端。而Reset Frame则是立即关闭连接写方向,发送方表示自己不会再对 in-flight 的数据负责。一般是用于发送方的应用层出于某些自身业务逻辑,觉得不再需要发送数据,才使用的。- 如果发送方接收到了对端发过来的
Stop Sending Frame,这意味着对端认为不再需要发送方的后续数据了,所以这个时候发送方需要立即回应了Reset Frame,这样就可以快速终止发送方的数据发送,减少开销。
在 RFC 里面的 Stream 状态机切换图中,没有标出 Stop Sending Frame 的存在,这让我一开始有点困惑,但是通过 RFC 的描述以及相关实现源码阅读,这方面的整体设计还是清晰可见的。
TCP 和 QUIC 在多路复用方案上的优缺点对比
上文提到了多个 TCP 连接的方案,虽然和 QUIC 多路复用流一样,都是为了解决类似的问题,但是还是有很大的不同,这里我会依次对比一下。
- 从协议设计的角度来说,毫无疑问,QUIC 多路复用流有非常大的优势。QUIC 多个 Stream 是可以共享 QUIC 握手和挥手的成果,而多连接 TCP 方案不得不为每个连接重复这样的流程,如果有 TLS 的话,情况会更糟糕,毕竟 TLS 的握手和挥手也是一个不小的开销。另外,在拥塞机制上,QUIC 多路复用流无疑表现的会更好,毕竟多个流可以高效使用同一个拥塞实现机制,高效共享相同的探测信息,而多连接 TCP 方案则不得不去独立运行各自的拥塞控制机制。
- 从工程实现角度,多连接 TCP 方案也会复杂很多,毕竟是好几个独立的 TCP 连接,必然存在
我是谁、我在哪、到哪去的终极问题。所以应用层需要设计一些额外的交互机制,才能让这些 TCP 连接共同工作,达到我们想要的目的。 - 虽然这两个方案都在解决优先级控制的问题,但是毫无疑问,QUIC 的方案是更好的。因为 QUIC 的多路 Stream 是真正共享着同一个拥塞控制机制,消费新增的拥塞窗口的时候,很容易根据提前设定好的 Stream 优先级,来决定发送次序。而多连接 TCP 方案则需要应用层介入,并且主动控制优先级低的数据写入 TCP 连接的速率,毕竟 TCP 可没有为应用层提供控制底层发送策略的机制。
- 但是多连接 TCP 方案有一个比较大的优势,可以真正使用多条网络链路来传输数据。毕竟已经使用多条 TCP 连接了,跑在不同的网络链路上,也不是什么难事。
QUIC 流控
关于 QUIC 的流控,考虑到是多路流的原因,设计上确实比 TCP 流控复杂了一些。但是同时,也吸取了 TCP 流控之前踩坑的经验教训,做了一些设计上的优化和改进。
最显而易见的一点是,TCP 流控窗口的传输效率是存在问题的。一方面,每一次 TCP 报文都必须浪费空间携带接收窗口的大小,哪怕对端还远远没有触及接收窗口的可能,另外一方面 TCP 报文头可怜的 2 字节长度远远不够容纳接收窗口大小,哪怕使用了 TCP 扩展项解决了这个问题,但是始终是一个隐患,时刻可能爆发(比如遇到不支持该选项的协议栈实现或者中间转发设备),影响传输效率。而 QUIC 在设计上,就把控制类消息和传输消息解耦掉,都作为 QUIC Frame 独立的存在。比如说,QUIC Max Data Frame 就传递 QUIC 整个连接的接收窗口大小。所以,QUIC 协议不存在上述问题。
此外,因为 QUIC 并不是时时刻刻传递接收窗口,那么自然要解决两个问题,一个是传送接收窗口大小的时机问题,另外一个是发送方发现接收窗口不够用的时候,怎么办。前者很好解决,QUIC RFC 里面推荐了一些做法,确保提前更新接收窗口,根据当前的网络情况以及应用层的消费能力进行估算更新的频率,确保效率和开销的权衡。大名鼎鼎的糊涂窗口综合征,就是提示我们要注意接收窗口更新的策略问题,如果接收窗口增长的非常慢,那就不要频繁更新,积累一段时间再更新。第二个问题,则是通过 QUIC Blocked Frame 来解决,发送方自己主动发送这类 Frame,来提示对端,我这边发送被阻塞了,需要你更新接收窗口。而不是期望于接收方有觉悟来更新,TCP 的 Zero Window Probe 更像是一种补丁,不如 QUIC 针对性的设计来得明确清晰。
最后,就是正题,QUIC 如何实现多路流的流控,其实也很简单。QUIC 将 Max Data Frame 和 Blocked Frame 都扩充一下,分别支持 QUIC Connection 和 QUIC Stream,这样 QUIC Connection 和 QUIC Stream 都各种享有自己的流控。另外,QUIC 在一开始的握手中,会通过 TLS 1.3 的扩展中携带 Transport Parameter 信息,这里面会提前协商好所有的流控信息。
编码细节
接收缓冲区的设计
目前的实现,并不是我最喜欢的,甚至有些极端情况还会有 Bug(注释里面已经标注了),不过考虑我后面会直接使用 Rust async 生态来重新实现,这里只是一个简单的临时方案罢了。接收缓冲区的设计,本质上这是一个滑动窗口的算法题,应用层可能会不断地调用 QUIC stream recv 来消费接收缓冲区里面数据,移动窗口左边的边界。而对端过来的 QUIC stream frame 则是不断填充接收缓冲区的数据,移动窗口右侧的边界。
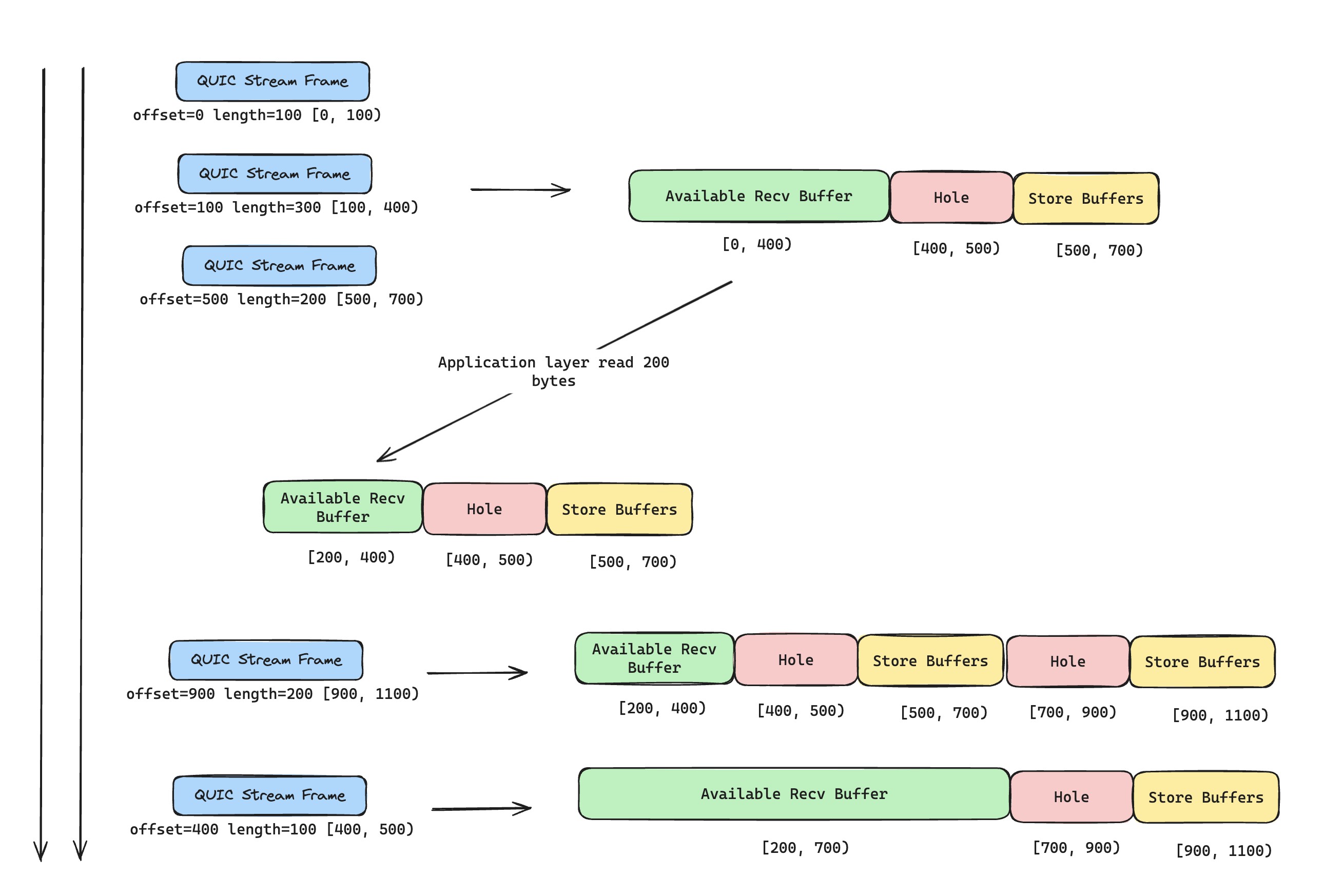
在这里,stream frame 可能是会出现乱序的情况,所以我们需要严格根据 stream offset 来确保右侧边界是被正确更新的。另外,我们还要高效的缓存暂时用不上的乱序数据,确保一旦空洞数据被填充之后,能够合并数据,正确的抛给上层处理。我可能更喜欢用空间换时间的做法,按照接收到的最大序列号(考虑到流控的限制,这里不会浪费太多的空间),来申请足够多的缓冲区空间,如果有空洞,也让缓冲区闲置着,直到真正收到数据后,再去填充缓冲区的空间。这么做,虽然会有一些内存的浪费,但是效率会高一些。不过,我现在用的是更简单的办法,缓存不连续的数据以及对应 offset,等待新的 stream frame 到来,如果数据连续,就移动滑动窗口右侧。
QUIC Stream 实现注意事项
流优先级实现细节
上文已经提及了 QUIC 多路流复用方案在优先级控制上的独特优势。但是在真正实现 QUIC 流优先级的时候,又存在很多需要注意的地方。我们可以先简化问题,当 QUIC Stream 之间不存在优先级的时候, QUIC 被允许发送数据(比如获取了新的拥塞窗口),需要去消费各个 QUIC Stream 的发送队列,应该如何消费?
可能第一反应,就是 Round Robin 这样的策略,均衡的把发送窗口分配给每一个可以发送数据的 QUIC Stream。当然,这里还有一个特别需要注意的地方,确保同一个 UDP Datagram 尽可能承载相同 QUIC Stream 的 QUIC Stream Frame,这样也可以减轻 HOL Blocking 问题的程度。毕竟已经从设计上将不同的 QUIC Stream 区分开了,没有必要在发送数据的时候,又绑死在一起。不过在待发送数据量小的时候,不需要特别严格的遵守,尽可能充分的利用每一个 UDP Datagram,确保传输效率,也是很重要的。
但是,如果 QUIC Stream 需要区分优先级,QUIC RFC 中是建议 QUIC 库在实现的时候,给用户提供一些优先级调整的接口。而 QUIC 流优先级的用户接口是什么样的,最简单的,就是用户可以调整设置 QUIC Stream 的优先级,就像 Linux 上面给进程设置 nice 值那样。
QUIC 协议栈通过应用层的主动设置,明确了各个 QUIC Stream 的优先级,现在压力都来到了 QUIC 协议栈这边,怎么才能根据不同优先级,做好发送窗口的调度,分配给不同的 QUIC Stream 呢?这个场景有点像操作系统调度算法面临的问题(效率和公平),既希望高优先级的 QUIC Stream 获得足够多的发送窗口,又不想过于影响低优先级的 QUIC Stream 发送运行。最后,因为我还没实现拥塞机制,所以在消费 QUIC Stream 发送队列的时候,只是实现了简单的 Round Robin 策略😁。
流控细节
这里,最让我有点头昏脑涨的,无疑就是在 QUIC 连接刚建立的时候,协商了好多流控的配置。除了上面提到的接收窗口大小,还有 QUIC 单向流和双向流创建个数限制等等。我每次在处理这些配置,就把一句话铭记于心,永远是接收方来声明自己的相关限制,所以作为发送方,要考虑的限制参数一定要是来自于对端发过来的。这样理顺了的话,配置处理上就不会乱,确保各种发送时考虑限制和接收时校验限制情况是正确的(真的正确吗,后续还得再加点测试)。
集成测试设计
之前就提到过,feather-quic 急需补齐自动化测试,毕竟编写一个协议栈太麻烦了,虽然有 RFC 的指导,但是细节太多了,没有足够多的测试,是很难保证项目质量的。
首先,我调整了项目的结构,把 QUIC 协议栈实现给单独抽成了一个 crate(feather-quic-core),然后再新增一个 crate(feather-quic-tools) 来维护一个基于 feather-quic 协议栈而实现的客户端工具,最后就是一个单独的自动化测试 crate(feather-quic-integration-tests)。这样的话,整个项目看起来清爽很多,终于有点正规军的感觉了。
接下来,就是编写自动化测试了,一方面考虑到我没有在协议栈里面实现 server 的部分,另外一方面考虑是我不能用两个臭棋篓子互相下棋的方式,去校验 feather-quic 协议栈实现的正确性,至少是好几个版本的迭代之后,feather-quic 协议栈才能互为 client 和 server,进行相互之间的测试。所以,现在我是使用了 quinn 来快速编写了一个 QUIC 服务器,然后用基于 feather-quic 编写的客户端,去进行一些类似于 echo 或者大数据传输的自动化测试,并且里面添加了一些丢包乱序的模拟测试,确保我之前开发的功能整体上是可用的。非常符合我预期的一点是,在测试过程中,发现了好多愚蠢的 bug 😂。但好消息是,一旦有了这些的自动化测试,并且不断的去新增和维护这个自动化测试集,这个项目的质量至少会有一个下限了。
尾声
在实现这几个功能的时候,倒是没有太多波澜,可能相对比较简单,唯一值得一提的就是,我在进行项目结构调整和编写集成测试的使用,使用了大量 AI 工具来辅助我生成代码。这里点名表扬 cursor 工具,非常智能和好用,特别是对项目上下文的理解能力,以及生成代码自动插入和显示 diff 的使用体验,真的是吊锤 copilot。不能理解,copilot 为什么会在这种核心使用交互体验上落后了一大截。珠玉在前,就是硬抄也不难吧,难道是大公司病,还是说我现在使用公司提供的 copilot 版本功能被阉割了?另外,让我比较想吐槽的一点是,copilot 对 vim 支持力度也不太够,甚至连 copilot chat 这种核心功能都不能支持,这让我怀疑微软这么做,是出于一些商业上的考量。还好 vim 社区足够的活跃,相关增强的 AI 插件可以说是琳琅满目。
接着我想简单聊聊 AI 编程,最近一两年这是一个非常热门的话题,原因很简单,因为 AI 编程确实可以极大的提升程序员的效率。但是,AI 编程的效率提升是存在边际效应的,在项目复杂了之后,快速生成的代码需要更严格的 review 和测试,才能避免引入更多的问题,效率并不是像之前预期的那样可以提升那么多了。我觉得这某种程度上,表明了 AI 编程特别适合去完成确定性的工作。如果你很确定功能实现的细节,你只是需要 AI 编程节约你自己去实现的时间,那么 AI 编程会极大的提升你的效率。举一个简单的例子,就是代码重构优化,很多人不去做的很大一部分原因,就是比较浪费时间,在 AI 的帮助下,这部分时间是可以被节约下来的。我这次项目结构优化调整,就基本是 cursor 做的,我只是描述了我的想法。所以,我在和 AI 结对编程的路上,很多时候就主要负责两件事情,搞清楚功能和架构究竟应该怎么运转,以及负责排查为什么代码没有按照预期运行。
最后,老规矩,放上相关 pr 地址。下一篇 QUIC 相关的博客,我计划是完成 QUIC 挥手,这样的话,feather-quic QUIC 协议栈的基础功能就差不多算完成了✿✿ヽ(°▽°)ノ✿。