用 Rust 从零开始写 QUIC:Runtime
为 feather-quic 选择一个合适的 runtime
feather-quic 的 runtime 选择
QUIC 协议栈需要什么底层能力
首先,在实现 QUIC 协议栈之前,我们需要弄清楚 QUIC 协议栈需要哪些底层能力,才能像 TCP 那样实现面向链接、可靠和流式这些核心能力。从下面的图中,我们可以看到 QUIC 基于 UDP 协议实现,QUIC 依赖于 UDP 协议提供的数据报文读写能力,当然这个是最基础的,没有它,QUIC 就相当于无根之水。
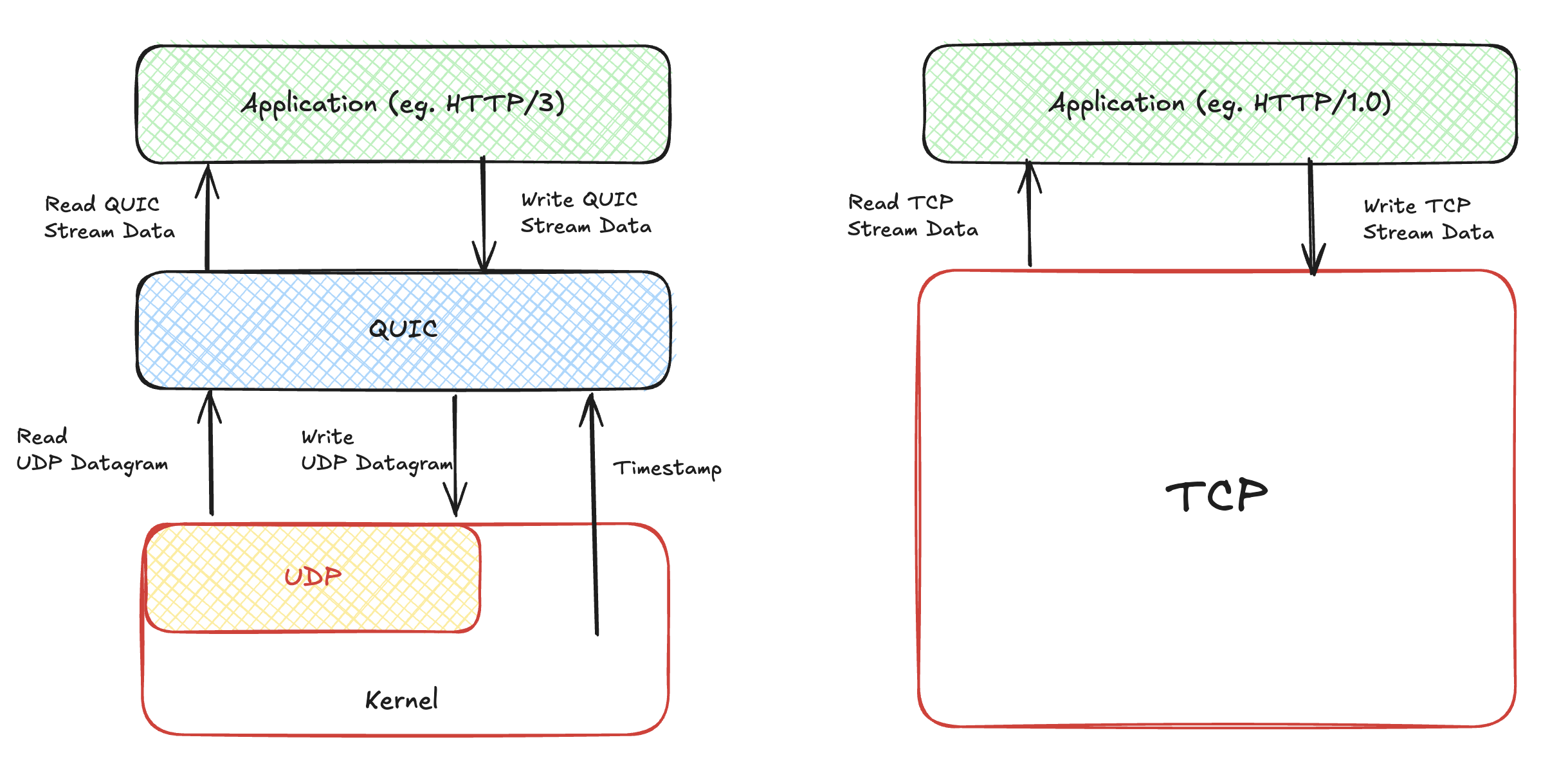
其次,我们可以看到,QUIC 协议栈需要底层提供时间驱动。这个也很好理解,我们都清楚 TCP 协议栈其实实现了很多定时器,比如 ack 机制中需要的重传定时器,如果设置了 keepalive 选项,那么 TCP 内部会启用保活定时器,再比如 TCP 挥手的时候,大名鼎鼎的 time-wait 定时器。在某种程度上,QUIC 是把 TCP 的各种工作更好的完成了一遍,或者说是没有历史负担的完成了一遍。所以,QUIC 协议栈的实现,也是必然需要时间戳的注入,来帮助它实现各种各样的定时器,最终实现各种核心功能。
可以补充的一点是,QUIC 是跑在用户态空间,而 TCP 是实现在内核态空间,这也是很多人愿意选择基于 UDP 传输协议的原因,跑在用户态意味着可以更加便捷的迭代,更好的掌控传输协议运行,而不是受限于内核升级。
究竟什么是 runtime
可能是我孤陋寡闻,runtime 感觉好像是最近几年才听到的比较多,大家喜欢这么喊,我也很喜欢这个名字,感觉就程序代码仿佛有了生命。我是这么理解的,runtime 一般多是指编程语言特别是虚拟机的运行时态,而现在网络编程中也喜欢使用 runtime 来描述包括事件循环、I/O 驱动、定时器等等的网络框架,甚至更复杂的 runtime 还会支持多任务调度。但在这篇博客中,runtime 更特指是网络编程中负责事件循环和时间驱动的引擎。举个例子,用 c 编写的 libevent 是 runtime,NGINX 和 Redis 这种自己实现了底层网络库的,也就相当于自己实现了自己的 runtime。
在我刚接触网络编程的时候,看的是 《UNIX 网络编程》,上面写的很清楚是网络 I/O 模型,一般有阻塞 I/O、非阻塞 I/O 以及 I/O 复用,当然现在在 Linux 平台上还有了真正的异步 I/O 模型:io-uring。并且,理论上网络编程也可以享受到 io-uring 完全异步实现带来的性能提升。而针对这么多网络 I/O 模型,一般 runtime 会提供两大类使用方式给开发者,来帮忙完成他们的网络相关应用。
第一种是,Reactor 和 Preactor 这样的异步事件驱动模型,这种也是我最早接触网络编程时候,就知道的,一般都是通过 I/O 多路复用(比如说 epoll)再加上非阻塞 I/O 实现的,libevent 就是这样经典的实现。用户只需要关注好读写事件,从非阻塞的 socket 中读写自己需要的数据,进行处理即可。当然,异步 I/O 也可以实现这样的异步事件驱动模型,后者的 Preactor,也是让用户通过回调的方式,来处理读写事件,稍微有一点区别,在于基于 异步 I/O 的话,开发者一般需要提前准备好用户态的读写缓冲区,当读写事件触发的时候,已经不需要真正执行读写操作了,只需要处理后续开发者自己关心的业务逻辑。当然,这一套开发模式经典,但是存在一个很大的弊端,就是开发复杂的系统时候,异步回调的编程模型,会给人带来很大的心智负担(至少是给我带来了不小的心智负担😂)。
所以,我们有了第二种 runtime 的使用方式,runtime 在内部结合协程,来将异步事件模型给掩盖住,让开发者可以使用async & await 网络编程的方式开发代码,同时也能享受到异步事件驱动的高性能优势。这种模式,我刚工作时候,接触到的 OpenResty 就是这样实现的,利用 lua 实现的有栈协程,再结合 NGINX 的事件驱动,提供了同步网络编程的体验。当然,在 Rust 生态中,大名鼎鼎的 tokio 也是基于 Rust 的无栈协程,以及 mio 事件驱动网络库,来提供了类似的效果。
feather-quic 的选择
在这里,基于 Rust 生态,我们基本上有 mio 和 tokio 两种选择,来编写我们的 QUIC 协议栈,毫无疑问,使用 tokio 的话,心智负担会小一些,可以减少各种异步回调的使用,状态机的管理。
但是我不太想选择 tokio,因为对我而言 QUIC 协议栈也是 runtime 的一部分,如果使用 tokio,我希望不仅仅是我在开发 feather-quic 的时候,享受到 async/await 便利。我希望开发者在使用 feather-quic 的时候,也能享受到类似 tokio 提供 async/await 的便利,但这意味着我需要花更多的时间将 feather-quic 更好的集成在 tokio 中,不仅仅只是使用 tokio 提供的 async udp socket 进行编程,然后提供一些 QUIC callback 回调来给开发者使用。
而我目前更希望把集中精力在 QUIC 协议栈的编写上,也许后面我完成了 QUIC 协议栈基础功能的编写之后,我会专门抽出时间,来将 feather-quic 真正集成在 tokio 里面,这也是我去熟悉 tokio 各种细节的一个契机。
所以,我这里选择了 mio 网络库,考虑到我们只是计划实现一个 QUIC 客户端,相对更简单一些,甚至我在这个实现里面,都没有使用异步回调,而是直接在 mio 读写事件触发的地方,直接插入了相关逻辑的编写(相关 code 改动)
编码中一些有意思的细节
UDP socket
首先 UDP socket 的创建其实就有不少细节,一般使用 UDP 编程,很多人会倾向于直接创建一个 UDP socket,然后使用 sendto 和 recvfrom 来收取数据,在参数中添加目标地址的方式,来确定 UDP 数据报文的去向和来路。我个人比较喜欢通过 bind 和 connect 系统调用的方式,给 UDP socket 的内核数据结构 sk 设置好四元组,这样的话,我们可以直接对 UDP socket 进行 recv 和 send,Linux 内核会根据 UDP datagram 的四元组,来精准找到我们的 UDP socket,可以让代码更简洁一些。
当然这个使用方法在一些特殊场景可能会存在一些坑,比如说,如果网络发生了切换(比如从 wifi 切换到了有线网络),作为客户端,我们必须弃用原来 bind 和 connect 的 socket,再重新创建一个新的 UDP socket,确保能够正常发送数据,这个技术方案的细节会在后面实现 QUIC 连接迁移的时候再说。
再比如说,服务端如果对每个新的 QUIC 请求,都采用创建新的 UDP socket,另外通过 bind 和 connect 设置底层四元组的方式,在高并发的情况下,很容易让 Linux 内核中的 UDP 2-tuple 哈希表(基于本地地址和本地端口为 key)性能退化到链表,当我在写这个的时候,我又去翻了下 Linux 的代码,发现就在不久之前,UDP 哈希表被优化成了 4-tuple (code change)。所以可以预见的是, UDP connected socket 的问题又少了一个,我们不需要依赖 eBPF 或者 Linux 补丁的方式去做针对性的优化。另外,服务端的 UDP 热更新也是个难题,Linux 内核很难知道 UDP 的流量应该分配到旧服务上的 UDP socket,还是新服务的 UDP socket,毕竟 UDP 没有链接的概念,像 NGINX 是引入了 ebpf 来辅助处理这个问题。(上述问题如果细聊的话,可能战线会拉的很长,我计划在后面实现 QUIC 连接迁移的时候,再更详细的描述这些技术细节)
还有一个有意思的地方,就是我们在进行 TCP 网络编程的时候,都会知道,如果大量往 TCP 非阻塞 socket 进行写入操作,如果网络较差的情况下,很容易出现 TCP 协议栈发送队列被撑满的情况,导致我们在写入的时候,返回 EAGAIN 的 errno 错误码。但是 UDP 协议上是应该没有发送队列的存在,理论上写入 UDP socket 的数据,应该立刻被转交给 IP 网络层处理。所以,问题来了,我们需要处理 UDP socket send 时候,可能返回的 EAGAIN 错误吗?
实际上是需要的,虽然 UDP 设计上没有发送队列的存在,但是 Linux 内核 sk 是有 sk_write_queue 存在的,所以 sk_write_queue 如果被耗尽,那么在 sock_alloc_send_pskb 中,没有成功创建出 send skb,那么就会返回 EAGAIN 错误。sk_write_queue 的长度上限,其实就是大家平时熟悉的 socket SO_SNDBUF 的值,最极端的情况,可以通过 setsockopt 将我们 UDP 非阻塞 socket SO_SNDBUF 设置的足够小,比如 4096 字节,然后发送一个超过 4096 字节大小的 UDP 数据报文,就会出现 EAGAIN 错误码。
定时器的实现
mio 本质只提供了 UDP 读写事件的注册,并没有我们需要的定时器事件,所以我们需要自己动手来简单实现一个定时器。这个其实并不困难,特别是我们只需要一个定时器,我们甚至不需要像通用的网络库那样,考虑用什么样的数据结构来管理多个定时器。以 Linux 的 epoll 举例,基于 epoll 实现的网络库,实现定时器的时候,一般是利用 epoll_wait 提供的超时参数,但是这个超时参数有一个缺点是只支持毫秒级别,对于协议栈,我们可能会更希望拥有更精确的超时定时器。
libevent 的实现,已经给我们提供了答案,一般来说,我们会使用 epoll_pwait2,这个系统调用提供了纳秒级别超时参数,当然需要比较新的 Linux 内核版本。如果 Linux 内核版本不支持,我们会选择使用 timerfd,这也是通用的解决方案,设置好高精度的超时,将 timerfd 注册到 epoll 事件中,我们就可以获得一个更精准的定时器。
考虑到 mio 没有支持定时器实现,我更倾向使用 timerfd 的方式,我在 Rust 社区里面很轻松就找到了我需要的基于 timerfd 给 mio 做了定时器支持的 crate(mio-timerfd)。但是,我也遇到了一个很烦人的编译报错,具体如下。
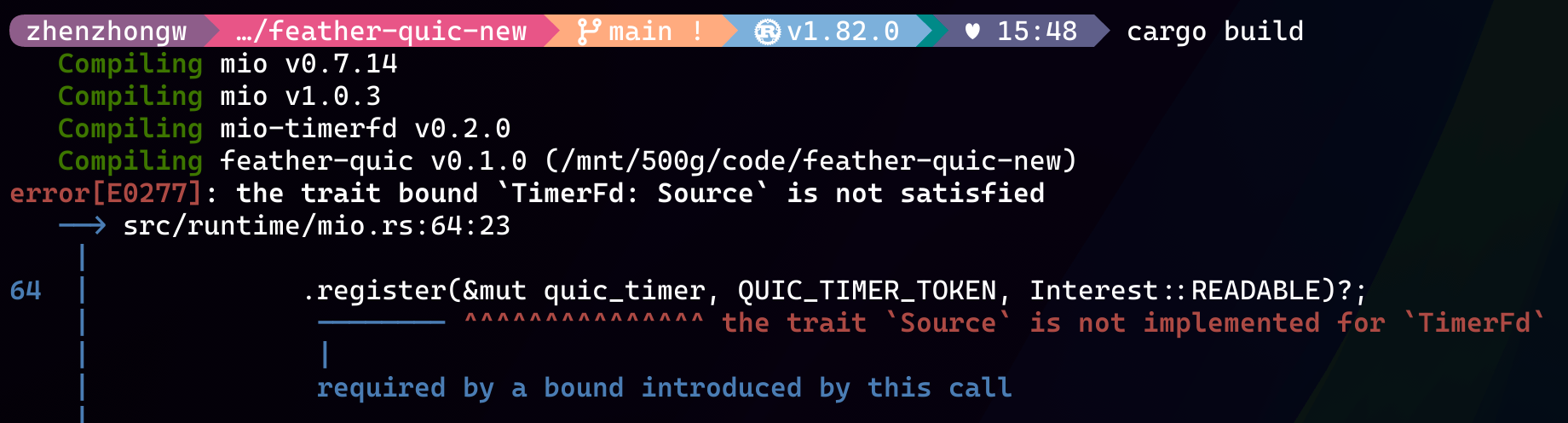
不得不说,Rust 编译器提示是非常友好的,这也是我非常喜欢 Rust 的原因之一。但是,我在这里确实遇到了一些问题,编译器提示我 mio-timerfd 没有实现 mio 中定义的 Source trait,但是我仔细看了一下 mio-timerfd 的源码,里面确实实现了 Source trait。
这个让我一时间有点困惑,由于我对 Rust 也是新手,我就按照我原来 c/c++ 排查的思路,直接在 Rust target 目录下面,使用 nm 命令来比对编译生成的函数符号。虽然 Rust 有自己的 mangling 的特殊规则,但是并不妨碍我很快找到 Source trait 的函数实现定义可能会映射的符号字段,比如包含 mio..event..source..Source$GT$10deregister 的符号,就是实现了 Source trait 中的 deregister 函数。
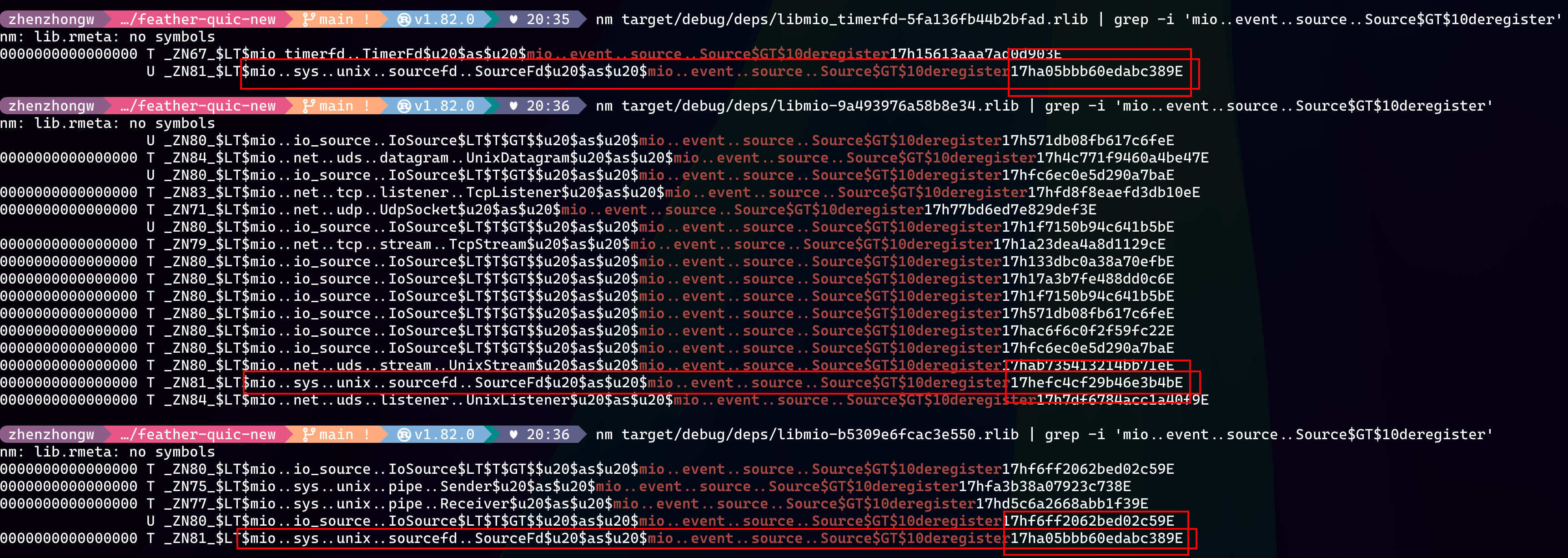
其实,当我看到有两个 mio 的 rlib 的时候,我心里就犯嘀咕了,八成是依赖 mio 的版本不一致导致的。然后 nm 扫出来的符号,也佐证了这一点,上图中的 sourcefd 实现 Source trait 的符号,在两个 mio 中完全不一样。然后,我 Google 了一下,发现 cargo tree 也能帮助我快速发现这个 mio 的依赖问题。解决方案也很简单,我 fork 一个 mio-timerfd 兼容适配下最新版的 mio 就可以了。
虽然我在这里遇到了一些问题,但是不得不说 cargo 在解决这种依赖同一个库的不同版本的情况,有着独到之处,如果一个项目不小心引用了同一个库的不同版本,cargo 也会确保每个版本都有独立的符号,如果不匹配,编译时期也很容易暴露出问题。如果是传统 c/c++ 项目,库的不同版本会共享相同的符号,使用哪个版本的库全都依赖链接器的查找符号顺序,而这种依赖非常脆弱,很容易埋坑,所以 Rust 的显式哲学确实可以提前规避问题,我给自己加一个 TODO 事项:希望日后能专门找时间能再深入学习下 Rust 编译的一些细节和设计。
io-uring 尝试
文章开始的时候,提及了异步 I/O 模型,在 Linux 平台上自然就是 io-uring,我很早的时候就听说了 io-uring 的大名,但是以前一直没有机会尝试,这次机会正好试试水,用 io-uring 实现个最简单的异步回调网络库,也就是 Preactor 网络模型。
简单的查阅了一些资料,发现 io-uring 在文件 I/O 上是一个非常好的解决方案,但是在网络 I/O 上面,似乎还是存在一些争议。从原理上来说,io-uring 对比 epoll 主要优化是减少了系统调用的数量,当然大量的系统调用代表着频繁的上下文切换,对性能的影响毋庸置疑,所以 io-uring 理论上是要比 epoll 会好一些的。
选择阻塞还是非阻塞 socket
我在尝试的过程中,第一个疑问便立刻到来,是否需要将 socket 设置成非阻塞模式。从原理上来说,似乎 socket 设不设置成非阻塞无伤大雅,因为读取和写入的操作都是在内核态由 io-uring 完成,用户态只需要 sumbit_and_wait 即可。但是,我更想知道的是内核态 io-uring 会因为 socket 阻塞或者非阻塞,在性能上有所差异吗,再具体点就是,在高并发的场景下,socket 没有设置成非阻塞,会影响内核态 io-uring 的性能吗。这样的疑问,感觉我得跑去查看 io-uring 的实现代码,才能解答困惑。
如何正确的订阅异步读事件
还有一个就是,当我在开发的时候,我在 submit read 异步的事件时候发现,我似乎有两种选择。一种是每次只注册一个 read 异步事件,然后等待 read 完成事件,处理完我的应用层逻辑之后,再注册 read 异步事件。第二个选择是,一口气注册多个 read 异步事件,然后依次等待 read 完成事件的到来。本能上,我肯定不会选择前者,因为 io-uring 优势就是在于减少系统调用的次数,现实世界中,数据可能大量到来,多次 read 事件同时发生才是常态。而后者的使用,也让我感觉有点别扭。于是我努力翻阅相关文档,找到了 Multi-shot 的功能,这个让我可以只在 Submission queue 上注册一个事件,但是可以等待到我指定数目的 read 完成事件到来,这才让我感觉好了一点。
永远不要忽视 Rust unsafe 代码
在开发的过程中,我使用了 Rust 的 io-uring crate,我在里面也遇到个蛋疼的问题。我在实现 Timer opcode 的时候,发现 timer 没有按照我的预期触发,这个让我有点苦恼,考虑到 io-uring 的接口都很简单,系统调用也少之又少,主要都是对共享内存中的 Submission Queue 和 Completion Queue 进行操作,并且我对 io-uring 的底层实现细节基本一无所知,所以我一时间很难有好的办法,来判断问题究竟出在哪里。难道,只能去硬翻 io-uring 的实现代码了吗,我只是想简单使用一下 io-uring,并不是想在这篇博客里面分享 io-uring 的实现细节。
在硬翻源码之前,我做了一个最后的尝试,最小场景复现我的 case,让我能够排除其他干扰去排查根因,不得不说这招虽然笨,但是管用。当我看到 Timer opcode 持有的时间戳参数居然是我调用时候创建时间戳的内存地址,而不是 Timer opcode 自己内存重新拷贝的,我像触电一样,瞬间明白了原因。
我的时间戳参数变量是一个栈变量,它的生命周期在 add_timer 函数退出后,就结束了。因为 Submission Queue 的 push 操作是 unsafe 的,所以 Rust 编译器也不会提示我生命周期的错误。这让我开始反思,我可能有点习惯于 Rust 生命周期的编译校验,甚至遇到 unsafe 的时候,都没有太多的警觉,想当然以为库内部实现的时候,会把栈变量的值给拷贝走。如果是 c 代码实现的话,我肯定是第一时间考虑传入参数的生命周期问题,Rust 的安全性让我在写 Rust 的时候都基本很少考虑这些问题,反正最后编译器会提示我的。所以,作为一个 Rust 新手,这次我得到的教训就是,需要时刻对 Rust unsafe 的代码保持警惕。
io-uring 使用感受
从开发使用的体感上,我的感受是使用 io-uring 不是很难,但是想把 io-uring 用好,需要的不仅仅只是对 io-uring 原理的简单了解,得花上一些时间在 io-uring 的实现细节上反复推敲,外加研究和参考基于 io-uring 的相对成熟三方库。比如说,我现在依旧不清楚,是否应该或者说是否可以在网络 I/O 上面尝试 kernel-polled 的驱动模型和零拷贝。这也许也是为什么之前有很多争论 io-uring 在网络 I/O 性能的帖子(比如说 Yet another comparison between io_uring and epoll on network performance)。另外还有一个帖子 io_uring is slower than epoll, 我喜欢这个帖子的讨论氛围,让我回忆起了我的第一份工作 😈。我想,后续如果有时间,我会投入一些精力在 io-uring 的实现细节上,回头再完善优化下现在的代码,同时也尝试做一下性能的对比测试。
结尾
最后我用 runtime 这个分支开发了我的本文中提及的全部改动,这里是 runtime code,接下来就是开始去实现 QUIC 的握手了。