Implementing QUIC from Scratch with Rust: Runtime
Runtime Choice for Feather-QUIC
What Does a QUIC Protocol Stack Need at Its Core?
Before implementing the QUIC protocol stack, it's crucial to understand what foundational capabilities it needs to achieve core functionalities like connection orientation, reliability, and streaming, similar to TCP. From the diagram below, we can see that QUIC is built on UDP. QUIC depends on UDP for basic datagram read-write capabilities. Without this foundation, QUIC would have nothing to stand on.
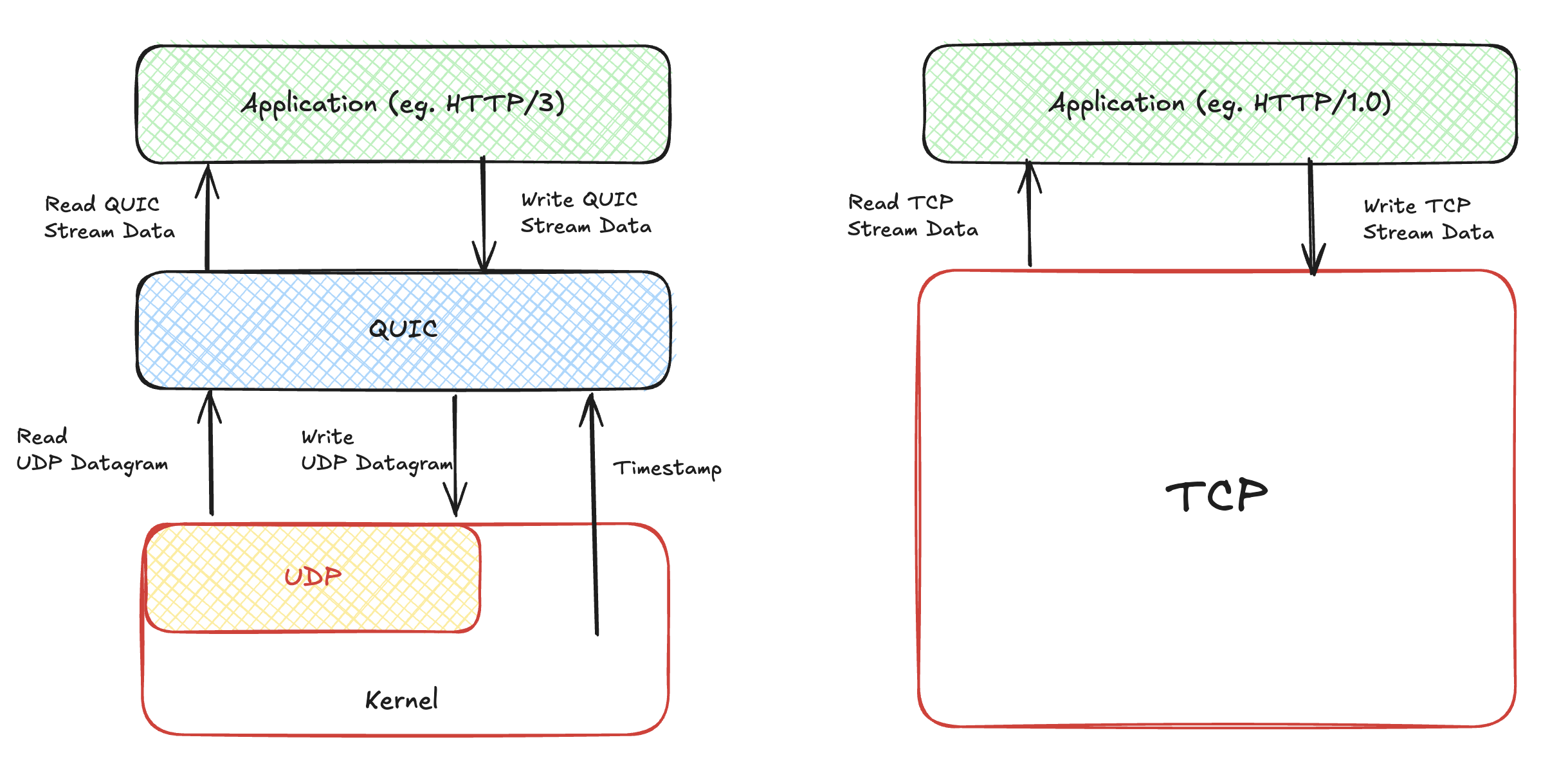
Additionally, the QUIC protocol stack requires time-driven operations. This is intuitive because TCP stacks implement numerous timers, such as retransmission timers for acknowledgment mechanisms, keepalive timers (if keepalive is enabled), and the infamous time-wait timer during connection termination. QUIC essentially takes these mechanisms and refines them, free from legacy constraints. Consequently, the implementation of the QUIC protocol stack also relies on timestamps to enable various timers, which ultimately power its core functionalities.
One notable point is that QUIC operates in user space, while TCP operates in kernel space. This distinction is a key reason many prefer QUIC; user-space operation allows for more agile iterations without being constrained by kernel updates.
What Exactly Is a Runtime?
Perhaps it's just me, but the term "runtime" seems to have gained popularity in recent years. I find the term appealing—it gives the impression that program code has a life of its own. I understand runtime as the execution environment, typically for a programming language or virtual machine. In network programming, runtime often describes frameworks for event loops, I/O drivers, timers, and more. Complex runtimes might even support multitasking. For example, in my opinion, libevent written in C is a runtime, as are systems like NGINX and Redis, which implement their own networking libraries.
When I first encountered network programming, I learned about the network I/O models from UNIX Network Programming. It detailed models such as blocking I/O, non-blocking I/O, and I/O multiplexing. On Linux, there is now true asynchronous I/O (io_uring), which network programming can benefit from. Runtimes generally offer two ways to handle these network I/O models to help developers build their applications.
The first is asynchronous event-driven models like Reactor and Preactor. These are typically implemented using I/O multiplexing (e.g., epoll) combined with non-blocking I/O, as in the classic libevent. Developers focus on read and write events, handling data from non-blocking sockets as needed. While asynchronous I/O can also enable event-driven models, Preactor introduces a slight variation. It typically requires developers to prepare user-space buffers for read/write operations in advance. Upon an event trigger, only the application logic is handled, without performing actual I/O operations. Although this model is classic, it has a significant drawback: managing callbacks can become a cognitive burden when developing complex systems.
This led to the second runtime usage pattern. Modern runtimes often integrate coroutines to abstract away asynchronous event models, allowing developers to write in a synchronous programming style while still enjoying the performance benefits of event-driven systems. For example, OpenResty achieves this using stackful coroutines in Lua combined with NGINX's event-driven architecture. Similarly, in the Rust ecosystem, the renowned tokio uses stackless coroutines and the mio event-driven library to provide a similar experience.
Feather-QUIC's Choice
In the Rust ecosystem, we have two main options for implementing our QUIC protocol stack: mio and tokio. Using tokio would reduce cognitive load, minimizing the use of asynchronous callbacks and simplifying state machine management.
However, I chose not to use tokio. For me, the QUIC protocol stack is itself part of the runtime. If I use tokio, I would want developers using feather-quic to also benefit from tokio. This would require extra effort to integrate feather-quic seamlessly into tokio, beyond just using its synchronous-style UDP socket API. At this stage, I want to focus on implementing the QUIC protocol stack itself. Perhaps after completing the basic functionality of the stack, I'll take the time to integrate feather-quic into tokio, which will also be an opportunity to deepen my understanding of tokio.
For now, I've chosen the mio library. Given that we only plan to implement a QUIC client, the task is relatively simpler. In fact, my implementation doesn't use asynchronous callbacks. Instead, logic is directly embedded at the points where mio triggers read/write events (related code change).
Interesting Details in the Code
UDP Socket
The creation of a UDP socket itself involves various considerations. Many developers use sendto and recvfrom to send/receive datagrams, specifying the target address in the parameters. Personally, I prefer using bind and connect system calls to set up the quadruple (four-tuple) in the UDP socket's kernel structure. This allows us to use recv and send directly, with the Linux kernel matching the quadruple for precise socket identification, simplifying the code.
This approach has some caveats. For instance, if the network changes (e.g., switching from Wi-Fi to Ethernet), the client must discard the old bind and connect socket and create a new one. This detail will be revisited when implementing QUIC Migration. Additionally, creating a new UDP socket for every QUIC request on the server side can lead to hash table degradation in the Linux kernel, especially under high concurrency. However, a recent optimization in Linux upgraded the UDP hash table from two-tuple to four-tuple (code change), mitigating this issue. Server-side UDP hot upgrades are tough for the same reason: the kernel does not know whether a packet should land on the sockets owned by the old process or the freshly started one because UDP has no concept of connections. Projects such as NGINX solve this by pulling in eBPF helpers. I will dive deeper into these problems when I later write about QUIC connection migration.
Another interesting aspect is this: when programming with TCP, we often know that if we write extensively to a non-blocking TCP socket under poor network conditions, the TCP stack's send queue can easily fill up. This results in a EAGAIN error code when attempting to write. However, with UDP, there theoretically shouldn't be a send queue, and data written to a UDP socket should be immediately handed over to the IP layer for processing. So, the question arises: should we handle the EAGAIN error that might occur when sending data through a UDP socket?
The answer is yes. Although UDP is designed without a send queue, the Linux kernel's socket structure (sk) does include a sk_write_queue. If the sk_write_queue is exhausted, the function sock_alloc_send_pskb may fail to allocate a send skb, resulting in a EAGAIN error. The maximum size of the sk_write_queue is determined by the socket's SO_SNDBUF value, which many developers are already familiar with. In extreme cases, you can use setsockopt to set the SO_SNDBUF of a non-blocking UDP socket to a small value, such as 4096 bytes. Then, if you try to send a UDP datagram larger than 4096 bytes, you will encounter the EAGAIN error code.
Implementation of Timers
The mio library essentially provides the ability to register UDP read and write events but does not include the timer events we need. Hence, we need to implement a simple timer ourselves. This task is not particularly challenging, especially since we only require a single timer. Unlike general-purpose networking libraries, we don't need to consider complex data structures to manage multiple timers.
For instance, when implementing timers with Linux's epoll, networking libraries typically use the timeout parameter provided by epoll_wait. However, this parameter has a limitation: it only supports millisecond-level precision. For protocol stacks, we often prefer timers with higher precision.
The implementation in libevent already provides a solution. Typically, we would use epoll_pwait2, which supports nanosecond-level precision, albeit requiring a relatively recent Linux kernel version. If the Linux kernel version does not support it, we can use timerfd, which is a more common solution. By setting a high-precision timeout and registering the timerfd with epoll, we can achieve a more accurate timer.
Since mio does not support timer implementation, I prefer using the timerfd approach. In the Rust ecosystem, I quickly found a crate that provides timer support for mio based on timerfd: mio-timerfd. However, I encountered an annoying compilation error, as shown below:
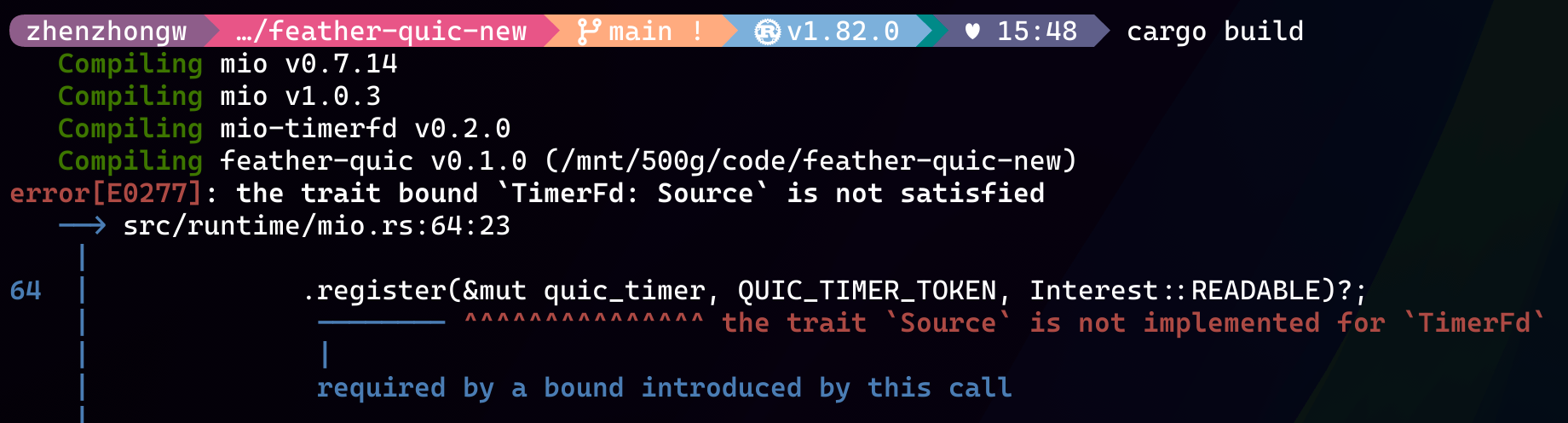
I have to say, Rust's compiler error messages are incredibly user-friendly, which is one of the reasons I love Rust. However, I encountered an issue here: the compiler indicated that mio-timerfd does not implement the Source trait defined in mio. But after inspecting the source code of mio-timerfd, it seemed that the Source trait was indeed implemented.
This left me momentarily puzzled. As a Rust beginner, I resorted to my usual C/C++ debugging approach: directly inspecting the Rust target directory and using the nm command to compare the compiled function symbols. Despite Rust's unique mangling rules, it didn't prevent me from quickly locating symbol fields that might correspond to the Source trait's function implementations. For instance, symbols containing mio..event..source..Source$GT$10deregister indicate the implementation of the deregister function within the Source trait.
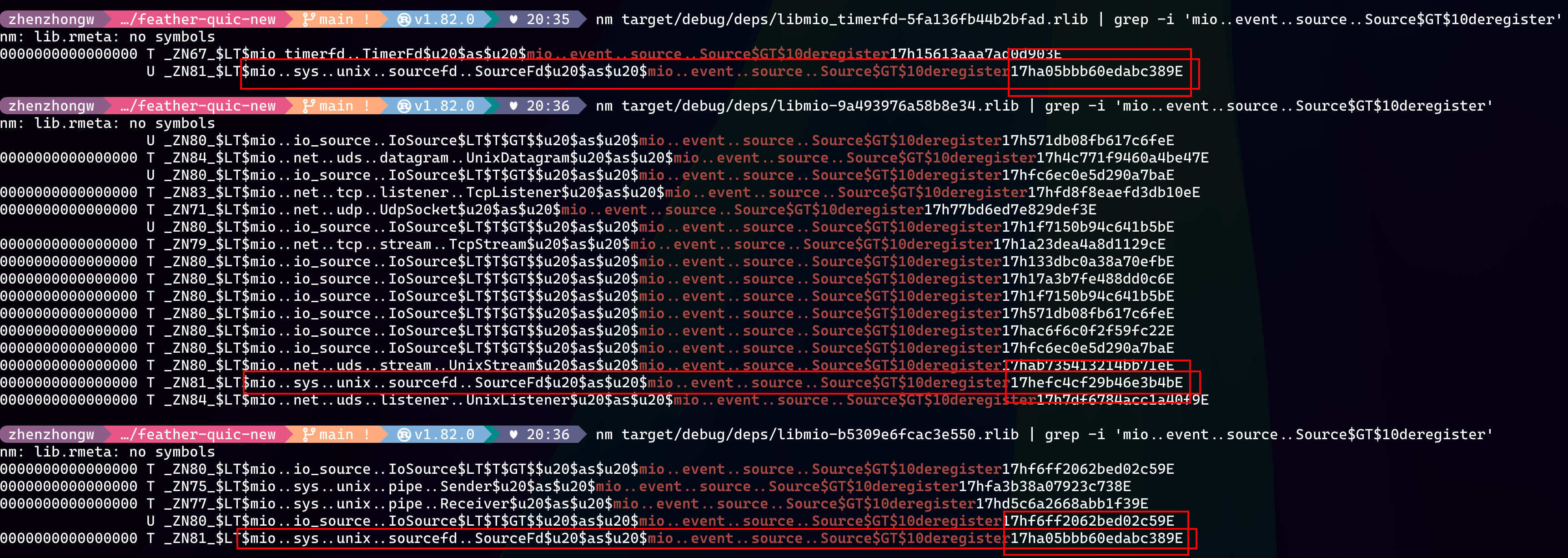
When I saw two mio rlibs in the output, I suspected that the issue was likely caused by inconsistent versions of mio dependencies. The nm output further confirmed this suspicion. As shown above, the symbols for the Source trait implementation in sourcefd differ between the two mio versions. A quick Google search revealed that the cargo tree command could help me quickly identify the dependency issue with mio. The solution was straightforward: fork mio-timerfd and adapt it to be compatible with the latest version of mio.
Although I encountered some challenges here, it's worth noting that Cargo handles such scenarios involving multiple versions of the same library remarkably well. If a project inadvertently includes different versions of the same library, Cargo ensures that each version has its own distinct symbols. Any mismatches are likely exposed during compilation. In contrast, traditional C/C++ projects often share the same symbols across library versions, with the linker determining which version to use based on symbol resolution order. This approach is fragile and prone to issues. Rust's explicit philosophy helps avoid such pitfalls early on. I'll add a TODO for myself: dedicate some time to study how the Rust build pipeline is put together, not just at the Cargo layer.
Exploring io-uring
At the beginning of this article, I mentioned the asynchronous I/O model, and naturally, on the Linux platform, it refers to io-uring. I’ve been hearing about the fame of io-uring for a long time but never had the opportunity to try it out. This time, I decided to dip my toes in and implement the simplest asynchronous callback-based networking library, following the Preactor network model.
After briefly consulting some resources, I found that io-uring is an excellent solution for file I/O. However, it seems to spark some debate when it comes to network I/O. Fundamentally, the main advantage of io-uring over epoll is the reduction in the number of system calls. Frequent system calls lead to context switching, which undeniably impacts performance. Thus, in theory, io-uring should outperform epoll.
Blocking vs Non-blocking Sockets
The first question arose almost immediately during my experimentation: should sockets be set to non-blocking mode? Conceptually, it seems irrelevant since both read and write operations are handled in kernel space by io-uring, and the user space only needs to call submit_and_wait. However, I’m curious if there’s a performance difference in kernel-space io-uring based on whether sockets are blocking or non-blocking, particularly in high-concurrency scenarios. Does leaving sockets in blocking mode impact the kernel’s io-uring performance? To answer this, I’d need to delve into the implementation of io-uring.
Single vs Multiple Submissions
Another issue arose during development when I tried to submit asynchronous read events. I seemed to have two options:
- Register a single read event at a time, wait for its completion, process my application logic, and then register another read event.
- Register multiple read events in one go and wait for their completion sequentially.
Instinctively, I would avoid the first approach, as io-uring is designed to reduce system calls. In real-world scenarios, data often arrives in bulk, and multiple read events happening simultaneously are more common. However, using the second approach felt somewhat awkward. After digging through the documentation, I discovered the Multi-shot feature. This allows registering a single event in the Submission queue while handling a specified number of read completion events. It felt like an elegant solution.
Always pay attention to Rust unsafe code
While using the Rust io-uring crate, I encountered an issue with the Timer opcode. The timer wasn’t triggering as expected, which was frustrating. Since io-uring’s interfaces are straightforward, involving only a few system calls, mainly operating on the shared memory Submission Queue and Completion Queue, I lacked a clear approach to debug the problem. Resorting to a brute-force method, I minimized my test case to reproduce the issue.
Eventually, I realized the Timer opcode held a timestamp parameter pointing to the memory address of a timestamp variable I created during the call. The Timer opcode did not copy this timestamp into its memory. The variable was a stack variable, and its lifetime ended when the add_timer function exited. Because the push operation for the Submission Queue is unsafe, the Rust compiler didn’t warn me about the lifetime issue.
This realization prompted me to reflect on how I’d grown reliant on Rust’s lifetime checks. In unsafe Rust, I hadn’t exercised the same caution I would have in C, where I would immediately question the lifetime of input parameters. Rust’s safety guarantees had led me to assume the compiler would catch such issues. As a Rust novice, this experience reminded me to stay vigilant when writing unsafe code.
Observations and Reflections
From a usability perspective, io-uring isn’t particularly challenging to use, but leveraging it effectively requires more than a superficial understanding of its principles. It demands time spent iterating over its implementation details and studying mature third-party libraries built upon it. For instance, I still don’t know whether—or how—I should explore kernel-polled driver models or zero-copy techniques for network I/O. This might explain the ongoing debates about io-uring’s network performance, such as Yet another comparison between io_uring and epoll on network performance and io_uring is slower than epoll—the tone in that second thread reminds me of my very first job.
When I have more time, I plan to delve deeper into the implementation details of io-uring, refine and optimize my current code, and conduct performance comparison tests.
Conclusion
I developed all the changes mentioned in this article on the runtime branch. Here’s the link to the runtime code. Now, it’s time to start implementing the QUIC handshake!